
Compute Shader次世代优化方案
- 作者:admin
- /
- 时间:2019年01月22日
- /
- 浏览:14064 次
- /
- 分类:厚积薄发
本文章标题来源于AMD在4C上的一个演讲: Compute Shaders: Optimize your engine using compute(3).
概念
Compute Shader是在GPU上运行的程序。虽然是老生常谈了,但是我们还是要先介绍一下GPU。 众所周知,CPU和GPU是两种不同的架构,那么他们之间的区别是什么?
1.CPU是基于低延迟的设计
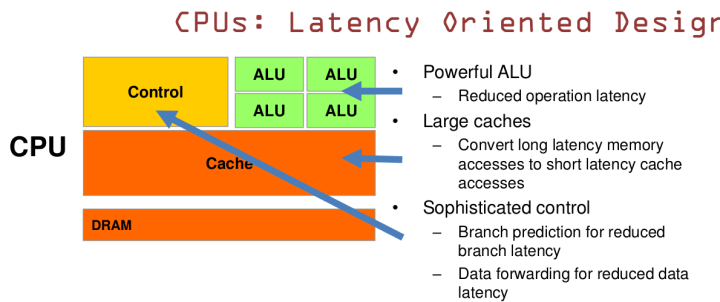
CPU有很强大的算术逻辑单元,减少操作延迟;巨大的Cache,为了降低内存访问的延迟;复杂的控制器,使用分支预测来减少分支延迟,使用数据转发减少数据延迟。
我们可以这样说:CPU擅长逻辑控制和串行的运算(1)
2.GPU是基于大吞吐量的设计
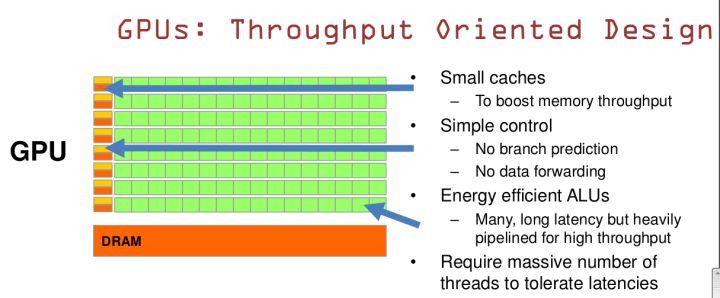
GPU有小的Cache,用来促进吞吐量;简单的控制,没有分支预测和数据转发;高效节能的ALU,很多延迟很长的ALU,但是为了高吞吐量被重度管线化;需要开启大量的线程才能降低延迟。
