
动态骨骼Dynamic Bone优化
- 作者:admin
- /
- 时间:2018年12月04日
- /
- 浏览:14680 次
- /
- 分类:厚积薄发
Dynamic Bone是基于弹簧质点算法的弹性节点模拟组件,可以用于柔性绳索和其他的简单的柔体,上一篇我们已经详细的对于算法进行过研究,想回顾的可以到这里查看
上周主要在对原版代码进行优化以适应大规模的应用,优化过程主要是减少了向量、矩阵的数学运算的消耗,缓存每个节点的状态变化,降低计算频度高,减少其一帧内的计算量,并且进行了ECS化和Job System的尝试,最终效果目前符合预期。
场景内50个模型,共450个组件对象,2700个节点 ,测试为PC环境,CPU为i7-8700,属于高配,数据仅供参考。
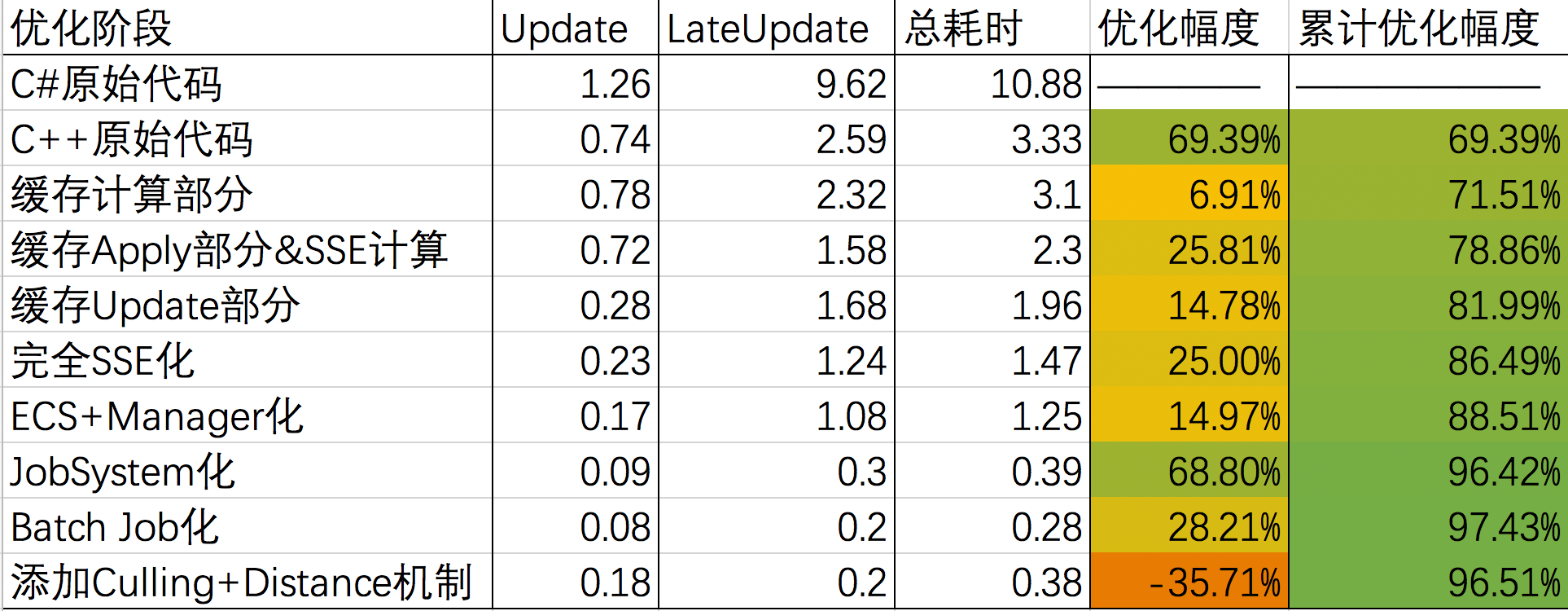
优化的相关结果
DynamicBone经历一系列优化之后,单帧耗时下降非常明显,目前只有原始C#版本代码开销的4%不到。不考虑Culling和Distance机制仅有原版的2.5%的开销,对于distance的计算后面不会每帧去计算,最后会采用间隔几帧来处理,原版插件没有culling这部分。
上面数据的这一系列优化除了C#到C++的迁移之外,还涉及到Unity引擎内部的相关调整,在下面会一并的进行介绍。
一、Transform的结构与算法优化
Dynamic Bone优化过程遇到的Transform的最主要的性能坑点,或者说最主要的不必要的高额性能开销,就是Transform提供的最通用的各项全局数据(例如位置、旋转、变换矩阵等)的获取和设置接口开销相当之高。从上图的数据可以看出与Transform进行数据交互至少占了整个计算流程30%的时间;
