
UWA问答精选 应用篇 | 2019年度大赏
- 作者:admin
- /
- 时间:2020年02月11日
- /
- 浏览:4003 次
- /
- 分类:厚积薄发
UWA每周推送的知识型栏目《厚积薄发 | 技术分享》已经伴随大家走过了200多个工作周。在此我们精选了10个与应用相关的精彩问答,分享给大家。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Q1:AssetBundle如何计算可靠的Hash值
项目之前是使用建置出来的AssetBundle档案,自己算MD5当作用户端更新比对项目。但因为AssetBundle建置的不稳定性,常常Asset没有改变但是AssetBundle变了,导致用户端下载到不必要的AssetBundle。所以后来开始试着从Asset算一个Version Hash值。目前引入的参数有:
- AssetBundleName
- 有依赖但不在这个AssetBundleName下的Asset的路径与其 AssetBundleName
(跨AssetBundle引用实验出来是看AssetBundleName,当有依赖的Asset AssetBundleName改变则必须替换AssetBundle否则依赖加载会失效) - 所有这个AssetBundleName下Asset档案的MD5
- 所有这个AssetBundleName下Asset档案的.meta的MD5
- 所有跟这个AssetBundleName下的Sprite共用同一个Atlas,但不在这个AssetBundle的Sprite Asset与其.meta的MD5
但是这个方案实际应用还是有很多问题:
- Version Hash计算很久(有想过直接重复利用Unity AssetDatabase里的 Hash128,但是貌似很多人都遇到Hash128也不稳定的问题)
- AssetBundleName如果在建置时修改则不一定会写到.meta,造成.meta的档案MD5是错的。除非Reimport,但是Reimport就会造成建置时间暴涨(如果是把 AssetBundleName commit进Repo建置时不设定,则有可能有忘记commit的问题)
- ScriptableObject .asset没有commit却在Build machine自行变化,有的时候是 SerializeFile触发升级Migration(但是升级时间点非常谜,有时候本地用相同版本Reimport All也不升级,在Build machine却又有升级),有的时候是清单项目顺序调换
感觉自己Version Hash好像也没有完全解决问题又造成建置时间增加,所以想问在运营大项目的大佬们有什么建议,谢谢。
A1:个人还是投票给构建完毕之后的AssetBundle的Hash值。
一方面担心自己构建的不能覆盖所有更改的情况(题主考虑的已经挺全面),另外一方面是.meta文件本身就不是为构建唯一性设计的,比如它混合了各个平台的参数,任何一个平台的参数修改都会导致其内容的更改,因此我们必须参考meta,而它的修改又不一定意味着资源的修改,这样就很尴尬。
