《小米超神》技术总监王啸予:重度MOBA的优化之路
- 作者:admin
- /
- 时间:2018年06月08日
- /
- 浏览:24101 次
- /
- 分类:厚积薄发
今天为大家分享的内容来自UWA DAY 2018技术大会上,嘉宾王啸予的演讲《重度MOBA的优化之路》。他重点分享了开发过程中遇到的各种技术问题以及对应的解决方案,包括:如何通过渲染到纹理的方法来降低一些UI的Draw Call;如何自行构建UI Mesh管理频繁移动的HUD和小地图的UI部分;如何优化UI界面中的粒子特效等,实用性较强,极具参考意义。
大家好,我是来自朱雀网络的王啸予,今天给大家分享我们在研发《小米超神》这款MOBA手游过程中遇到的各种问题及对应的解决方案。
每个游戏的优化侧重点和游戏类型紧密相关。比如MOBA游戏,地图相对固定且全部可见,具有固定视角;同时这类竞技性游戏对实时响应的要求较高,运行时的计算量比较大,类如寻路算法,这导致MOBA游戏不能做Level Streaming,必须整体加载;并且帧率平滑性需求要高于最大性能表现,我们需要尽量避免运行时加载资源,最好是全部预加载;最后,MOBA手游是CPU密集的。
本文主讲UI和场景:
关于UI:
1.动态图集;
2.自定义的UI Mesh;
3.UI与特效混排的方案。
关于场景:
1.不可见物体的优化;
2.Crowd渲染优化。
一、UI
1.动态图集
所谓动态图集就是没有办法静态生成的,需要在运行时动态生成的图集,那么我们为什么需要动态图集?
动态图集是为了解决游戏中动态图片太多的问题,也就是我们没有办法预先放在UI上的。下图案例中可以看到右下角的英雄技能图标、天赋技能图标,以及主动使用的物品图片,均为动态加载。左上角的英雄头像也是动态加载,而且由于技能之类的图片太多(毕竟有几十个英雄),所以没有办法打成一张静态图集。而如果作为独立图片动态加载,就会多十几个DrawCall。即便是打成多张静态图集,也会导致UI渲染的批次被打断。
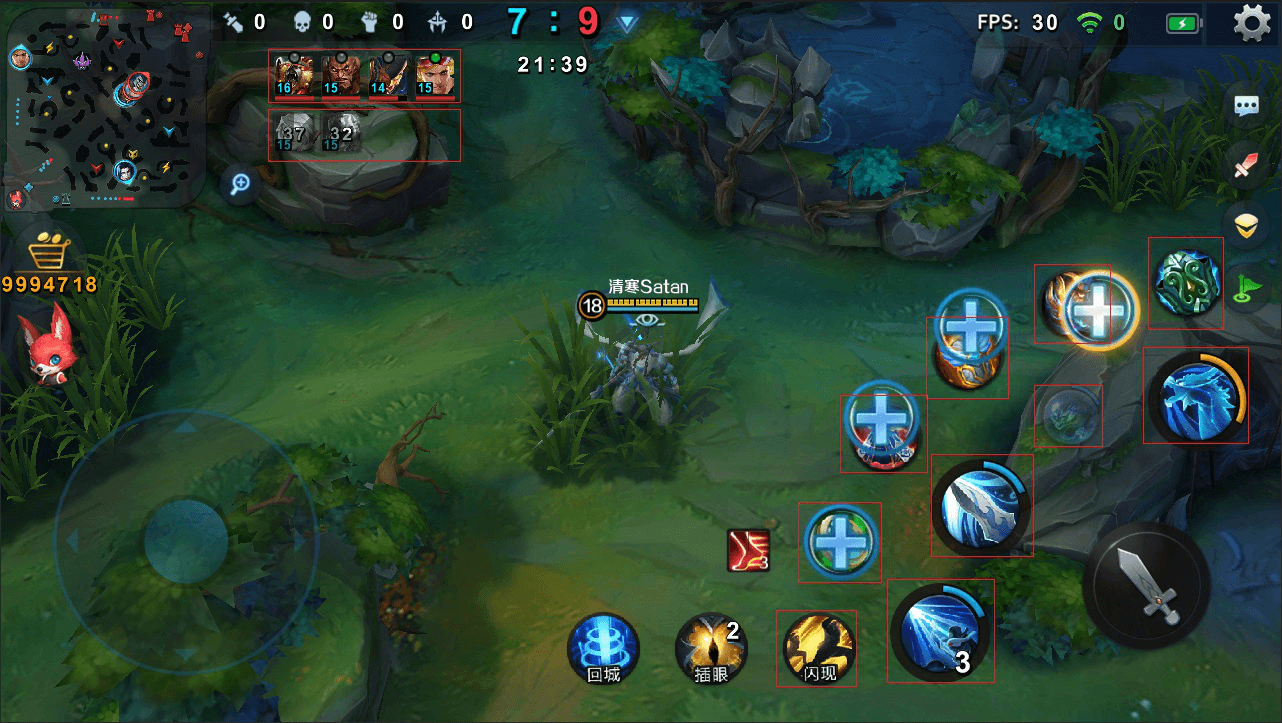
解决方案:用动态打图集的方式。因为我们没有Unity源码,所以图集的分块算法参考了这个开源项目 http://davikingcode.com/blog/unity-generate-spritesheets-at-runtime/,这个算法效率比较不错,建议大家可以研究一下,它的分块算法的思路上本质上类似于BSP。