Transform的数据读写接口的高耗时与其数据结构有关。由于Unity场景内所有GameObject都是以层级关系相互关联的,所以Transform使用层级关系结构来储存变换数据,每个Transform对应层级关系树中的一个节点,其只储存本身的局部位置、局部旋转和局部缩放;
这样Transform只用关心自身局部变换数据的修改,父节点发生变化后不用修改所有的子孙节点的数据(虽然实现上不是完全没有修改)。但是由于所有的Transform都只存储局部变换数据,所以当需要读取或者设置某个Transform的任何全局变换数据时,这个Transform都需要向上回溯计算得到他的全局变换数据。
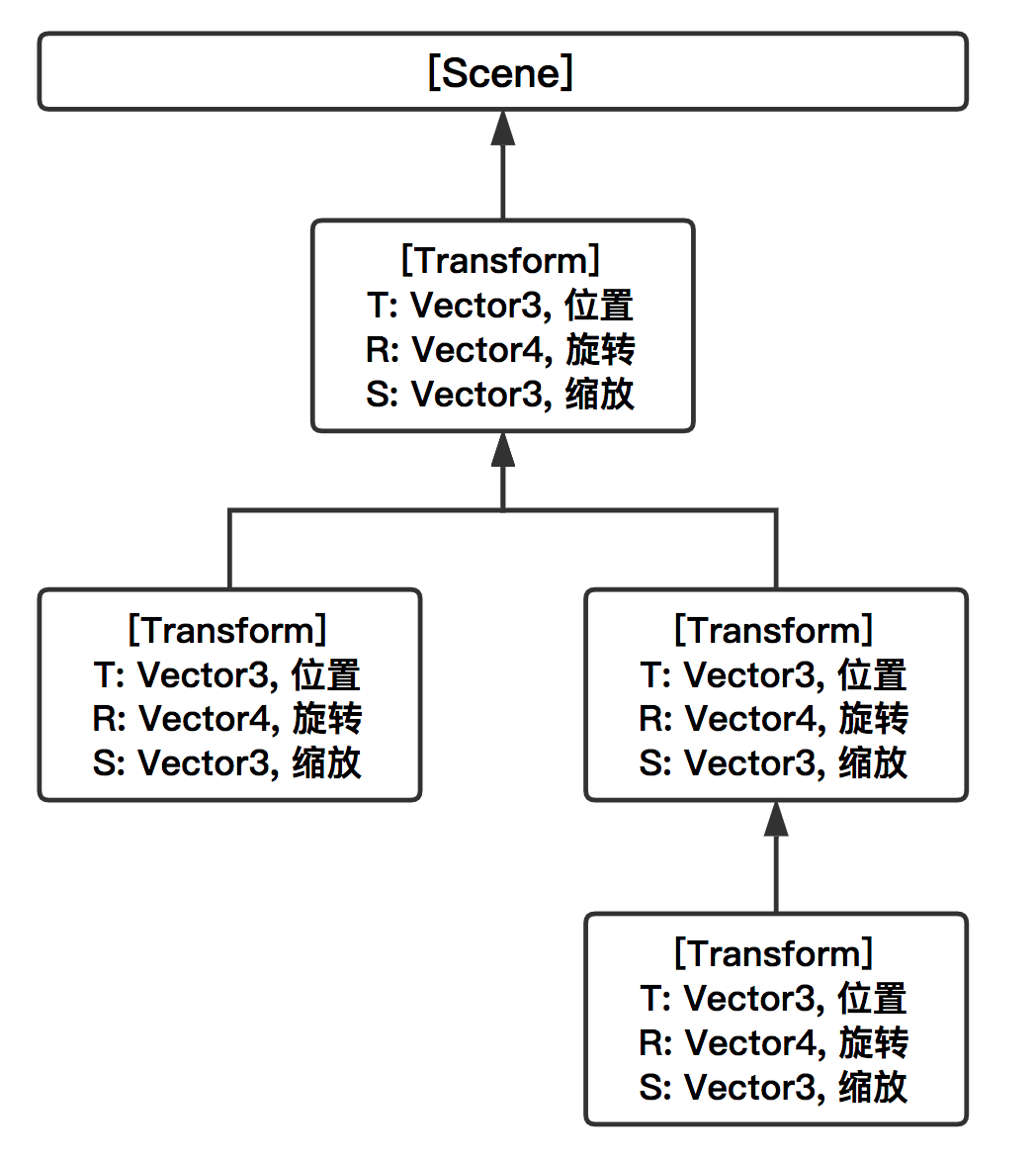
Unity的Transform结构
Transform的全局变换的计算开销问题本身可以用Cache处理——当每次读取Transform都将读取过程计算得到的结果储存到Cache,而当两次读取之间Transform的变换数据没有发生变化时,Transform不进行计算直接返回Cache值,需要计算时再进行更新计算——由于Unity中整体逻辑流程是串行的,没有逻辑上的并行(Job System只是计算并行),因此这个功能不难实现。
但是Transform却没有任何Cache逻辑,虽然其有一种ChangeMask机制用于保存当前Transform是否有过修改的信息,但是Transform没有基于ChangeMask建立Cache,这就导致对于Transform全局位置、旋转、缩放数据的每次读取和修改都会导致Transform从当前节点出发,逐层递归或者迭代直至根节点计算出全局变换数据;