在这个前提下,可以做的事情是尽量发现和解决资源相同但是AssetBundle的文件Hash值却不同的情况。
感谢贾伟昊@UWA问答社区提供了回答
A2:我们是这样做的:
AssetBundleHash结合AssetFileHash,在Bundle对应的manifest文件中可以取到AssetFileHash值。
ManifestFileVersion: 0
CRC: 3889896754
Hashes:
AssetFileHash:
serializedVersion: 2
Hash: 7a90127ef724ff63cb40874dc69929b8
TypeTreeHash:
serializedVersion: 2
Hash: 0d46a8251e1e96cd839078edaf4c28a3
对于AssetBundleHash不同但AssetFileHash相同的,按未变化处理。
感谢littlesome@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5dac2d919fabd93d420711f7
Q2:升级DrawMeshInstanced不生效
我们对Shader的打包做法,一般是把项目的所有Shader独立打成一个AssetBundle,这样可以避免Shader的冗余,也使Shader可以热更。在5.5.4里这么做完全没有问题,所有Shader都能够正常地渲染、用于Instancing和热更。
但是在Unity 2018.3里,如果材质球和它使用的Shader没有打在同一个AssetBundle里,那么正常渲染材质球没问题,但是用这个材质球来进行GPU Instancing会不生效。试了一下Unity 2018.4也是这样。
测试工程(请戳原问答获取),用Unity在PC平台下就可以复现。能确认一下这个是Unity的Bug吗?还是我们对Shader打包和使用的方式有什么不对?
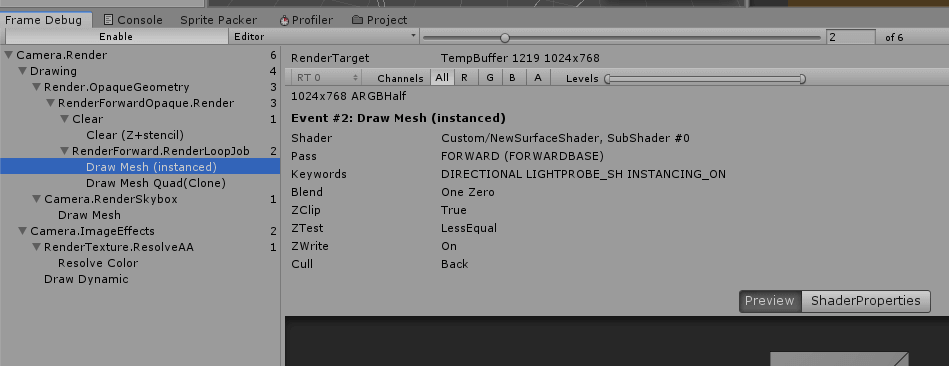
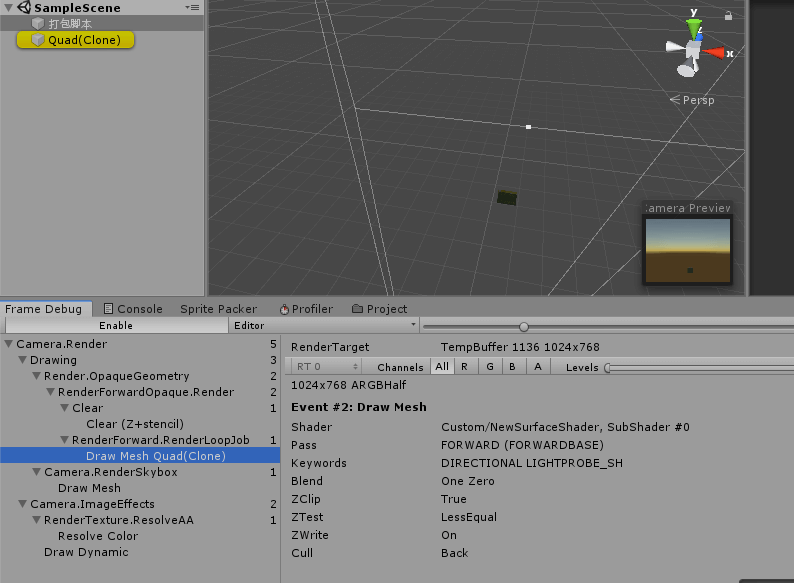
A:在Unity加入了Shader Stripping功能之后,就会出现很多Keywords丢失的问题。
可以看到成功进行GPU Instancing的Shader中有Keywords:INSTANCING_ON,但是分离Shader打包,加载运行的Shader,该Keywords丢失:
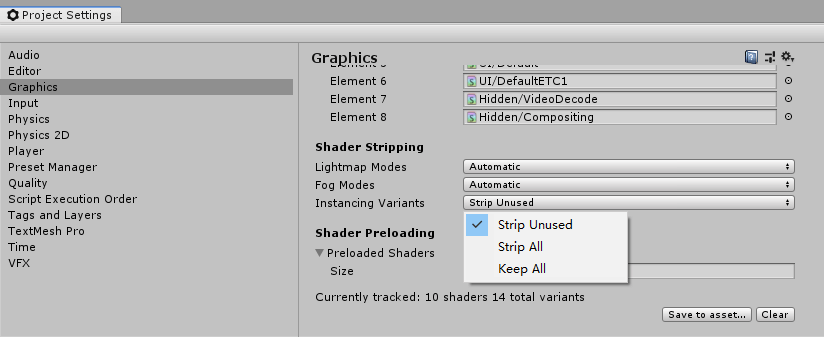
所以,解决方案之一,可以在Project Setting中,取消Stripping功能,选择Keep All:
解决方案二,就是选择在使用了该GPU Instancing功能的场景中打包,这样该Keywords便不会被strip掉。当然方案二不太切合实际,建议还是,保留这个Material一起打包。