下图是按解决方案打出来的动态图集。大图集是在游戏Loading时获得动态图片,然后把这些动态图片渲染到RenderTexture上,用GPU的方式来做可以保证加载的效率。在游戏中,英雄头像使用了一张256x256的RenderTexture,而英雄技能、天赋技能和物品图标使用了一张512x512的RenderTexture。这样一来,技能面板动态图标的消耗从12个DrawCall降低到1个DrawCall。而英雄头像部分,从最多9个DrawCall降低到2个DrawCall,这个结果是因为敌我双方英雄头像使用的材质不同。实际操作中,技能面板的动态图片放在同一个层级里,这样就只有1个DrawCall,上面的蒙板、边框零散图片打成静态图集,在不出现穿插的情况下,UGUI也会协助合批。因此通过这种方式大量减少了DrawCall。后面讲到的一些点其实也用到了动态图集。

2.自定义的UI Mesh
为什么需要自定义UI Mesh?正如UWA一直以来所说的那样,UI元素要做到动静分离。如果动态元素太多怎么办?《小米超神》中需要动态变化的UI元素非常多,如果使用UGUI来做会产生大量消耗,主要集中在SendWillRenderCanvases和BuildBatch两个函数,UGUI本身也会不断地去重建。
下图是游戏中的血条,密集的原因是因为每一波小兵有5个,夹杂着投石车。并且血条是始终显示的,有些游戏中只有血量不满的时候才会显示,但是《小米超神》要求做成全显示。并且血条希望实现移动平滑,必须每帧去刷新血条位置。
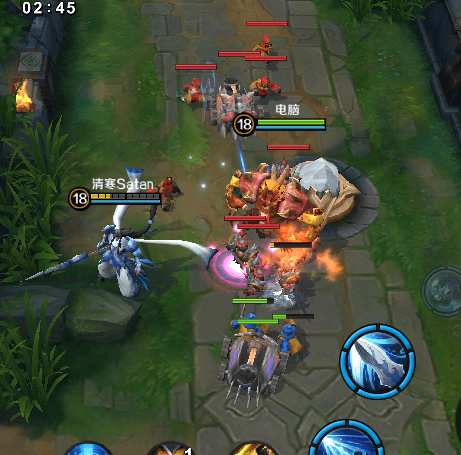
下图是游戏中的小地图,小地图上的动态元素也非常多,包括英雄、小兵、野怪、建筑、宠物信使、侦察守卫等。不过小地图的更新频率会稍慢一点,每三帧更新一次。

这里的问题是,在动态UI元素如此多,且要不断地去更新,如何保证效率?最终研发团队放弃使用UGUI的现成方案,转而自己构造Mesh,自己构造出来的Mesh使用一个单独的正交摄像机来绘制,为了方便区分血条、小地图,我们局部做了区分,实际中是在同一个摄像机下面。