这其中,SetPosition\SetRotation的逻辑也是会先逐层向上求逆,直到求到当前节点应有的局部变换数据之后再进行设置,但是与全局Getter函数不同的是,Setter函数求逆的过程是递归的,同样的简单逻辑递归的实现要比迭代耗时很多,这就导致Setter函数的性能更加低下;我们的优化也就对其进行了CACHE,CACHE后数据看出效率提升明显。
二、SIMD数学库对于普通数学库的修改
原始的代码是不经过SIMD的,改为C++代码以后编译也就编译器的默认的simd的优化,而Unity内部几乎所有的数学计算都使用它自己的数学库的SIMD优化,因此我们对代码进行了改写保持与引擎内部的计算一致。
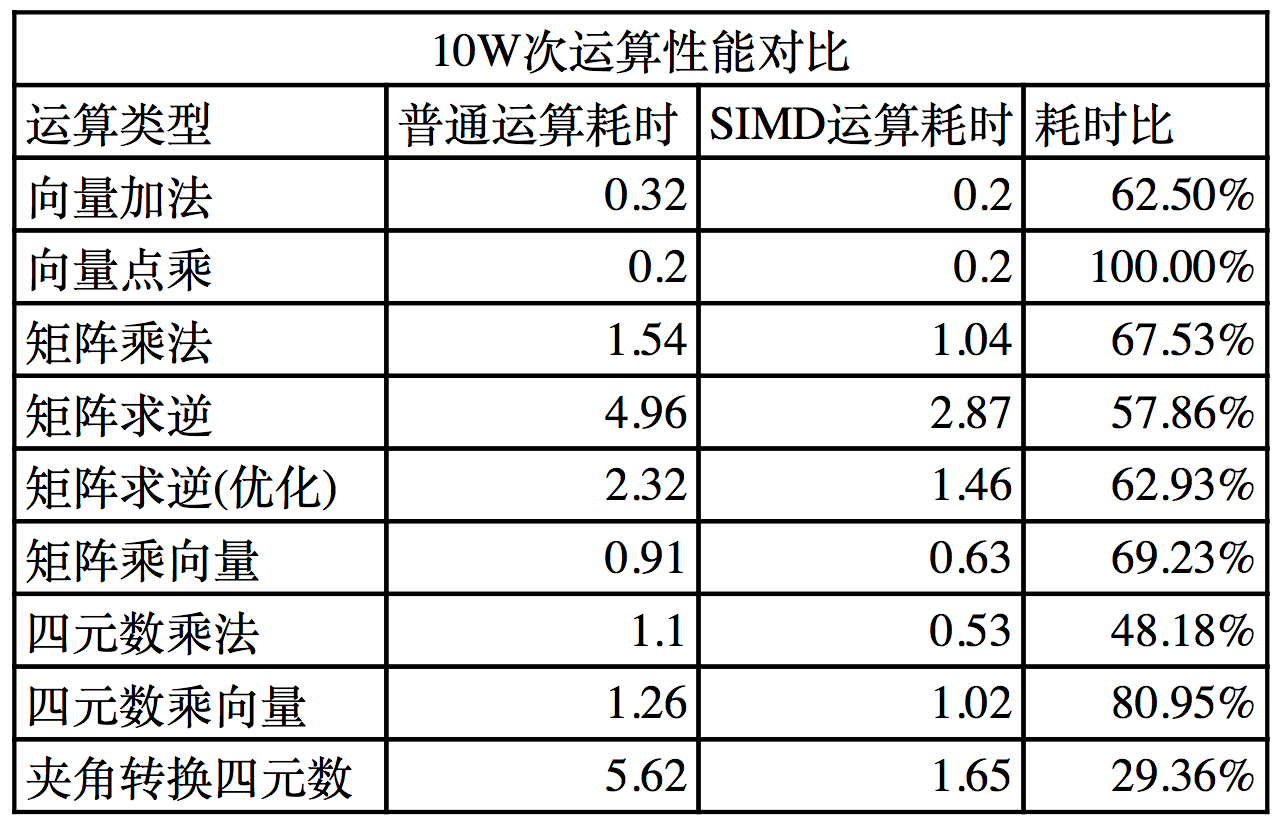
顺手进行了下测试,测试代码的编译环境是VC++2010,优化全开,通过查看反汇编代码可以看出VC编译器是会自动进行SIMD优化的;
结果中的向量点乘和四元数乘向量都有明显的SIMD优化,以至于普通运算耗时接近SIMD运算耗时,这对测试结果影响比较明显,但考虑到安卓平台编译环境依然可能有自动的SIMD优化,所以这里没有关闭编译器的SIMD优化开关;
从测试结果可以看出:
1、SIMD对向量四元数矩阵等数据结构运算优化是比较明显的,能减少40-50%的耗时;
2、虽然有编译器的自动SIMD优化,但是其优化幅度有限,实际优化还是要依赖技术手动调用SIMD接口;
三、ECS机制以及Job System化
ECS机制以及Job System是Unity为了提供代码性能而提出的设计框架,ECS即Entity-Component-System,核心理念是把原先的OOP思想改为DOD思想。DOD的好处是可以将同种数据集中到一起并放在内存中密集排布,大幅增加CPU Cache的命中率,降低代码抽象度,将数据独立出来,并且断开各种数据之间的耦合,这样Job System就可以将同种数据分散到不同的线程进行处理。具体ECS机制官方已经有详细的DEMO和数篇文章介绍,在这里也就不再重复,下面说说对于Dynamic Bone原始的结构改进以满足优化要求。