该回答由UWA提供,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d077b23739f3b667bc57b95
Q3:Timeline中粒子系统受FixedTime影响问题
新建工程后,新创建一个Timeline和ParticleSystem,将ParticleSystem放入Timeline中,调大系统的FixedTime,在Editor运行状态下会明显发现粒子系统播放时出现卡顿(如果只是在Timeline预览是正常的)。看API和相关接口均未发现有相关的说明。请问这个是正常状态吗?如果希望粒子系统不受物理时间影响应该如何操作呢?Unity版本2018.4.0与2019.2.9均发现该问题。
A:解决方案:
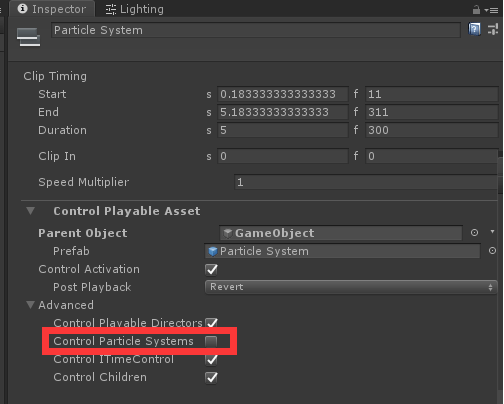
(1)不勾选Control Particle Systems选项,这样Timeline只负责粒子系统的生命周期管理,不会驱动粒子系统播放,相应的坏处就是在不运行游戏时不能预览粒子的效果了。
(2)修改官方代码,重写一个播放粒子的轨道。原因查找:
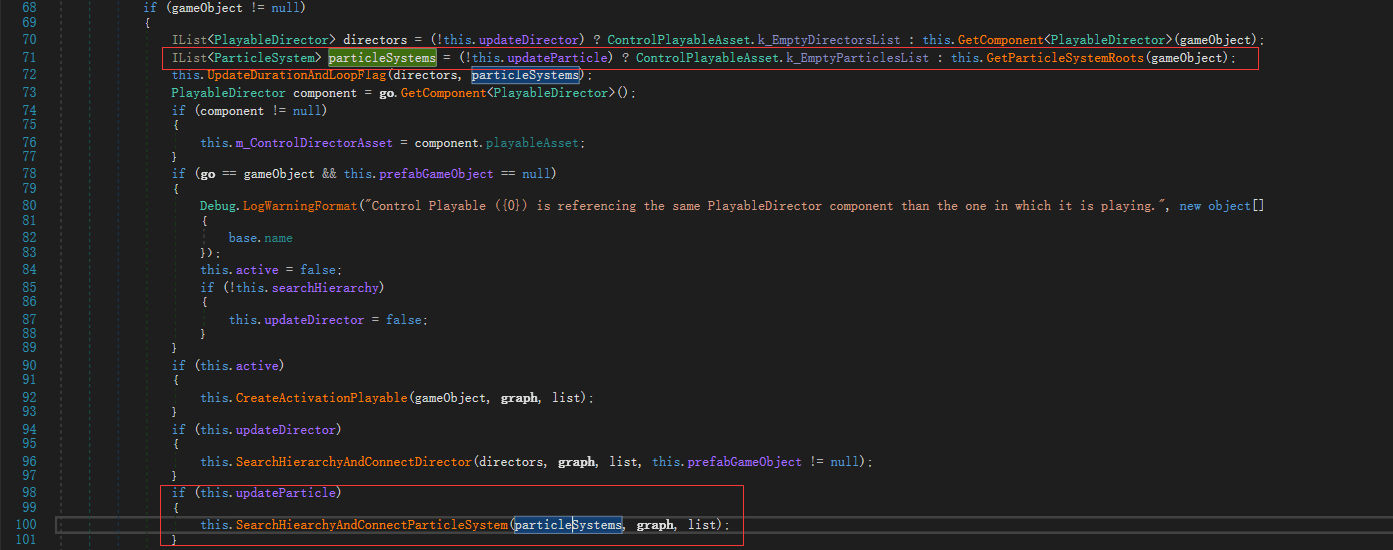
使用dnSpy打开UnityEngine.Timeline.dll,查看ControlPlayableAsset的代码。可以看到当updateParticels为true时,会把ParticleSystem收集起来,传入SearchHiearchyAndConnectParticleSystem方法中。
然后在上述方法中,会为每个粒子系统创建一个ParticleControlPlayable,在之后的逻辑会把这些Playable连接到这个Timeline系统的output上。
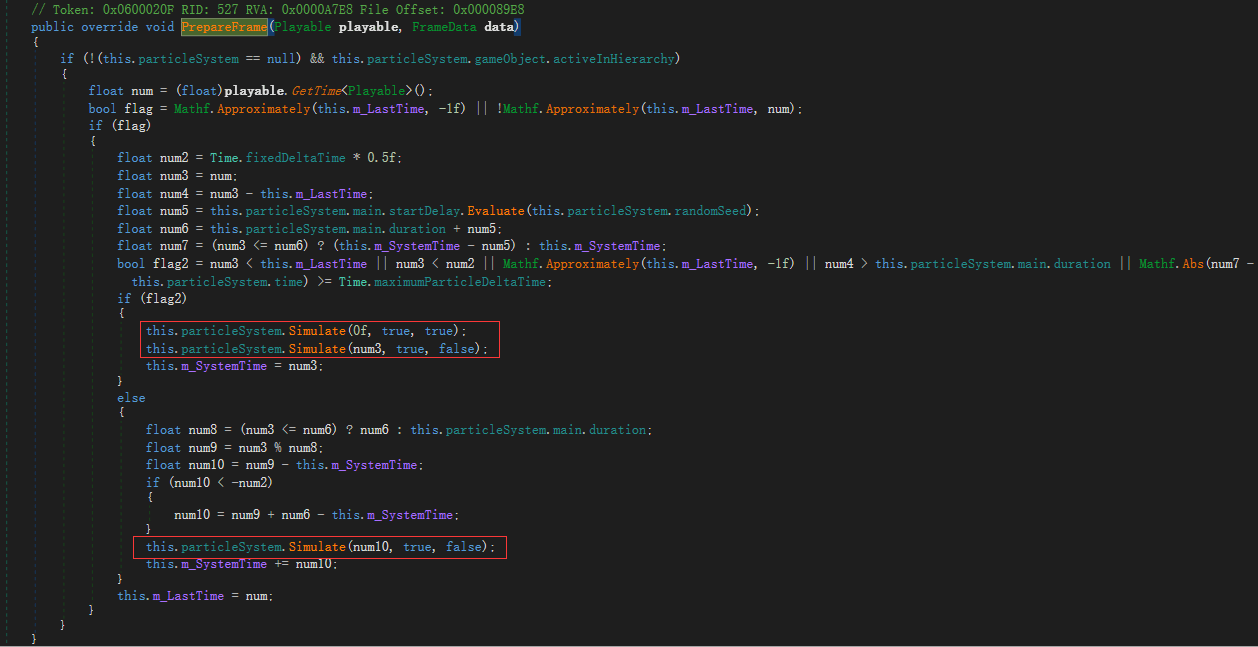
在ParticleControlPlayable类中,可以看到在PrepareFrame方法中,会调用粒子系统的Simulate方法。
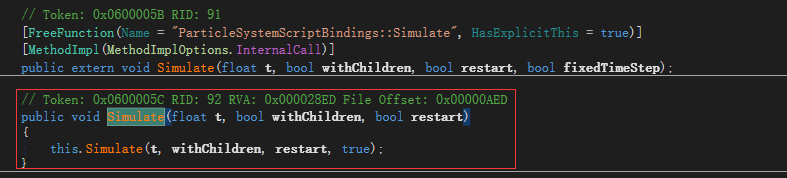
Timeline就是在这里驱动粒子系统播放的。这里调用的ParticleSystem.Simulate方法的原型如下图:
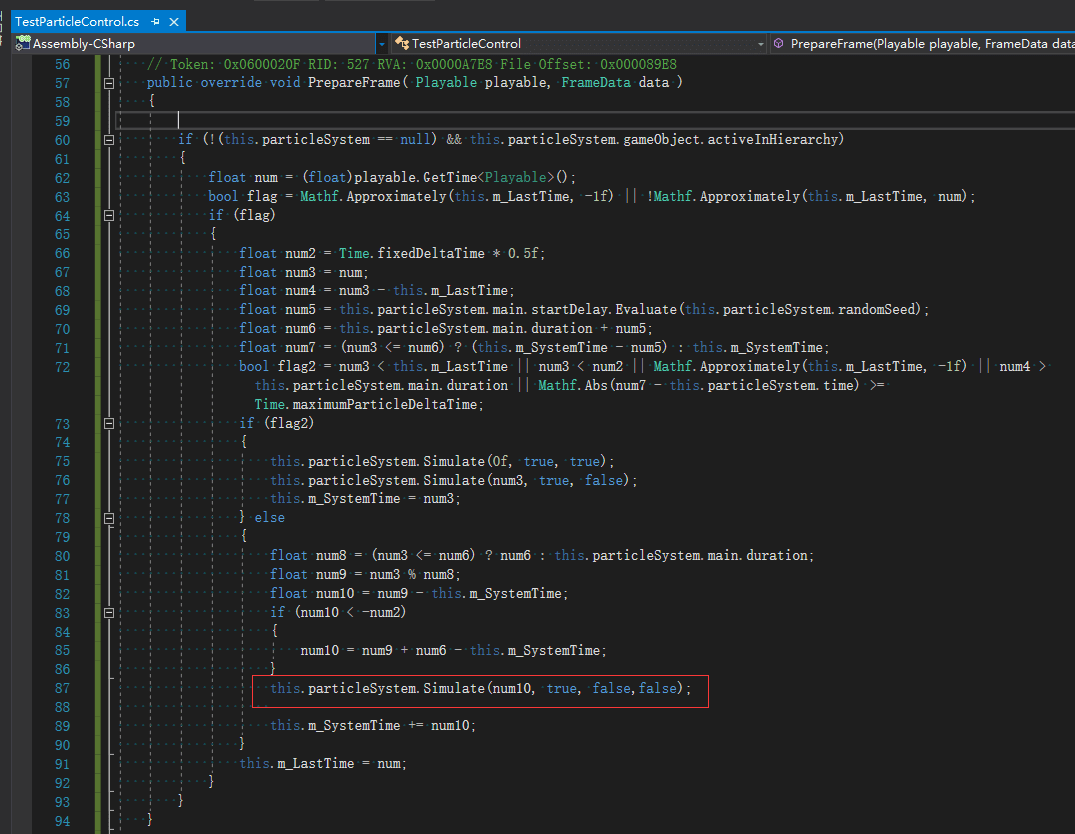
发现最后一个fixedTimeStep参数默认为true。所以在这里更新粒子系统默认就使用了FixedTimestep。把反编译的代码拷贝出来,修改一下类名,自己重写一个播放粒子的轨道和片断,测试即可。
感谢张首峰@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5dc3757c14ec712eefaf0150
Q4:如何保留Stencil buffer的值