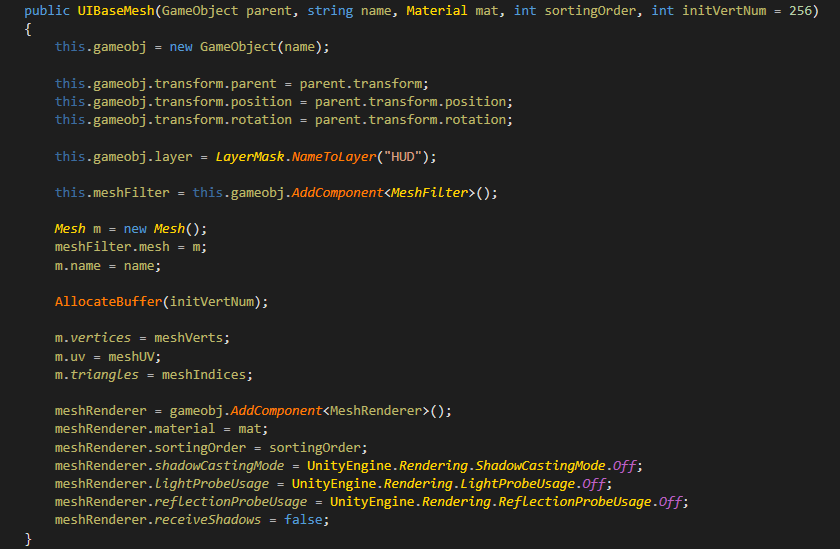
在UI Mesh的构造函数中可以看到是创建了一个GameObject,附加MeshFilter和MeshRenderer,然后再做一些初始化的工作。重点在于自行填充Mesh的三个Buffer:位置、UV和索引。另外为了避免在运行时重复申请内存,在初始化的时候要申请足够多的顶点。在实际游戏中用到了多个UI Mesh,总体的顶点数大概在3000左右。
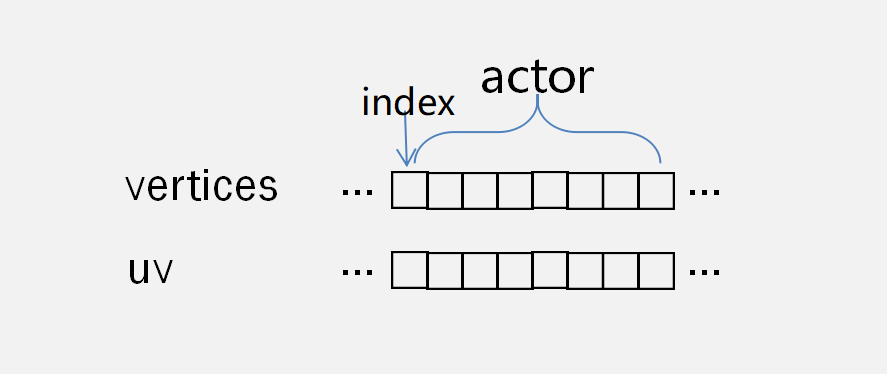
初始化Mesh之后,还要去维护顶点Buffer。在《小米超神》中每个Actor要维护自身的数据,包括顶点位置和UV,并保存它在数组中的索引。举个例子,一个小兵的血条包含背景底框和前景血条,2个矩形8个顶点,在游戏中去动态地改变这8个顶点的位置。如果某个Actor不在视野中,那么把它所有顶点坍缩到一个点就不显示了。另外,Actor死亡的时候,并不删除它的数据,而是先设置为不显示,然后缓存起来准备复用。也就是说无论整场战斗创建了多少个角色,实际上血条都是在这个Mesh的Buffer里不断复用。
下图是由Actor调用的代码,BuildQuad是Actor申请数据段,返回Buffer的Index。下面这个是运行时改变顶点位置和UV。所以由于一开始申请了足够多的顶点,在运行时基本是没有UI Mesh Rebuild的消耗。
上文提到《小米超神》中用到了多个UI Mesh,主要因为有相互遮挡的需求,比如英雄的血条要在小兵的血条之上。因为渲染UI Mesh的时候没有开深度,所以如果做在同一个Mesh里就不能保证图标之间的遮挡关系。如果有分层级的需求,就要把它们分开成多个,并且使用MeshRenderer的SortingOrder来保证渲染顺序。在游戏里,HUD和小地图分别有4个层级,共8个DrawCall。

为了在一个UI Mesh里面渲染,必须把图标拼到一个大图里。HUD血条是用UGUI的静态图集来做(下图左图)。而在小地图上由于有动态的图标,包括英雄和信使,以及一些会在小地图上显示的英雄技能。采用动态图集方式,在加载时渲染到一张256x256的大图里。

总结,UI Mesh的用处在于避免UI重建,以及减少DrawCall。
3. UI和特效混排