1.数据的拆分-ECS化
查看插件源码可以知道DynamicBone是每个实例各自储存自己的组件数据以及自身粒子(DynamicBone会将每根骨骼抽象为一个弹簧粒子)的数据,并且在每帧Update和LateUpdate中完成自身数据的更新,
我们增加了一个DynamicBoneManager进行整体的管理,Manager的好处可以统一储存所有组件和所有粒子的数据,并且所有数据都是以直接数组的形式平坦储存的;然后Manager会在自身的Update和LateUpdate中通过JobSystem一次性并行更新所有粒子的数据,并且将其Apply至对应的Transform对象上;
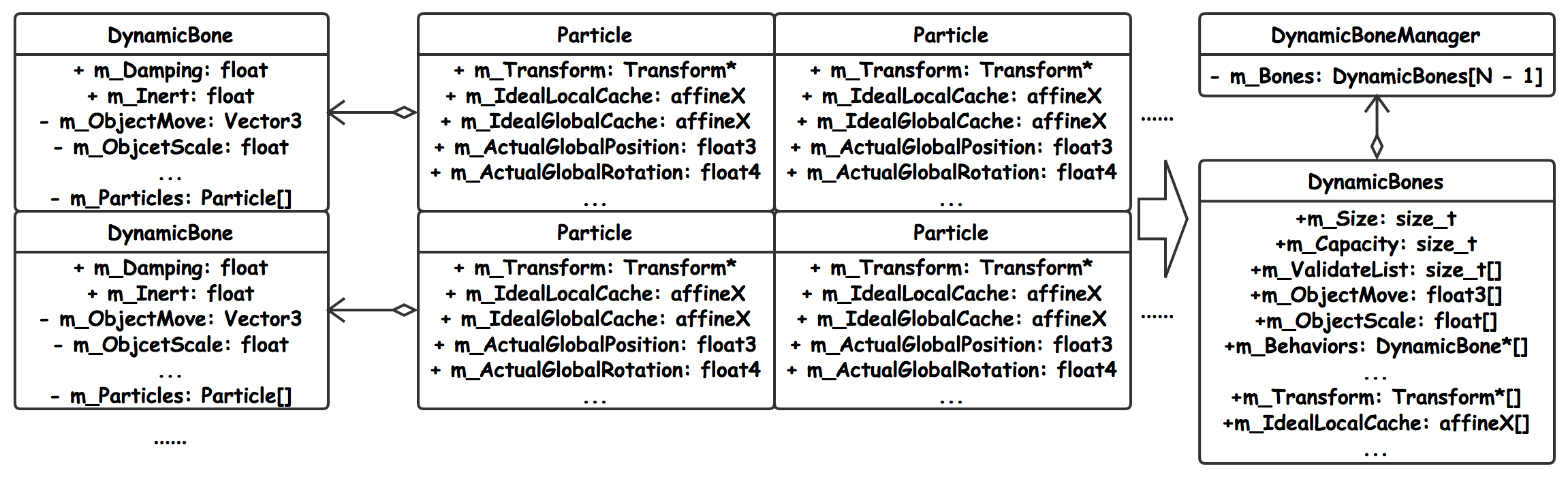
经过这样设计以后,DynamicBoneManger把原本分散作为DynamicBone和Particle属性的数据全部集中在集合DynamicBones中,然后再对集合进行分类,分类依据就是DynamicBone组件对象拥有的节点数量;

如上图中所示的DynamicBones对象,红框部分就是Particle数据,其他是DynamicBone数据以及有效列表数据,而这里Particle数据集合永远保持为其他DynamicBone数据集合大小的两倍,也就是说这个DynamicBones对象专门容纳有2个节点的DynamicBone对象的数据。同理,就可以创建N个DynamicBones对象,分别容纳有2到(N+1)节点的DynamicBone对象的数据。