请问Unity中Camera的OnRenderImage调用前是不是把stencil buffer的值清掉了?
A:对,Stencil buffer是Depth buffer后8位,opacity画完了就清了。如果你不想清空,有几个办法:
- OnRenderImage逻辑放到Onpostrender里
- OnRenderImage逻辑放到Command buffer里
- 用Command buffer把Depth buffer的内容提前Copy一份暂存(这个套路画Volumetric fog,毛发之类的经常用)
感谢张言丰@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e153e7afd2e373ffa7eaae5
Q5:异步上传管线AUP答疑
对AUP产生疑问,主要目的是想知道是否已经适合在现在的项目里使用了?
目前项目里大部分用的是同步加载,所以应该全部改成异步加载吗?博客里的意思是AUP可以在渲染线程做加载,那如何保证渲染线程不会卡主线程呢?我们使用2018.4版本,如果加载一个角色,除了Texture、Mesh之外,其它的资源还是会走正常的同步加载?这种相对复杂的Prefab加载适合用异步吗?
A1:AUP跟同步/异步加载没关系,只是Texture跟Mesh的加载放到了渲染线程。我这里也是同步加载的,从真机上看到同步记载Texture和Mesh也是走渲染线程。同步加载的时候,不会卡主线程的,这点跟UWA的技术人员确认了。在加载界面的时候,我调大了时间切片耗时。判断机子内存多,加大了加载内存。有一点不明白的是,当Loading界面同步加载非常多的情况下,例如:一帧耗时500多毫秒,相对应的时间切片耗时可以跑到100ms耗时。
感谢剑影蒙残@UWA问答社区提供了回答
A2:回答第一个问题:
正如@剑影蒙残 所说,AUP和加载API的同步加载还是异步加载没有关系。当AUP功能和多线程渲染功能开启后,无论是Load还是LoadAsync,Texture和Mesh资源都是在加载线程加载好后,从渲染线程提交到GPU的。而在没有AUP功能时,这两项资源的GPU Upload都是在主线程完成。这样的好处显而易见,就是将主线程的卡住时间转移到渲染线程进行完成,从而让主线程可以处理更多逻辑事物。
需要注意的是,在2018.3及以后版本中,AUP才支持Texture和Mesh,在2018.2版本中,AUP只支持Texture资源。
回答第二个问题:
确实,当有大量Texture或者Mesh资源需要传输时,渲染线程很可能是吃不消的,但需要考虑加载的时间点,如果是在场景切换时加载,且允许可以存在一定的画面卡住需求,那么可以尝试通过Load API来进行加载;反之,在战斗过程中或者需要平滑加载时,则使用LoadAsync API。二者的最主要区别是在于加载的资源量要不要在下一帧结束前完成。如果需要,则使用Load,Texture和Mesh虽然在渲染线程进行Upload,但一定要在下一帧结束前完成,这样就很有可能会造成主线程的等待,但相较于以前Unity版本,其优点是主线程依然可以执行其它耗时计算,比如UnloadUnusedAssets、配置文件的加载等。