在游戏中,大量的UI上都嵌入了特效。因为Unity中UI和粒子/Mesh的渲染方式不同,是两个体系。所以原本将特效嵌入UI界面,遇到排序问题是通过团队自身管理SortingOrder来解决,当UI面板逐渐增多的时候就变得越来越复杂。因此我们团队也在思考能否把它们归到一个体系当中来处理。下图中的麦克风特效、装备特效以及技能升级特效,都可以复用。

最终解决方案是把特效渲染到RenderTexture上,在UI组件上使用这张纹理的方式。这种方式的优点在于,由于使用的都是UGUI组件,所以没有任何的排序问题,可以任意嵌入UI中,并且相同的特效可以在多处UI复用。然而这种方式也有缺点,首先需要多一遍UI Image的绘制,同时引入RenderTexture必然增加了内存占用。但是对于《小米超神》来说,由于我们在UI里面嵌入的特效较多,这种方式确实是最佳方案。
需要提醒的是,这种方案不能直接使用默认的半透明混合公式。原因是由于混合顺序发生了变化,先渲染到RenderTexture上,再渲染到UI上。以最常见的AlphaBlend为例,在混合顺序发生变化的时候,可以看到FinalColor和实际得到的FinalColor有区别,左边这张图比右边这张会明显偏白,右边这张才是我们期望得到的效果。

因此将混合公式做了修改调整,以确保结果的正确性。修改方式:首先RenderTexture的ClearColor要改成黑色,Alpha为1。然后是特效的Shader,Blend方式要做修改,Color方面不变,还是Srcalpha Oneminussrcalpha,Alpha部分要改成Zero Oneminussrcalpha,最后是引用RenderTexture的UI Image,Blend方式改成One Srcalpha。不过这只是单次混合的结果正确,如果扩展到多层叠加的一般情况呢?
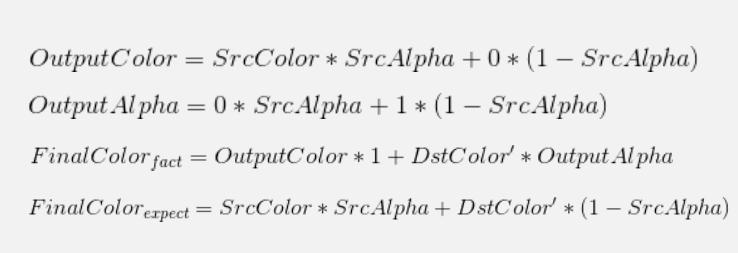
图中的C代表Color,A代表Alpha,推导可以得出,即便对于多层混合叠加的一般情况,这种修改方式也适用。
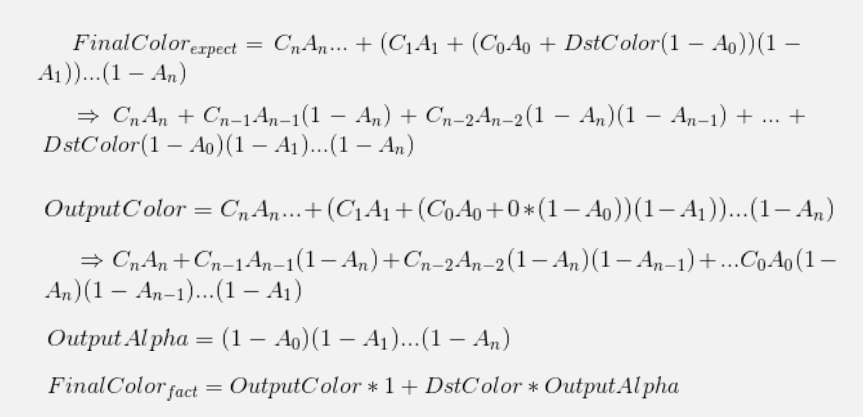