这样的设计完成后,所有组件和粒子的数据都是内存紧密排布的;Manager会一次性申请大量的空闲内存,而当新的组件Entity注册的时候,Manager只会就近找一个没有被使用的无效索引分配给这个组件Entity,并且将这个索引置为有效,随后初始化Component数据,并且将数据存入索引的空闲内存中。反之,当Entity注销的时候,Manager并不真正释放内存,而只是将这个索引置为无效. 同时,Manager会维护一个有效索引表,Manager每一帧只用按照这个表去更新有效索引指向的所有Component数据。

2.Dynamic Bone的JobSystem使用

由于Manager使用索引逻辑,所以Job只需要和有效索引一一绑定就好了,DynamicBoneManager的JobData内只有索引相关的信息,还有Component数组指针。每次当有索引被设置为有效,就会添加新的Job,反之就会删除存在的Job。例外补充一下对于Job的拆分后需要注意下本身的Job消耗太小比如处于0.001MS的消耗,建议对于Job进行Batch测试,大家在2018的Job system的使用中需要注意。
这是侑虎科技第484篇文章,感谢作者FrankZhou供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/pkhere,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入USparkle开发者计划,这个舞台有你更精彩!


不知博主的代码是写在native plugin还是直接改引擎源码?如果是前者,与引擎的数据通讯性能开销很大,甚至超过c++或者simd带来的性能提升,此外C#脚本可以IL2cpp,实际性能会好不少