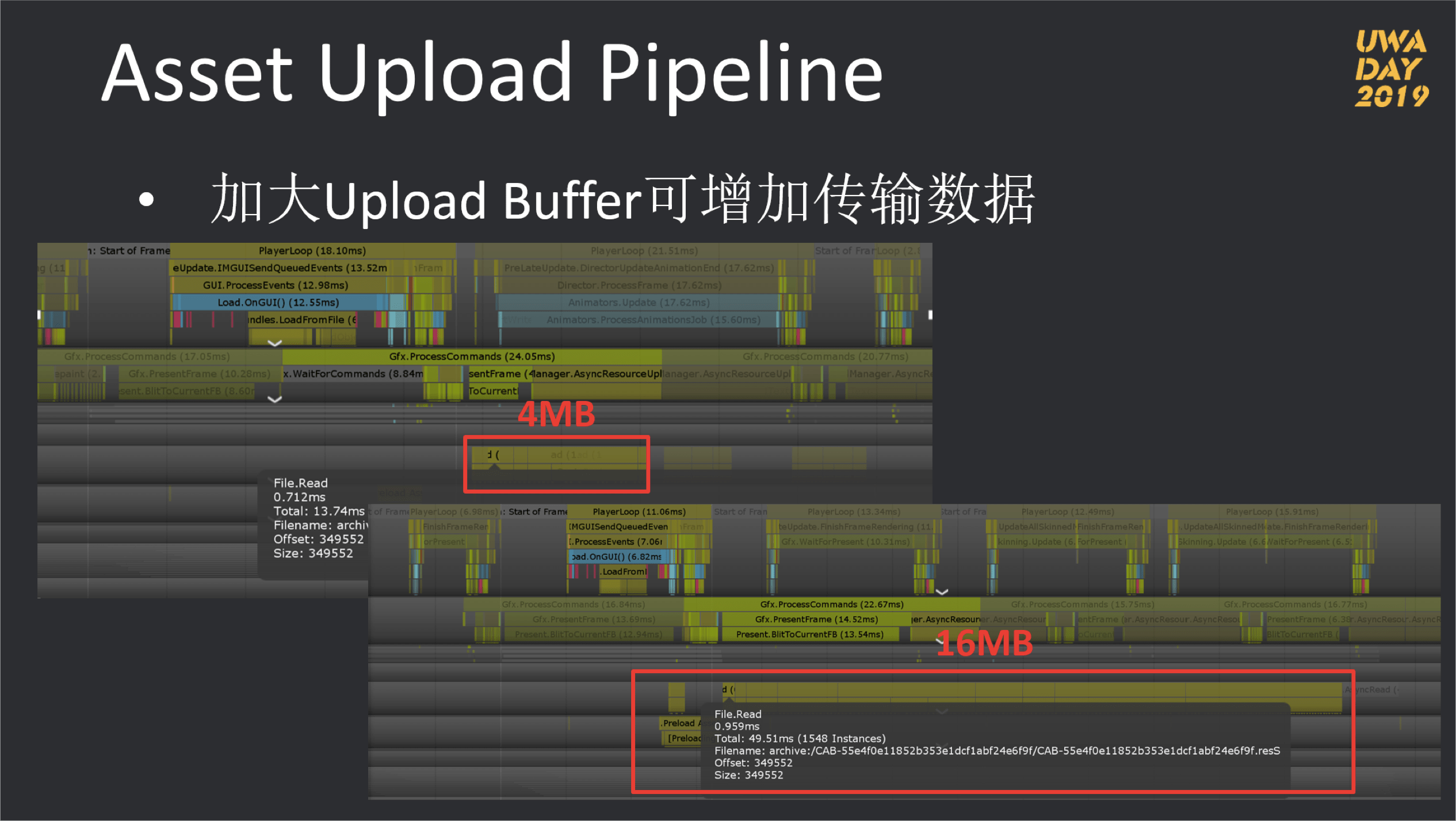
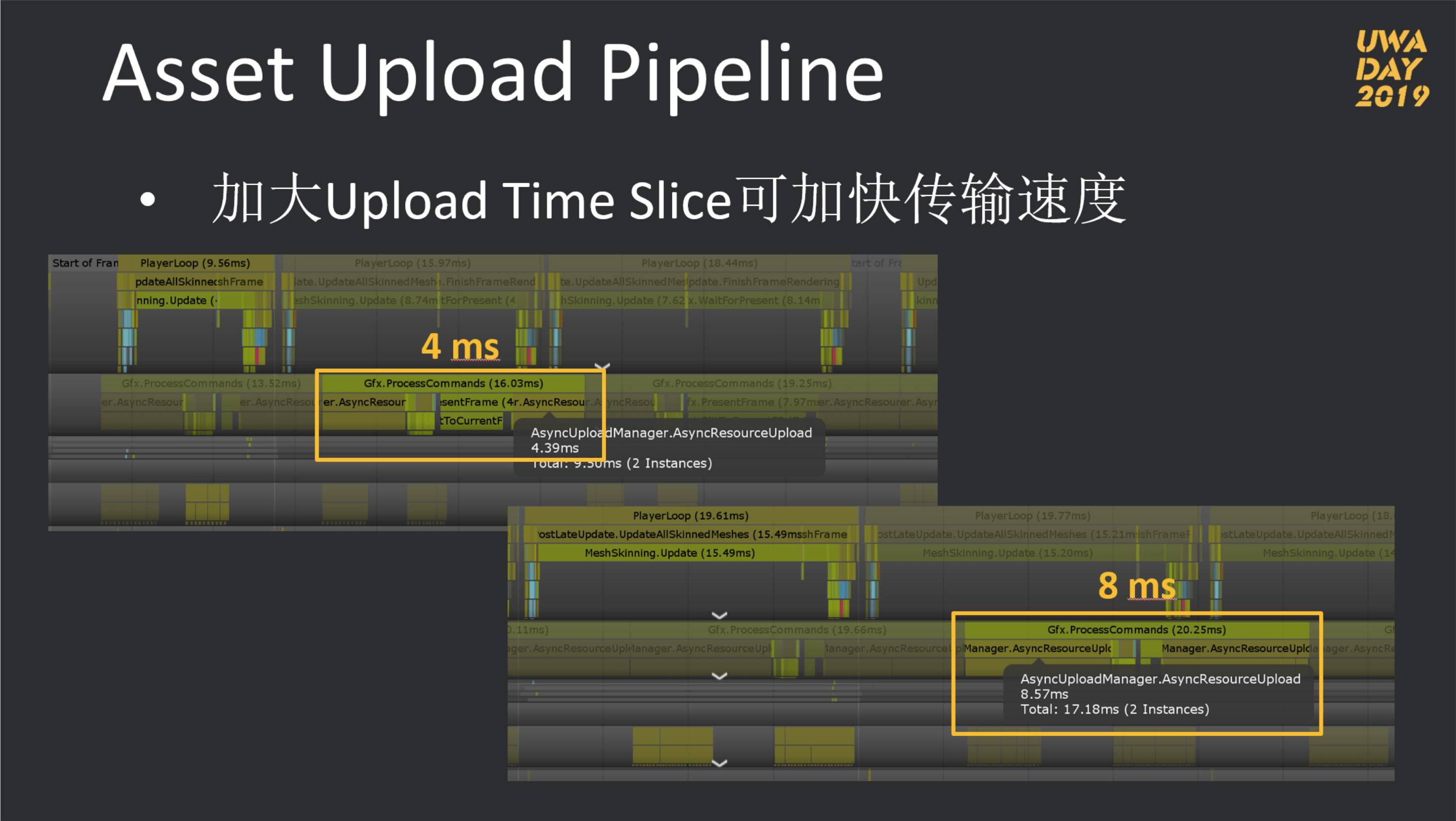
而如果想要尽可能平滑,则Unity引擎提供了AsyncUploadTimeSlice和AsyncUploadBuffer两个参数,虽然在之前的Unity版本中也这两个参数,但经过大量测试下来,并无法像2018.2之后容易控制。
这两个参数一个控制每帧中的Upload最大时间,一个控制每帧中允许Upload的最大数据量,两者相辅相成,控制AUP在每帧中的加载耗时。所以,我们在UWA DAY 2019中也对这两个数值的使用进行了详细说明,如下图所示:
当渲染线程压力较大时,可尽可能控制上述两个参数来降低渲染线程由Upload数据而造成卡住主线程的概率。
回答第三个问题:
其实目前加载一个角色Prefab时,已经可以有很多资源都可以通过异步加载来进行,直接通过异步加载接口调用即可,这个跟AUP就是另外的问题了。AUP指的是Texture和Mesh在提交到GPU时的异步提交操作,其本质是在资源加载之后进行的,也就是说和异步加载是两回事。
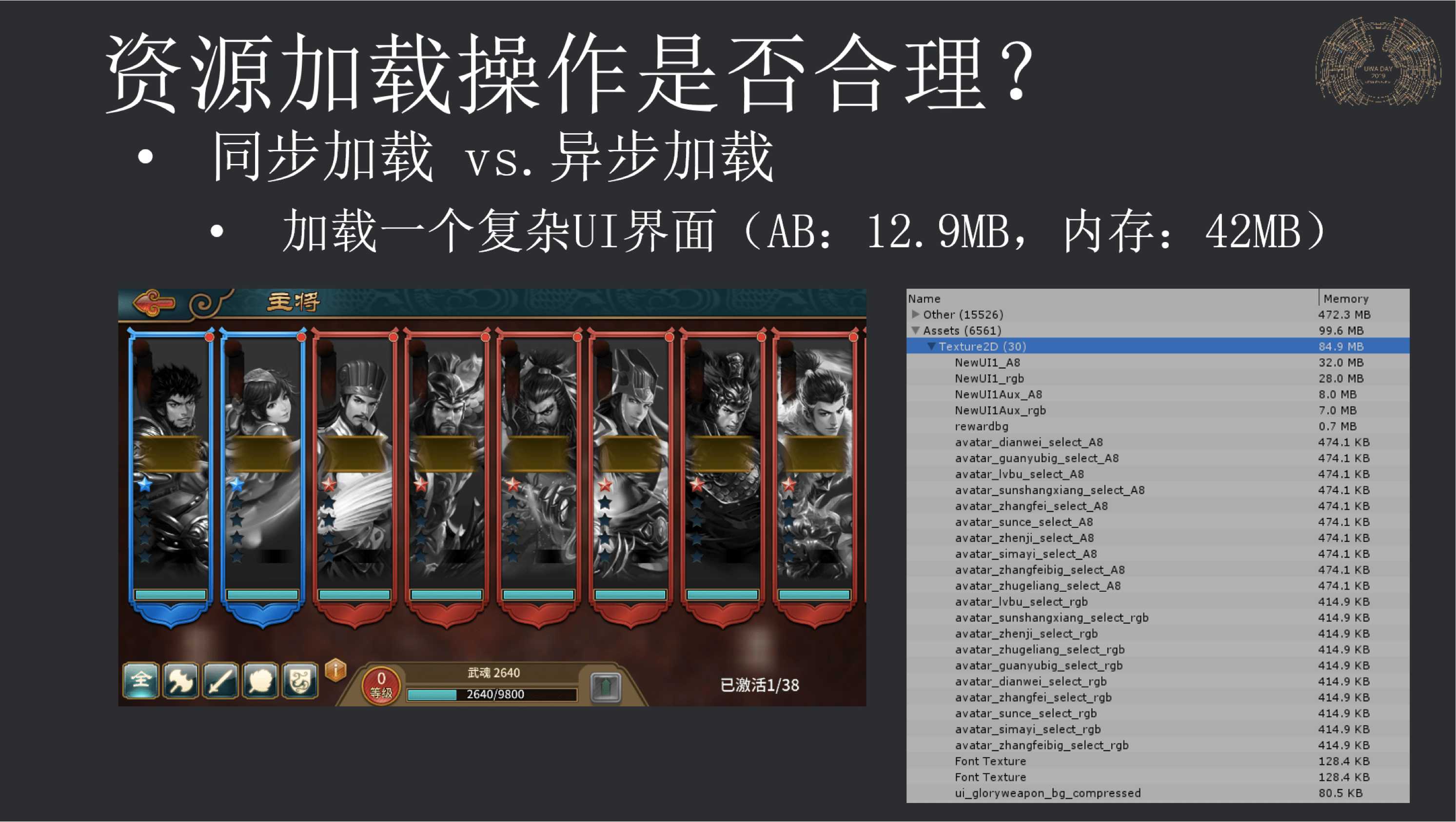
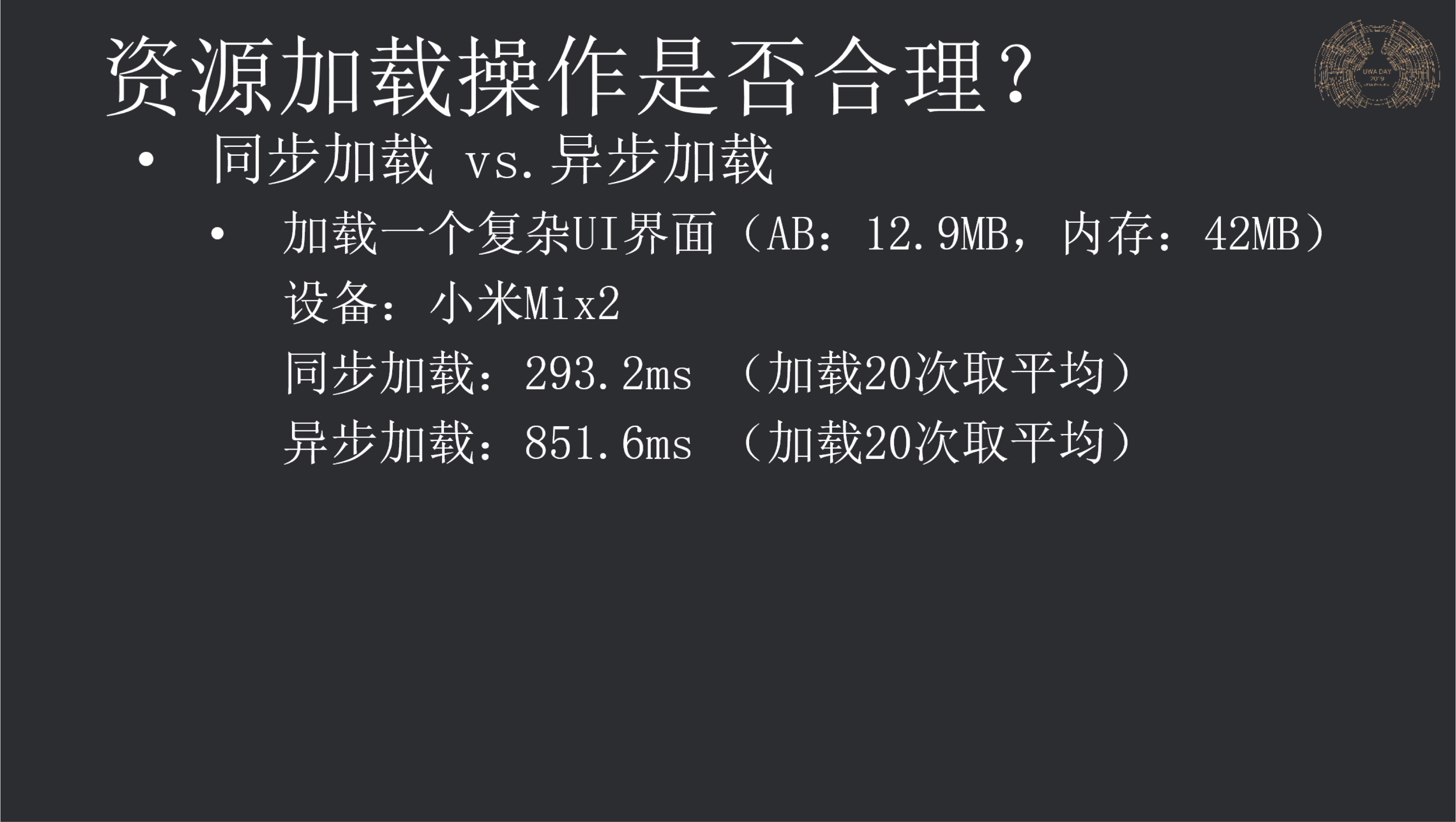
相对复杂的Prefab确实适合来做异步加载,我们曾经在今年UWA DAY上做了一个非常重的UI界面加载测试,如果按照默认设置进行同步和异步加载,则耗时分别为:293ms和851ms,小米Mix2设备上。
而在经过了调整加载策略后,其异步加载耗时可以将为313ms,和同步加载相差很小,但好处是主线程留下来大量的时间来处理其它逻辑操作,且很平滑。
对于UI Prefab如此,对于角色Prefab亦如此。在优化2018.2以后的异步加载时,需要更多考虑如何控制资源在异步加载之后,在主线程的“后加载”耗时。比如,各种资源的AwakeFromLoad和Shader.Parse等操作。对此,我们在《Unity引擎加载模块和内存管理的量化分析及优化方法》进行了详细的分享,有兴趣的朋友前往观看。
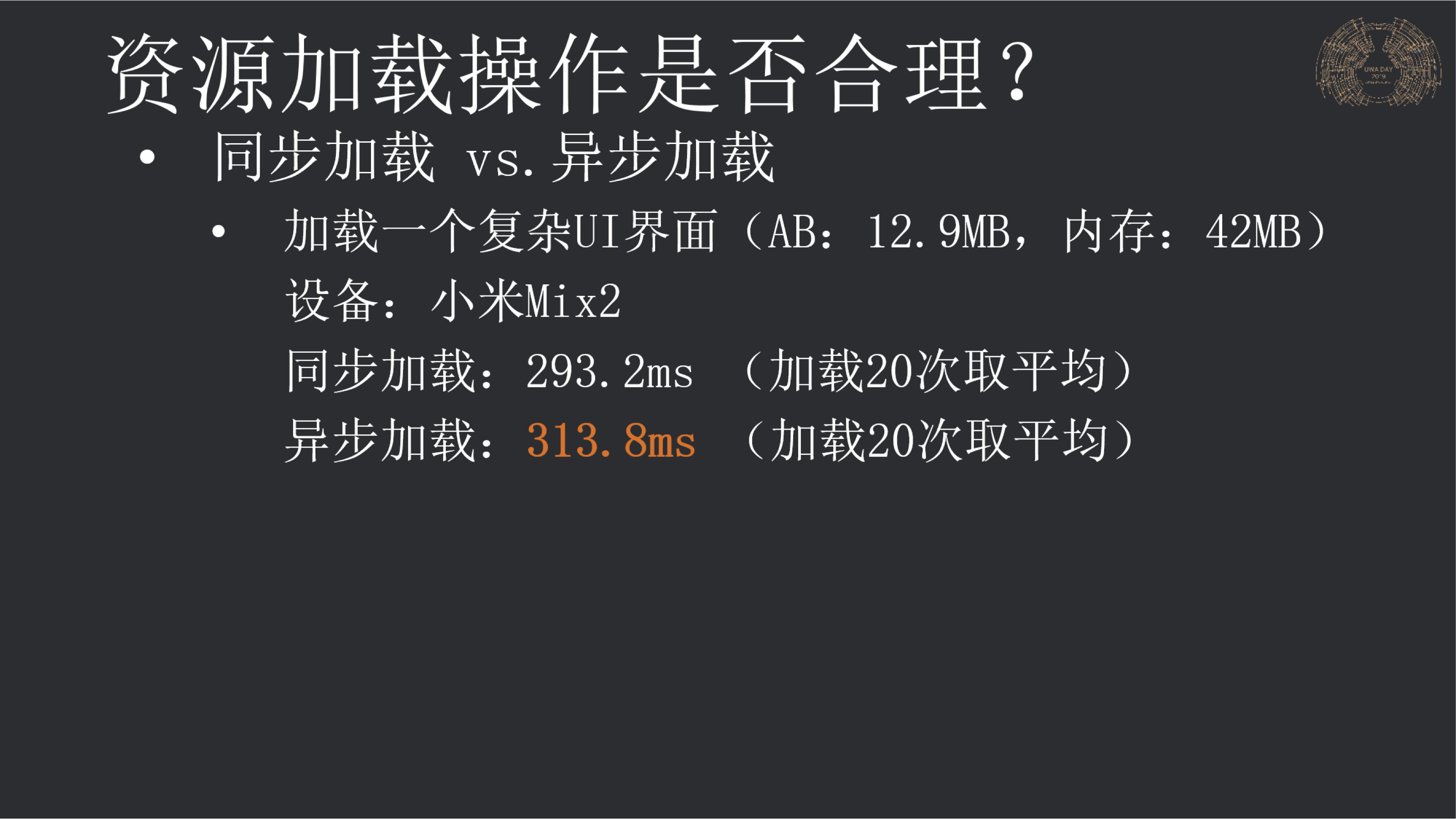
该回答由UWA提供,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d4cf328c494b506d267391e
Q6:UGUI的Outline的替代方案
UGUI的Outline有什么比较好的替代方案吗?有朋友使用过这个吗?效果如何?
有朋友推荐Text Mesh Pro和https://www.oipapio.com/cn/article-8019719,用过的朋友也可以谈下感受,谢谢。