解决了AlphaBlend的问题,另一种在特效中常用的混合方式就是Additive,同样对Shader的混合公式做了小改动,Color方面保持不变,Alpha改成Zero One。在《小米超神》项目中UI特效只用到了这两种混合方式,不透明的物体不存在混合顺序问题。如果大家的游戏中有用到更复杂的特效,可以再扩展。
二、场景
1.不可见物体优化
所谓不可见物体就是摄像机里看不到的物体,这种物体不会被玩家所关心,相对的就可以对它们进行一些优化。
在Unity场景中的GameObject,每帧都会执行附加的Monobehavior组件的Update,包括了Unity自身动画、粒子系统,以及Component的Update。当物件多的时候,这部分消耗很大。另外,当GameObject位置和朝向发生变化的时候,设置Transform的Position和Rotation会便于所有的子节点调用它们的SetPosition和SetRotation,而且是一个递归的树状结构,如果GameObject层次比较深,这部分的消耗不能忽略不计。因此可以考虑当物体不可见的时候不做更新。
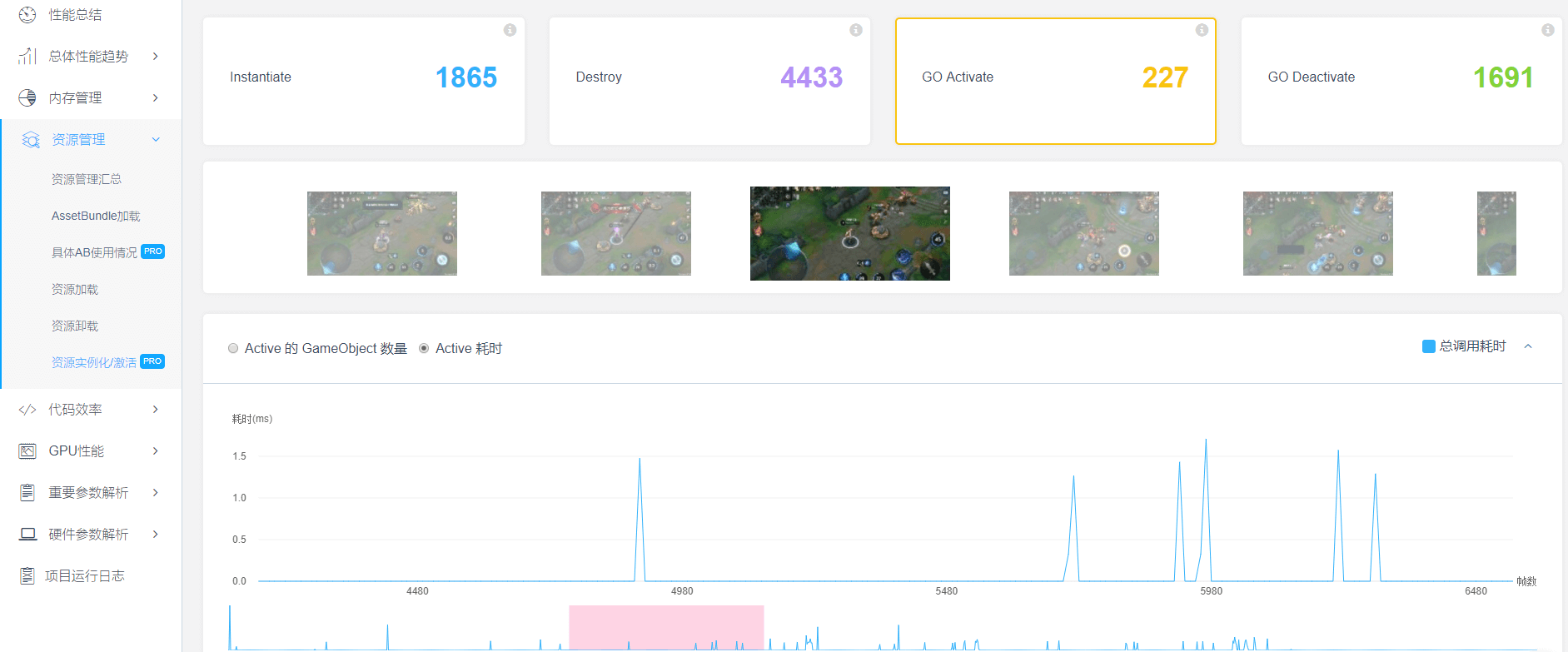
具体做法是分离Actor的逻辑Transform和对应的GameObject的Transform,把这两个独立开来。当逻辑Actor的AABB包围盒处于视锥体中的时候,才更新GameObject,包括设置它的Transform,否则就将整个GameObject 关掉。这样就不会调用其组件的Update。这样做确实降低了更新GameObject和设置Transform的消耗,但是在GameObject的Activate和Deactivate的时候有额外的消耗,这里要感谢UWA帮我们指出这一点。
从GameObject Activate的消耗曲线可以看到,性能消耗还是相当可观的,平均有3毫秒左右,峰值可以达到10毫秒,并且数量级很大,整场游戏当中有1万多次。原因是频繁对镜头内外的GameObject做开关所导致的性能开销。
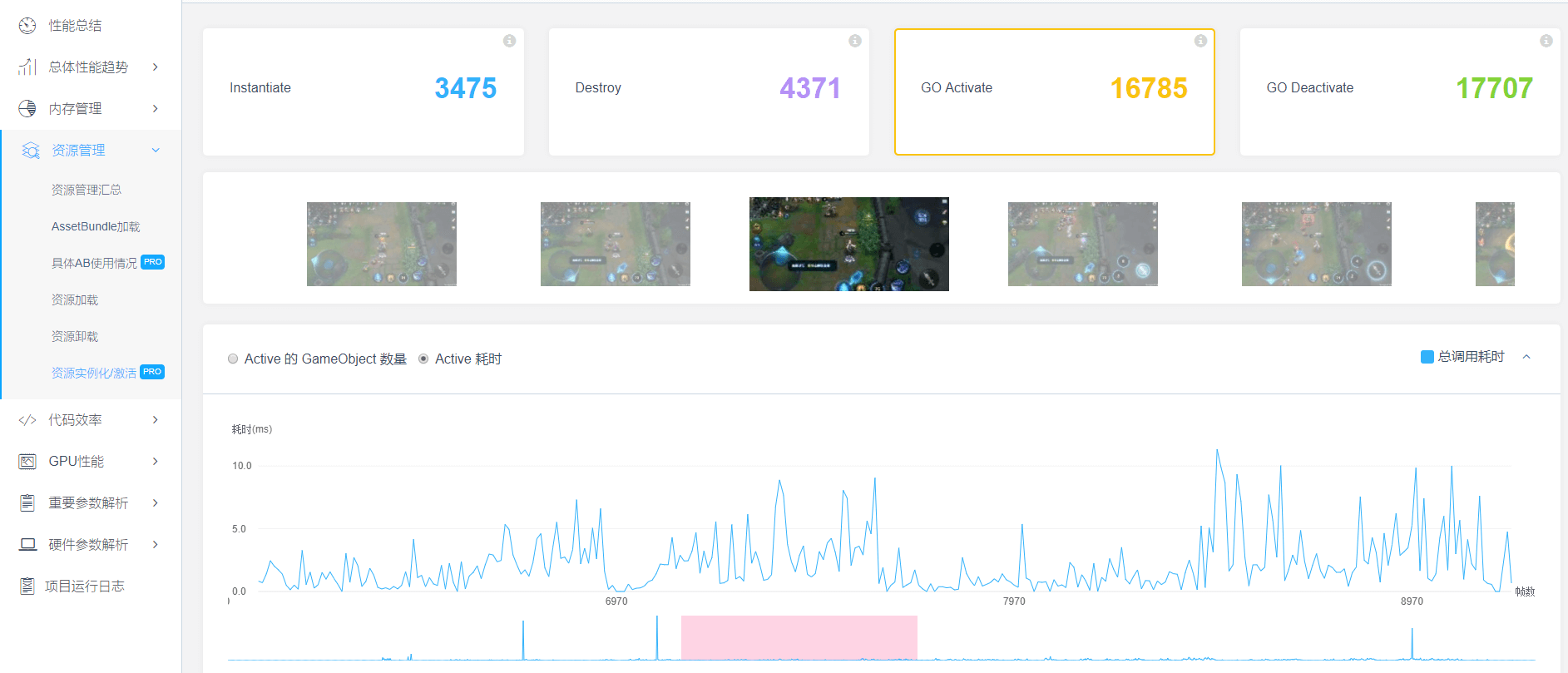
GameObject Deactivate的消耗,也是处在同一量级。这种量级的开销对于总共只有33毫秒每帧的游戏来已经很高。所以不能单纯通过Activate和Deactivate的方式来降低Update的消耗。
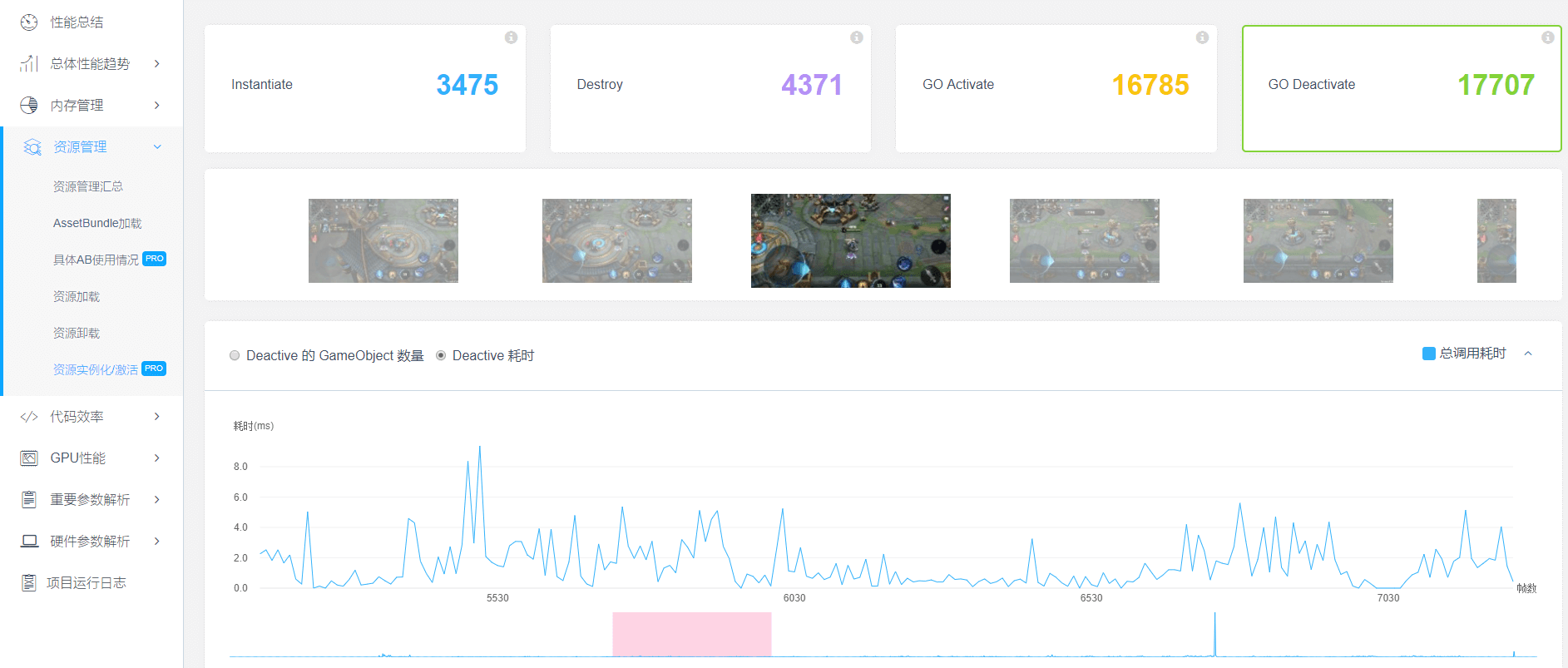