相应地,我们可以这样说:GPU适用于计算密集型和易于并发的程序(1)(2)。
3.GPGPU
可以看出,CPU和GPU各有自己的擅长,那么我们可以将二者结合起来,使用CPU做串行,而使用GPU做并行。这种技术就叫做GPGPU,也就是利用GPU进行通用计算的技术(General Purpose Computing on GPU)(1)。

但是,我们知道,通常来讲,GPU是用来执行图形渲染的。那么,为了执行通用计算,NV推出了CUDA,Khronos推出了OpenCL,Microsoft推出了DirectCompute,也就是后来的Compute Shader,然后,各种图形API也相继推出了CS。(25)
4. 支持Compute Shader的图形API

DX虽然从10开始支持Compute Shader/Direct Compute,但是限制比较大。DX11的Compute Shader拥有更强大的功能(当然肯定还有DX12)(6)。所以我们一般在Unity中使用CS,还是要求Shader Target4.5(也就是Shader Model 5)(19)。
OpenGL从4.3开始支持CS(但是MacOSX不支持4.3)。ES从3.1开始支持CS(5)。
Metal和Vulkan都支持CS(4)(7)。
另外PS4和Xbox one(DX11.2)也支持CS(19)。
5.Compute管线与图形管线的对比
我们通过几张图,来简单对比一下计算管线与传统图形管线有什么不同。

我们可以看到,计算管线变得很简单(3)。
(关于GPU Rendering Pipeline,可以参考这张图(14) :http://t.cn/E5RqIWp)
{kind=link}
从硬件端来看:
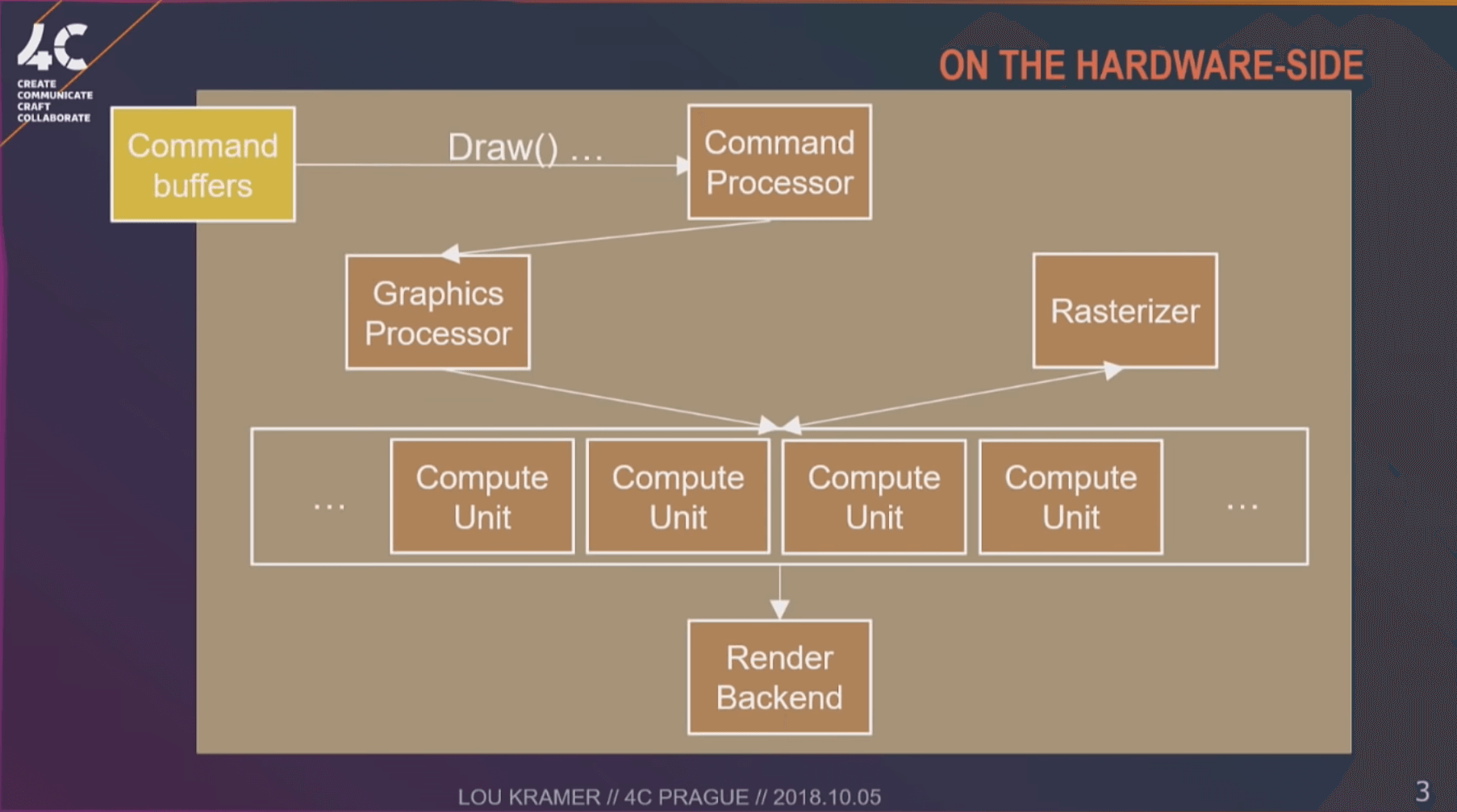
上图是图形管线在硬件端的工作流程(3)。
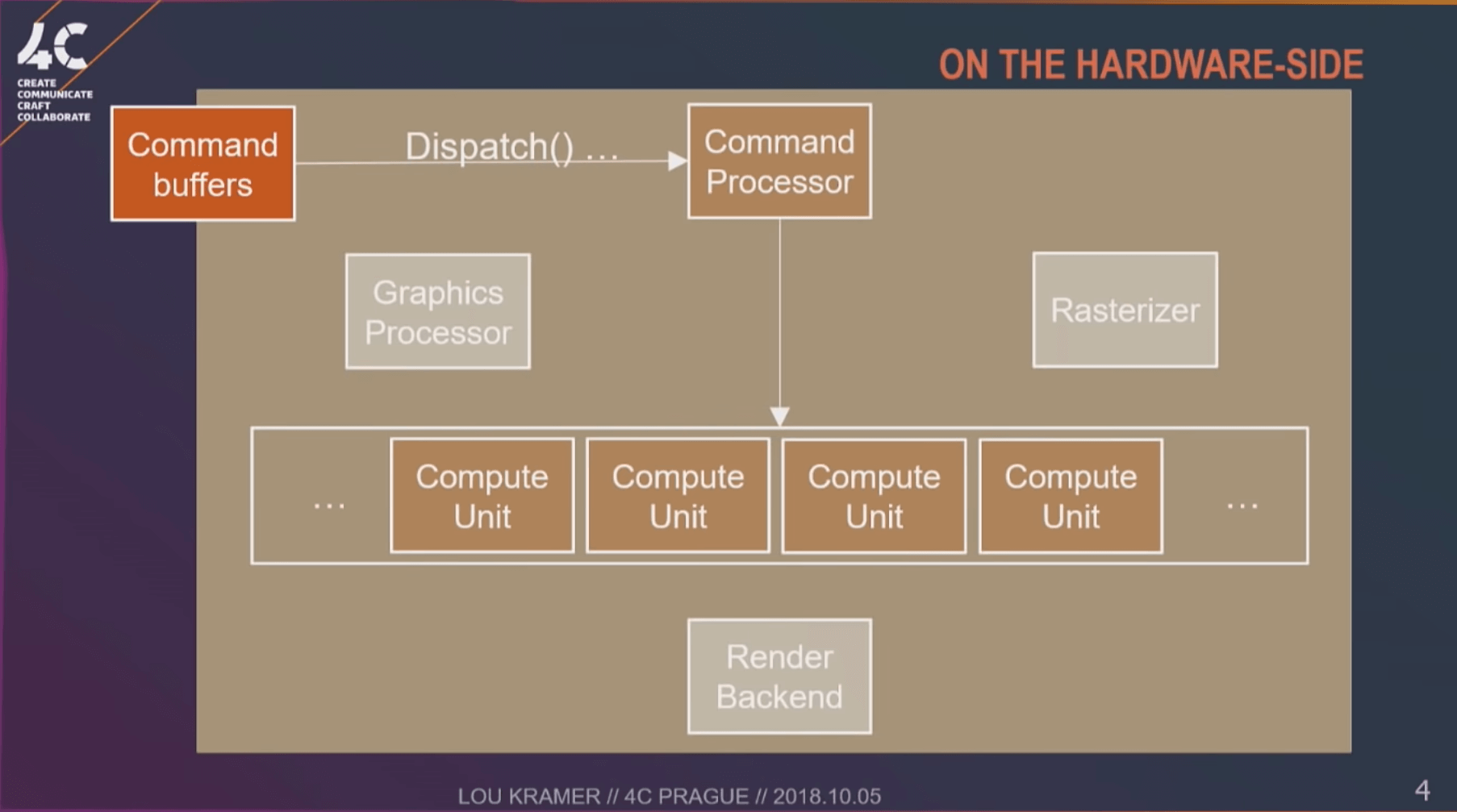
上图是计算管线在硬件端的工作流程(3)。通过对比,我们可以看出:Compute Shader可以在不通过渲染管线的情况下,利用GPU完成一些与图形渲染不直接相关的工作,从而降低硬件的Overhead。这就是Compute Shader的优势。
语法
1.如何在Unity里使用Compute Shader?