A1:我们项目当时是使用我写的Shader描边的效果,但是并不是使用2个pass而是直接在一个pass里面进行UV偏移描边。在这里,我就描述一下大概的思路,首先重写Text顶点输入,使用它的UV0、UV1 tangent的最后一位w传递描边宽度、描边颜色和描边扩充后的UV、原始UV,然后在Shader里面做解析,反向解出传递过来的信息,然后做UV偏移达到描边效果。可以做到N个Text组件描边颜色不同、粗细不同,字体可以旋转、缩放等,但是不会打断合批。
感谢唐松@UWA问答社区提供了回答
A2:最近没研究Unity,之前看到有类似的问题被回答过。最早的方案实际还是有些问题,后面改进了一下。
思路就是和唐松一样的吧,是参考网上一篇文章再改进的。
或者看这边的一些说明:https://blog.csdn.net/zhenmu/article/details/88821562
感谢真木@UWA问答社区提供了回答
A3:推荐Text Mesh Pro,优势不是一点半点。TextMesh Pro的Text使用了不同的技术来渲染文字,叫做Signed Distance Field。在效率与性能上也有一定的优化。2018的Unity版本已经集成了,之前的版本可以在AssetStore上下载,现在是免费的了。
感谢廖武兴@UWA问答社区提供了回答
A4:UGUI的字体渲染,推荐自己通过FreeType实现,这样阴影和Outline都有比较现成的方案,性能也会比UGUI Text高很多。附带的一个理由是Text会打断Sprite的合批。
感谢cloud@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d580e28c494b506d2673a4f
Q7:Humanoid动画显示与Generic不一致
我们项目中的角色在胳膊上会有一些飘带,有部分角色的飘带在设置成Humanoid之后,会出现奇怪的旋转角度,和Max及Generic下的动画显示不一致。比如Max里K了手臂飘带下垂的动画,Humanoid下两根飘带就会显示成X形交叉。
目前已检查的内容如下:
1、Avatar里面骨骼重定向正常,且为T-Pose,除手臂飘带外,其余骨骼的动画正常。
2、动画导入设置中的mask已勾选全部骨骼。
3、之前认为是手臂Twist骨骼带来的错误,但后来测试无Twist骨骼的情况下动画依然不正常。
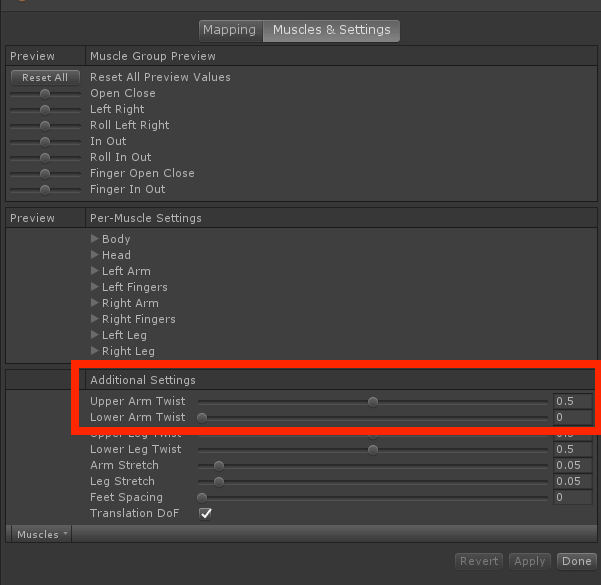
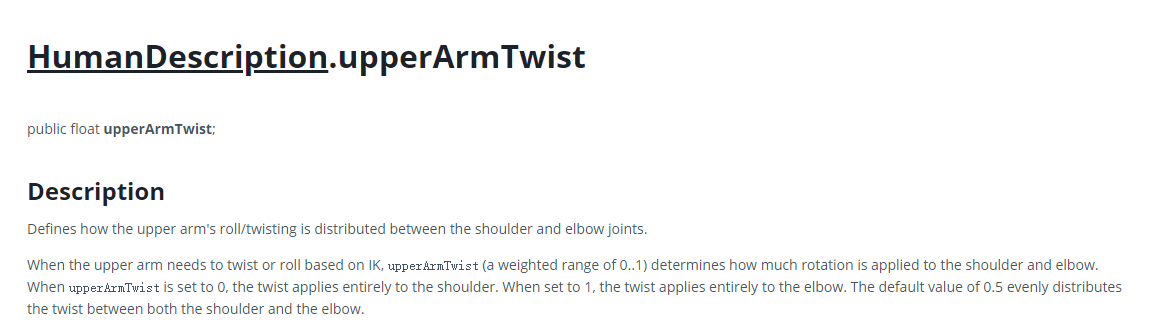
4、Avatar设置中Muscle Setup下,调整Upper Arm Twist参数及Lower Arm Twist参数能够略微修复问题,但无法完全修复,且其他部位动画可能会出现问题。
5、对比两种模式下的Animation文件,发现对应帧的数据存在差异,同一骨骼在同一帧下两种模式的transform值不同。
不知是否有大佬踩过类似的坑?期待大佬解答!