解决办法是把GameObject上面附加的MonoBehavior对其作了Enable和Disable。包括Renderer的Enable/Disable、Animator、Animation和粒子系统。对于Animator,不能把它Disable掉,因为Animator是个状态机。因此按照需求把Animator的Update Mode改成Cull Update Transforms甚至是Cull Completely。至于Animation,如果想把它Disable掉,然后Enable的时候又能恢复正常,就必须自行维护Animation的时间。下图贴出来的代码是在Enable的时候设置Animation State的时间,然后把权重设成1,这样才能表现正确。粒子系统同样,如果选择Disable要自行管理时间,Enable的时候去设置时间。如果是自写的MonoBehavior,当然就要根据需求决定是不是要关掉。
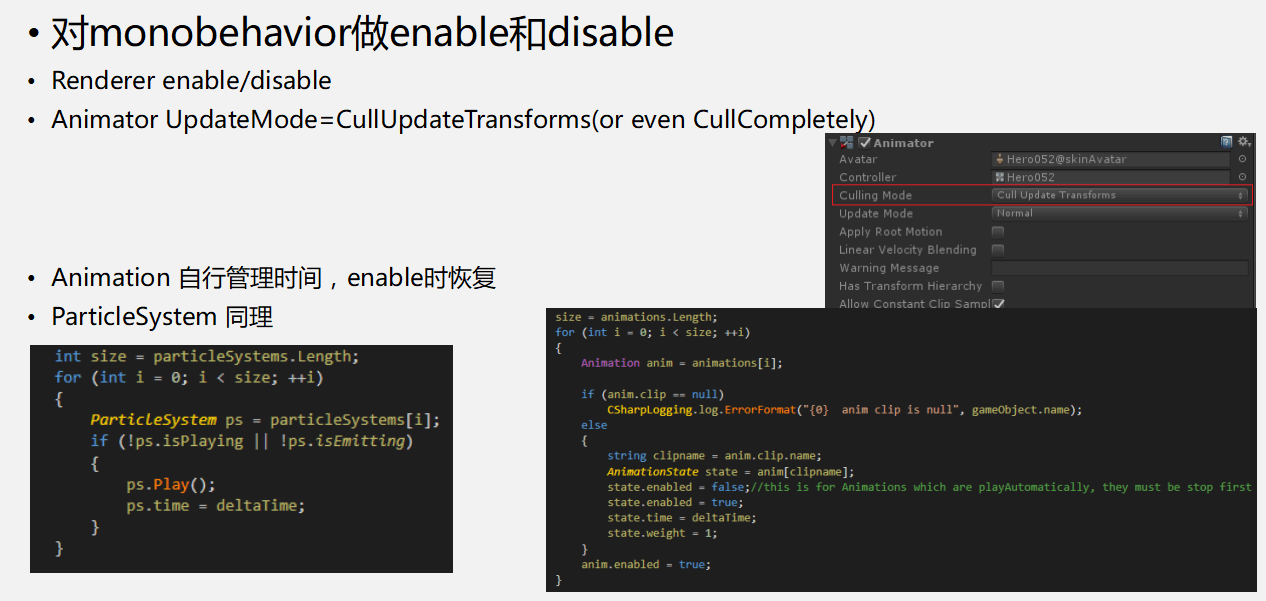
优化之后,Activate和Deactivate的数量大幅下降,从曲线来看消耗也明显减少。再和前面的一万多次消耗做对比,效果很明显,表现上也没有问题。
2. Crowd渲染优化
《小米超神》标榜的是重度MOBA,所谓重度MOBA,其实就是场景大、小兵多、野怪多、光效多。小兵的数量和端游是一样的,每波5只,三近战两远程,另外夹杂有投石车。相比而言,更容易出现同屏大量角色的问题。特别需要提醒的是,因为兵都是从基地里出的,所以如果是在基地处爆发团战的时候,同屏可能会有大量的小兵存在。由此带来的问题有三个:
- 动画计算
- 蒙皮的消耗
- 大量的DrawCall
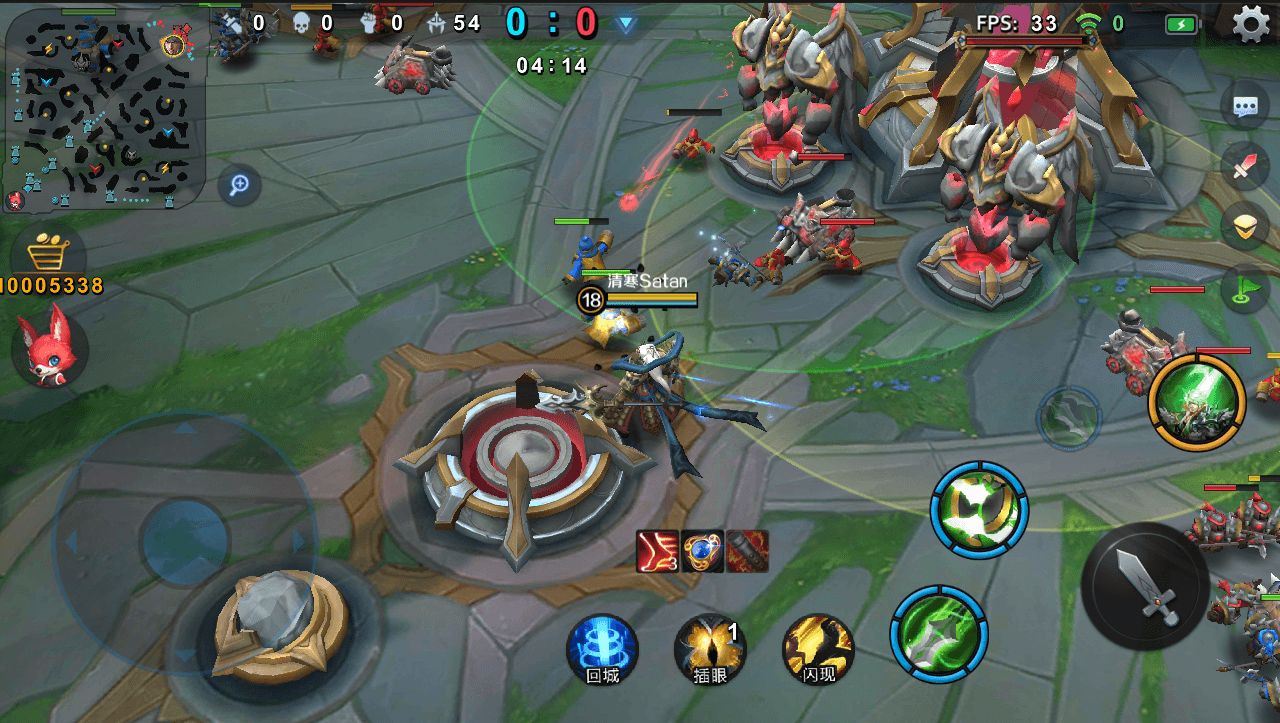
Skinned Mesh无法依靠Unity的Dynamic Batching,但采用骨骼动画的话这些问题是避免不了。
解决方式就是不用骨骼动画,采用key Frame Animation, 这个启发来自于2016年顽皮狗的一篇文章。就是将小兵的每一帧动作的顶点位置都写入到纹理上,在Vertex Shader阶段去采样获得顶点位置,这样既不需要骨骼,也没有蒙皮的消耗。当然在VS里面采样纹理需要手机有VTF的支持,要预先加个判断,如果硬件不支持的话,就只能Fallback到骨骼动画。不过大部分GLES 2.0的手机也都支持VTF。