上文中介绍了,目前有很多图形API支持CS,但是各种API的Shading Language语法和API各不相同。Unity的ShaderLab采用了跟HLSL接近的API,方便我们编写Shader。
2.Kernel
如果我们在Unity里面新建一个CS,便是如下的代码(稍作修改)。
1// test.compute
2#pragma kernel FillWithRed // 1
3
4RWTexture2D<float4> res; // 2
5
6[numthreads(8,8,1)] // 3
7void FillWithRed (uint3 dtid : SV_DispatchThreadID) // 4
8{
9 res[dtid.xy] = float4(1,0,0,1); // 5
10}
这是一个简单的Compute Shader示例,将一个RT填充成红色。
1)首先声明了一个Kernel,Kernel相当于一个main函数,是CS的入口。这应该是来源于Metal的思路(7),可以在一个资源文件里定义不同的Kernel方法,公用一些代码,同时也可以做到相对独立。
2)然后声明了一个RWTexture2D,对应于C#,是RenderTexture。
3)在函数名上面还有一个numThreads的attribute,这个我们后面会讲到。
4)函数的参数后面带有一个Semantic(SV_DispatchThreadID),这个我们后面也会讲到。我们暂时可以把它当作一个坐标值。
5)最后是函数体,是将RT中的像素设置成红色。
3.Dispatch
如何执行这样一个CS代码?在C#里,调用如下代码。
1public void Dispatch(int kernelIndex,
2 int threadGroupsX,
3 int threadGroupsY,
4 int threadGroupsZ);
在CPU端,我们可以通过这个接口,将CS Dispatch出去。Dispatch就相当于Drawcall,但是没有Draw。 其中KernelIndex可以通过ComputeShader.FindKernel来获取。而ThreadGroupsXYZ代表线程组的数量。 那么什么又是线程组?
4.线程组

在CS里面,线程可以分为三个维度(2)。
上图中,最右边的表示单个线程,最左边的表示一个Dispatch,而图中间的,表示一个Thread Group。
Thread Group是指将多个线程组合成为一个Group,在这个Group里面,每个线程有自己的相对位置。Group内,还可以使用共享变量,相互通信。将numThreads这个attribute声明在Kernel函数的前面,就表示一个Thread Group中有多少个Thread。
如图所示一个Dispatch中有3x2x3个Thread Groups,而一个Group中有4x4x2个Thread。这样做的好处一个是可以利用GPU的warp/wavefront/EU-thread(2)(3)。
另外,举个例子,现在很多图像压缩算法都是基于Block的,而Thread Group(OpenGL里叫做local size)可以为图像数据的一个Block的大小(例如8x8),Group数量可以是图像的尺寸除以块的尺寸。每个块被当作一个单独的Work Group来处理,并且Group内可以共享一些信息(5)。更进一步的,我们可以看下图(6)。
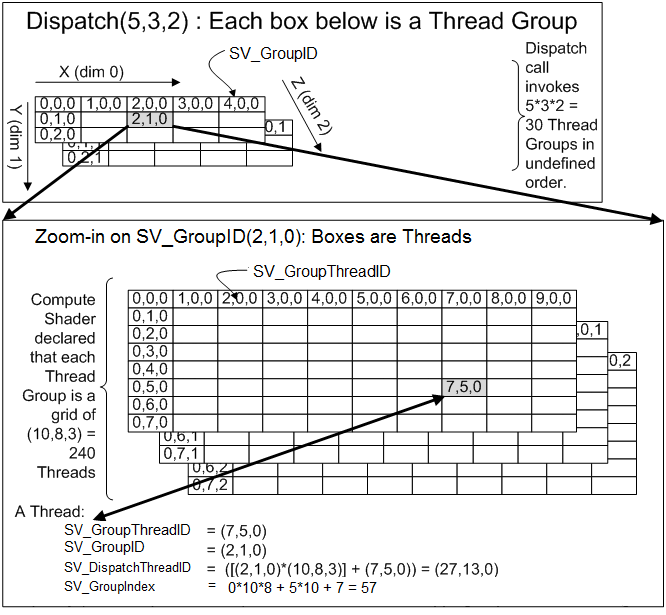