A1:变到Humanoid,骨骼会有空间转换以及中间骨骼的插值,所以可能会造成位置信息的不完全对应。题主的问题最好能传一个示例来看看。或者能否尝试使用额外骨骼来挂飘带,而不是放到Humanoid映射的骨骼上,这样额外骨骼会走Generic,避免受Humanoid影响。
感谢Saber@UWA问答社区提供了回答
A2:题主有没有检查过Avatar的T-pose中手臂飘带的那几根骨骼的位置是否异常?我电脑上的3D Max被卸载了,所以不方便做测试,做Retargeting的时候要注意Unity里的T-pose中有问题的骨骼位置是否和3D Max里的默认pose的骨骼位置一致。
Humanoid类型的动画选择Avatar之后也会改变为存储差异值,这些值是动画里的每帧pose和T-pose的“减法”,然后运行时会将差异值应用于目标模型。在同一个模型身上,理论上结果应该和Generic的完全一致才对,否则应该是动画文件或者模型文件中的某些pose不一致导致的。
我暂时不方便做Demo验证,建议题主拿同一个动画文件导出一个Mesh和一个动画,然后用这组资源进行验证,查看是否可以做到动画效果正确。如果这样可以,那就可以验证我说的内容。
感谢贾伟昊@UWA问答社区提供了回答
A3:目前找到了一个解决方案:
之前有在提问中提到,在Avatar的Muscle Setting中,调整Upper Arm Twist参数及Lower Arm Twist参数能够略微修复问题。后来仔细研究了一下这几个参数,发现可能是我之前的调法有误。
我猜可能是Humanoid不支持Twist骨骼的映射,因此添加了这两个参数来实现手臂上附加骨骼的额外运动。
Lower Arm Twist为默认0.5时,小臂飘带会随手腕有一定旋转
Lower Arm Twist为0时,小臂旋转仅受手肘影响,效果和Generic一致骨骼层级如下:


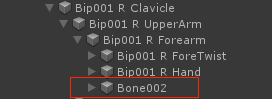
感谢题主王阳@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5cc014b95dad710abee80421
Q8:使用GPU Instancing屏幕花屏问题
机器:魅族MX5
Unity版本:2019.1.5f1
渲染设置:OpenGL ES3,Dynamic Batching,GPU Instancing
问题表现:场景有时候会突然花屏随机闪烁, 通过排除法发现是在渲染其中一个树的时候导致的(树的材质勾选了GPU Instancing,只要不渲染这个树就不闪烁)。

尝试改变渲染设置:仅关闭动态批处理或者GPU Instancing就都不花屏了, 两者同时存在就会花屏。
不知道这是Unity的Bug还是魅族机器有问题。
附件:Demo工程(请戳原问答链接查看)
A:根据题主提供的信息,我们做了以下尝试。
测试机:魅族5;对比测试机:小米6
测试场景:客户提供测试现象:
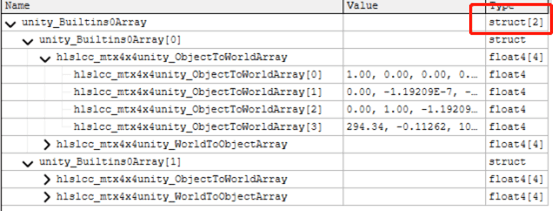
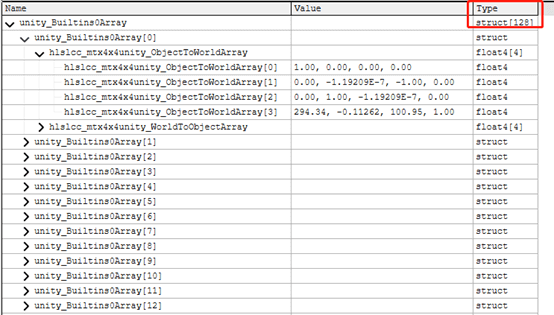
魅族5开启了Dynamic和Instancing,会花屏,UBO数组长度为2,有Log报错。小米6和OPPO K1均不花屏,UBO数组长度均为128,无Log报错。
魅族5在RenderDoc的数据:
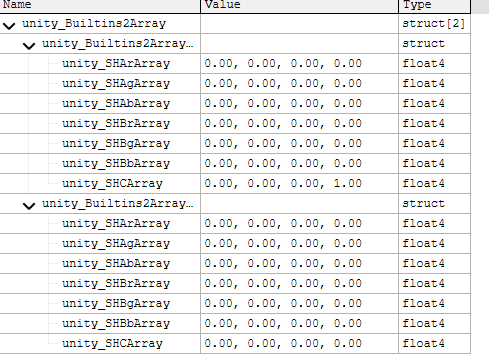
当开启GPU Instancing的时候,在Vertex Shader里面会有2个UBO(Uniform Buffer Object)。
它们的内容分别如下:
第一个记录的是SH函数的系数,第二个是每个Instance的变换矩阵。在魅族5上面数组长度为2,可以理解为魅族5不支持Instance。而在小米6和OPPO K1,是支持128个Instance的,如下图所示:
说明它们是支持Instancing的。
在移动平台上,一个Buffer的大小上限是16KB,一个Instance需要记录ObjectToWorld和WorldToObject的矩阵,总共是16x4x2=128 Byte,所以总的Instance上限数量是16x1024 Byte/128 Byte = 128。
从RenderDoc上的信息里面可以看到确实是长度为128的数组,而在魅族5上面只有2。
而且在魅族5上面运行测试场景的时候,通过Logcat可以看到会有报错的Log:
GLSL: unexpected struct parameter 'unity_Builtins2Array1.unity_SHCArray’
GLSL:unexpected struct parameter 'unity_Builtins0Array1.hlslcc_mtx4x4unity_WorldToObjectArray[这两个正是Instancing需要的UBO里面的数据。
还有一点需要说明的是,在测试场景中,使用的是239个三角形的那个Mesh,在魅族5上面同样会花屏。不论有没有开启Dynamic Batching,都会有上面的报错,所以本质上是魅族5不支持Instancing导致的。
创建了一个场景,场景中有3棵相同的树,而且开始了Instancing,可以看到OpenGL使用的接口是glDrawElements。
在小米6上调用的接口是glDrawElementsInstannced,如下图:
没有对模拟器进行测试,理论上是一样的情况。



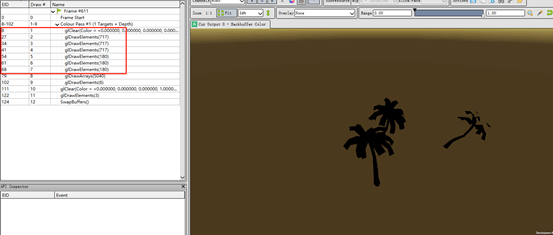
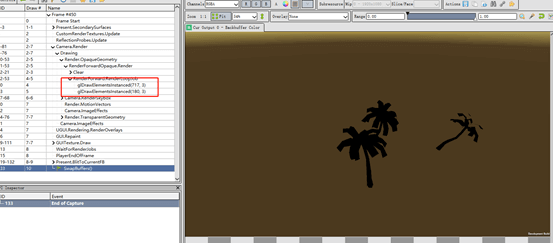
该回答由UWA提供,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5dce374d14ec712eefaf01ae
Q9:LWRP下代码动态更改阴影生成距离
我们项目用的Unity 2018.3.14f1,还使用了LWRP 4.10.0。在代码里想动态设置生成阴影的距离,LightweightRenderPipelineAsset。ShadowsDistance的字段也赋值成功了,但是游戏里的阴影还是没有按设定的距离生效,如果自己手动再去调值就能马上生效。是不是还要有什么激活操作才能使参数生效?代码与截图如下:
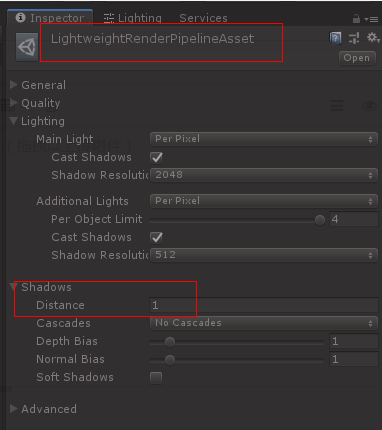