在游戏中,小兵的顶点数小于1024,所以使用一张512*512的纹理分成两列来储存动画,可以储存256帧,每秒24帧的话相当于10秒多,保证足够使用。同时,为了让动画的帧与帧之间平滑过渡,避免采样的时候可能采样不到关键帧,把纹理的Filter Mode要设为Bilinear。
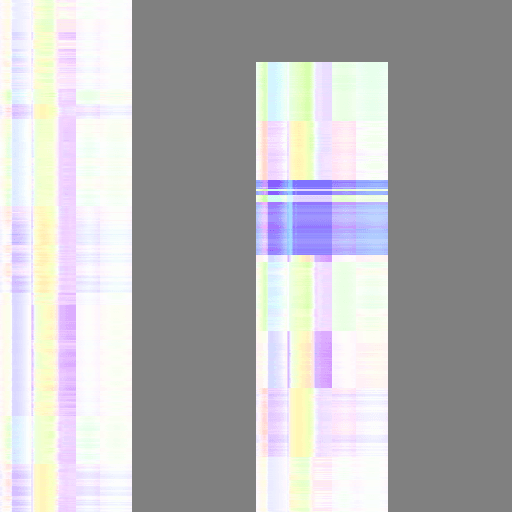
还有一个最大的问题在于浮点精度,原来一个顶点的位置数据是X、Y、Z三个浮点数,显然游戏不可能存储这么高精度的数据,带宽也吃不消。于是采用RGBM的方式,将顶点位置压缩到一张RGBA32的纹理中。从实际表现来看,损失的精度在可接受的范围内。在这下图里左边的是骨骼动画的一帧,右边的是对应的key Frame Animation的一帧,确实有一些精度损失,但是影响不大,特别在手机屏幕较小的情况下。

去掉了骨骼动画,团队在Update里去计算当前的动画时间,换算成动画帧,在渲染的时候把帧作为材质参数传进去。
另外一个问题是,很多时候骨骼不仅仅是用来做动画计算,还作为绑点使用,比如我们射击的时候,要取得枪口位置,然后在枪口位置生成子弹发射出去,上述方式因为去掉了骨骼,需要一个替代方案。于是在烘培顶点位置的时候把骨骼的关键位置同时记录下来,基本上是一个数组,然后游戏中需要的时候使用三次施密特曲线来做拟合。这样就可以大致地还原骨骼的位置,对原有的逻辑不产生影响。
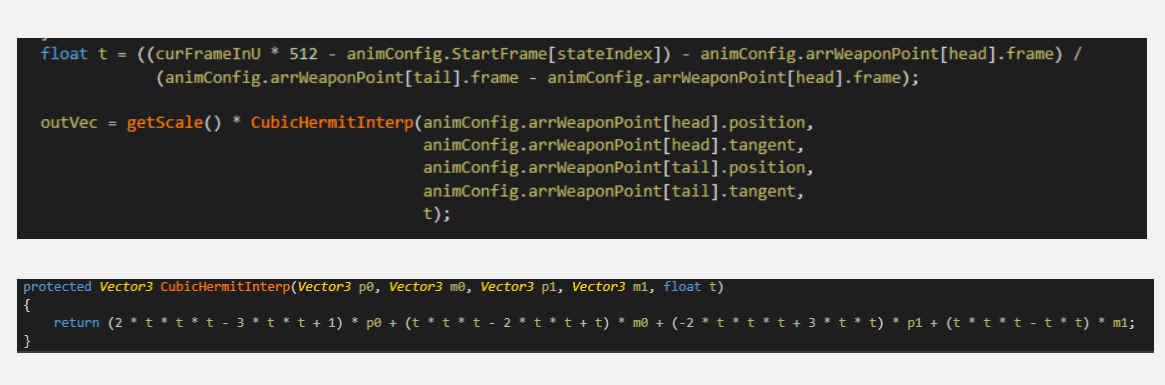
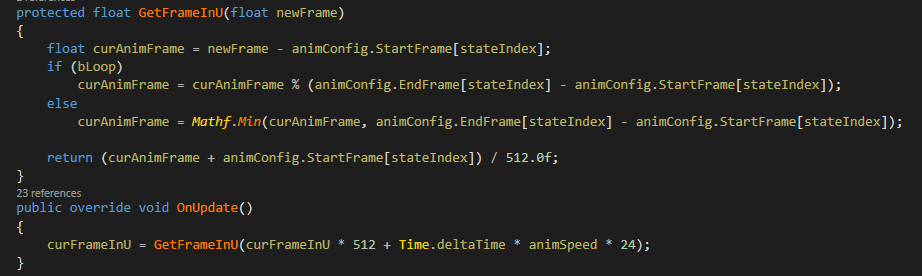
在Shader部分,我分享一段Vertex Shader代码。这里主要就是生成UV,然后根据UV到预先烘培好的纹理中去采样顶点位置。这里需要知道顶点序号,由于SV_VertexID要到OpenGL ES3.0才有,而VTF虽然不是2.0的标准,但很多2.0的机器都支持了,所以考虑低端设备兼容,把顶点序号存在UV2中。然后根据传入的动画帧来决定采样动画纹理的U,而V是根据顶点序号来得出。这样就能得到这一帧的顶点位置。另外除了顶点纹理,团队还烘培了一张法线纹理,以便于计算光照,法线纹理没有使用True Color而是RGB压缩。如果游戏里小兵不使用动作融合,这里只传了一个动画帧即可,如果使用动作融合,需要传进一个Float4,包含两个Frame和权重,然后分别进行采样再插值,所以这种方法其实是兼容动作融合的。