上半图代表了一个5x3x2的Dispatch,图中的坐标代表一个Thread Group。接着,将2,1,0的Thread Group打开,我们可以看到下半图。这张图代表了一个10x8x3的Thread Group,图中的坐标代表了一个Thread。
如图所示,我们可以根据这些坐标算出GroupThreadID,GroupID,DispatchThreadID和GroupIndex。这些ID一般是用来作为索引来获取Buffer、Texture或者Thread Group Shared Memory里的数据。
例如上面举的例子,GroupThreadID就是图像的Block内的坐标,GroupID是图像按块划分的坐标(图像的尺寸除以块的尺寸),而DispatchThreadID是像素的坐标。
5.Buffer & Texture
CS可以使用一些常规的类型,标量、向量、矩阵、纹理、数组等。
除此之外,为了更灵活的使用CS,还推出了StructuredBuffer,简称SBuffer。
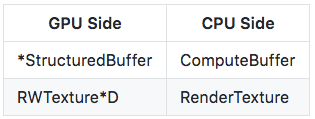
(SBuffer在FS里也可以使用,在其他Shader里也可能可以使用。)
StructuredBuffer还包括:
- RWStructuredBuffer
- RWStructuredBuffer with counter
- (RW)ByteAddressBuffer
- AppendStructuredBuffer
- ConsumeStructuredBuffer
StructuredBuffer除了可以包含各种内置的类型之外,还可以包含自定义的Struct。
6.GroupShared
使用GroupShared可以将一个变量标记为组内共享(又叫TGSM(2))。
使用这种变量,就可以在Thread Group内进行通讯。
例如,我们可以在Forward+/Deferred管线里使用Compute Shader对点光源进行剔除。这个是在战地3中使用的技术(16)(21)。
7.Barrier
当我们在不同线程访问同一个资源的时候,我们需要使用Barrier来进行阻塞和同步。
分为以下两种:
GroupMemoryBarrier
DeviceMemoryBarrier
AllMemoryBarrier
DeviceMemoryBarrierWithGroupSync
GroupMemoryBarrierWithGroupSync
AllMemoryBarrierWithGroupSync
GroupMemoryBarrier是等待对GroupShared变量的访问。
DeviceMemoryBarrier是等待对Texture或Buffer的访问。
AllMemoryBarrier是以上两者的和。
*WithGroupSync版本是需要同步到当前指令
8.Interlocked
原子操作,不会被线程调度机制打断。
InterlockedAdd
InterlockedAnd
InterlockedCompareExchange
InterlockedCompareStore
InterlockedExchange
InterlockedMax
InterlockedMin
InterlockedOr
InterlockedXor
但是只能用于int/uint。
例如可以用于计算灰度直方图,用于Tonemapping\Auto Exposure等效果(19)。
9.平台差异
虽然Unity帮我们做了跨平台的工作,但是我们仍然需要面对一些平台差异。
1)数组越界,DX上会返回0,其它平台会出错。
2)变量名与关键字/内置库函数重名,DX无影响,其他平台会出错。