A:它是在CameraData里的,你只有重写LWRP的Render,并另外实现SingleCamera,在里面做赋值操作就可以了。所以,一般项目不是直接用的,应该实现自己的SRP。
感谢Robot.Huang@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5dc3e4b614ec712eefaf0160
Q10:一种Shader变体收集打包以及编译优化的思路
最近在做项目的Shader变体收集,以及Shader打包编译优化相关的内容,我想在此把我实现的步骤尽可能的描述清楚,希望大家帮忙指点一二。
整个模块分了三部分:
- 工程Shader变体的收集
- 把Unity搜集到的变体拆分保存为独立文件,一个Shader对应一个变体集资源,利于打包和后续使用
- 使用Unity 2018的IPreprocessShaders接口,来优化Shader编译时间,这部分还比较新,我感觉自己使用的方法有点歪了
在实现的过程中我遇到下面这些问题:
- ShaderVariantCollection,Unity引入这个东西的实际用意,从官方文档解释来看,主要目的是为了提高预加载的速度,和打包、编译关系不大,江湖上流传的变体打包方法似乎都没有提及
- 用了一些并没有开放的方法来获取变体信息,或许有更好的方法,望告知
- 在变体集的创建过程中,缺失一些信息,我只是简单粗略地做了一些假设
- Unity搜集下来的Shader变体集,并没有区分UsePass、Fallback这类被引用进来的Shader(这些Shader没有出现在工程的任何材质上,故无法搜集),导致接下来的依赖打包会出现变体丢失的风险
- 新的IPreprocessShaders接口,Unity提出这个更多的是为了配合SRP。我对它的使用方法,是我拍脑袋想出来的,实际效果似乎也有,但没有特别明显
思路的详细描述以及可用的部分代码在这里:https://lab.uwa4d.com/lab/5da960aa8bab6aaf02ba0116
A1:关于题主的几个问题:
在设备上Shader的加载其实并不慢,通常慢在编译上,也就是Warmup做的事情。因为不同设备GPU以及驱动不一样,因此手游上的Shader是没办法在打包的时候编译的,这就需要到设备上进行编译。(说到这个,我其实也不是很清楚在打包过程中观察到的Shader编译是在干嘛。大约是把Unity自己的Shader格式转换成目标平台的Shader格式,比如GLSL等,这也的确是一种编译。)ShaderVariantCollection要能够有针对性地提预热(提前编译)Shader,自然是要在打包的时候根据需求收集可能用到的变体,这就和打包有了关系。至于编译,就像前面所说,打包时需要转换,到设备上才真正编译Shader。
暂时我也不知道更开放的方式获取变体信息,编辑器下用些反射方法属性什么的都正常,毕竟没有源码。
其实要做完整收集挺难的,除了你文章中列举的那些坑之外,高中低配置导致代码来动态更改的宏同样需要收集对应的变体,对于这部分,也只能做一些假设,如果一定要预热所有可能,还要把它们加入到变体列表中,这也可能导致你Warmup的内容其实并不是本次运行一定要的。
Fallback的Shader应该是可以正确收集的,至于对应的变体我还真没注意过。话说后来我们项目主要的Shader都不使用Fallback,或者Fallback到我们自己的一个默认简单Shader中,这样会好办一些,大不了这个Shader就AlwaysInclude都可以。
新的接口还真没用过,想来这个的确可以用来做一些事情。在优化Shader编译时间方面,大的多变体Shader在打包的时候的确有很长时间的编译,比如Standard。但感觉Unity默认应该就会根据需要的进行处理,比如Standard Shader,如果你放置到AlwaysInclude下,你一次打包要编译超久(1个小时甚至更多),不放置在AlwaysInclude下只自己打包,编译时间就不会很长,说明这里也是按需编译的。不过这只是我个人依据经验的猜想,未必正确,你可以找一个复杂Shader做下实验对比,看看能够优化到什么程度。
说到底,想要完美地收集所有可能用到的Shader,其实未必是一件能够实现的事情,我们最初也想做到运行时没有CreateGPUProgram的消耗,但是最后发现还是有很多妥协,比如高低配对应的Shader如果都做预热,就会有很多无效的消耗,而不做高低配的预热,玩家切换配置或者某些低配模式显示角色需要高配效果的时候就会有卡顿。
因此最终的效果还是要经过真正项目的验证,根据Profile统计的结果进行权衡和迭代,才能得到和这个项目匹配的最佳答案。
感谢贾伟昊@UWA问答社区提供了该回答
A2:首先纠正一个概念错误:Unity在打包的过程中确实并非把Shader编译为目标平台的着色器代码,而是一种代码转换:CG -> GLSL,或 HLSL -> GLSL 等等这种能够被目标机器编译的着色器源码,实际运行时才通过CreateGPUProgram创建实际着色器程序对象,就像C#的IL代码被JIT编译一样,一次编译到处运行。
我其实都还没考虑到真正在实机上的预热操作,仅仅想先保证搜集到的变体集完整。如果考虑到更多为机型适配编写的SubShader的变体,我想可以在编辑器上切换下渲染等级开关,然后再次全盘收集一次,保存成为另外一个大的集合。
Fallback我们确实也不怎么用它,代码都走到这里了,渲染效果够不够好已经不重要了,为的更多的是一种诊断行为,我们可以更容易的从外观识别这些物体,然后根据后续的修复,防止代码走到Fallback来。但是UsePass是一个复用代码的好东西,我觉得应该多用。
期待UWA和更多的朋友分享IPreprocessShaders这个新接口的使用心得。
最终,目前来说想要完美收集变体,以及能够在运行是精准预热Shader代码,不是容易的事情,需要反复的Profile和迭代,才能逐渐缓解这些运行时的遗漏。可能未来Unity会开放一些在运行时获取更多Shader加载信息的接口(比如变体信息,变体匹配规则,变体的Pass归属等),我们可以更有针对性地处理Shader的预热问题。
详细可以参考文章:《一种Shader变体收集打包以及编译优化的思路》
感谢题主lujian@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5da86670e84db43d6efbda72