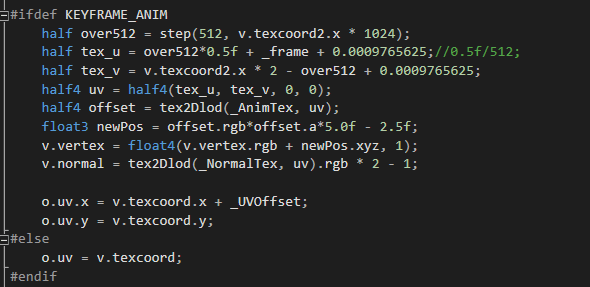
Nvidia在GDC2003有一篇Batch,Batch,Batch,尤其对MOBA这种CPU负担重的游戏而言,降低DrawCall把物件Batch起来就显得很重要。所以对于OpenGL ES3.0以上的机器来说,既然已经去掉了骨骼,很自然地就要使用GPU Instancing。在物件少的时候GPU Instancing的性能相比起来并没有优势,但是物件多了以后,它的性能曲线更平滑。《小米超神》中,小兵分为近战兵、远程兵、投石车这三类。因为红蓝双方小兵的角色模型一致,但纹理不同,为了相同Mesh只用一个Batch来渲染,我们把纹理压成一张,蓝方在左边,红方在右边,使用UV偏移来采样。那么在Instancing的时候就需要把动画帧、UV偏移、颜色等信息作为数组传入。

这是加了GPU Instancing以后的Vertex Shader,就是对传入的属性加了宏,其它不变。
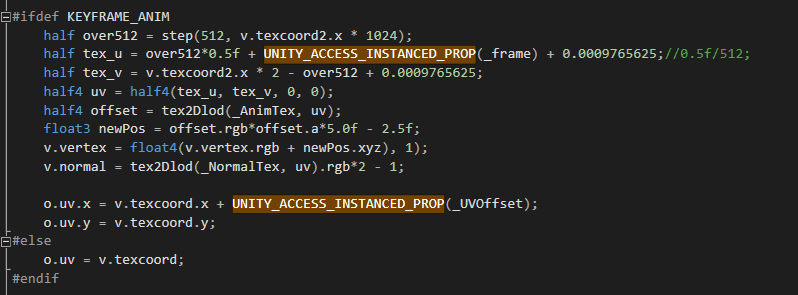
最后可以看一下效果,在用了Key-Frame Animation和GPU Instancing之后,分别把近战兵,远程兵和投石车Batch到一起,角色数量最多的小兵就只有3个Batch。不过在使用上也需要衡量,不是所有角色都适合Key-Frame Animation的方式,因为需要额外烘培RGBA的贴图,一般来说使用在顶点数少,精度要求不那么高而数量又多的角色上。

以上就是我本次分享的技术内容,基于《小米超神》研发过程中遇到的问题和解决方法的复盘,希望能对大家的研发有所参考。谢谢大家!
这样一来,技能面板动态图标的消耗从12个DrawCall降低到1个DrawCall。而英雄头像部分,从最多9个DrawCall降低到2个DrawCall
以上的问题我实在没有搞懂,像比如小技能图标、头像ICON 肯定会打图集的,绝对不是散图,所以你的12个DC怎么来的?