3)如果SBuffer内结构的显存布局要与内存布局不一致,DX可能会转换,其他平台会出错。
4)未初始化的SBuffer或Texture,在某些平台上会全部是0,但是另外一些可能是任意值,甚至是NaN。
5)Metal不支持对纹理的原子操作,不支持对SBuffer调用GetDimensions。
6)ES 3.1在一个CS里至少支持4个SBuffer(所以,我们需要将相关联的数据定义为struct)。
7)在渲染管线中,部分号称支持es3.1+的Android手机只支持在片元着色器内访问StructuredBuffer。
10.性能优化
另外,在使用CS的时候,我们还需要知道一些性能优化点。
1)尽量减少Group之间的交互:硬件不支持全局同步(2),不同步的话容易导致错误和崩溃(3)。
2)GPU一次Dispatch会调用64(AMD成为wavefront)或32(NVIDIA称为warp)个线程(这实际上是一种SIMD技术),所以,numThreads的乘积最好是这个值的整数倍。但是Mali不需要这种优化(8)。此外,Metal可以通过API获取这个值(7)。
3)避免回读:回读操作在渲染管线中使用的比较少,而在CS中可能会被用到,所以重点提一下(20)。
4)避免分支,重点避免在Thread Group中间的分支,这其实跟第二点是相关的,如果在wavefront/warp整数倍的地方发生分支,消耗就会小很多(2)(26)。
5)尽量保证内存连续性(2)。
6)使用[unroll]来打开循环,有些时候需要手动unroll(22)。
还有一些在渲染管线中适用的Tips这里没有列举出来。
应用
那么介绍过CS之后,我们看看,目前都有哪些应用。
1.GPU Particle System

图为用CS实现的GPU粒子系统,这个功能中使用CS计算粒子的运动轨迹(10)。
2.GPU Simulation

图为布料模拟,使用了CS进行布料粒子的受力运动计算、碰撞检测和反馈,以及约束计算。类似的还有头发模拟和海水模拟(11)。
3.Image Processing

图为一个简单的去色的图像处理(12),将RGB与(0.299,0.587,0.114)进行Dot,获得灰度值(24)。类似的还有eye adaptation, color grading等等(3)。
Unity的PPS2中使用的Histogram就是一个很好的例子,几乎用到了CS的所有Feature(23)。
4.Image Compression

图为ASTC算法压缩过的图像(4x4 6x6 8x8)(13)。 上面提到过,我们可以使用CS来实现基于Block的纹理压缩算法。
5.Tessellation
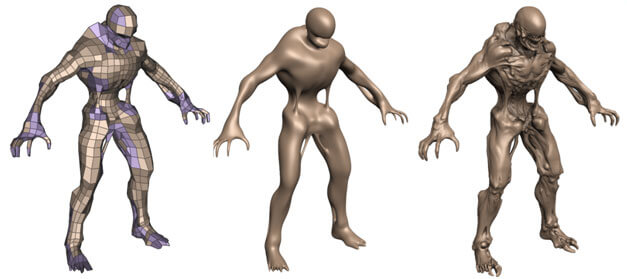
曲面细分(15)默认管线中的Tessellation比较受限,虽然可以使用Displacement Mapping来提升它的效果,但是仍然不够动态。我们配合CS一起使用,我们可以配合一些逻辑更自由更动态的生成细分顶点(14)(3)。
6.Local lights culling

战地3中,使用的是Deffered Shading Pipeline,通过CS对点光源、探照灯等光源进行剔除(16)。
7.Occlusion culling

图片来源,知乎大V MaxwellGeng实现的GPU Occlusiong Culling,他使用了Hiz的方法,对Cluster进行遮挡剔除(17)。而这种思想就是GPUDRP。
8.GPU Driven Rendering Pipeline
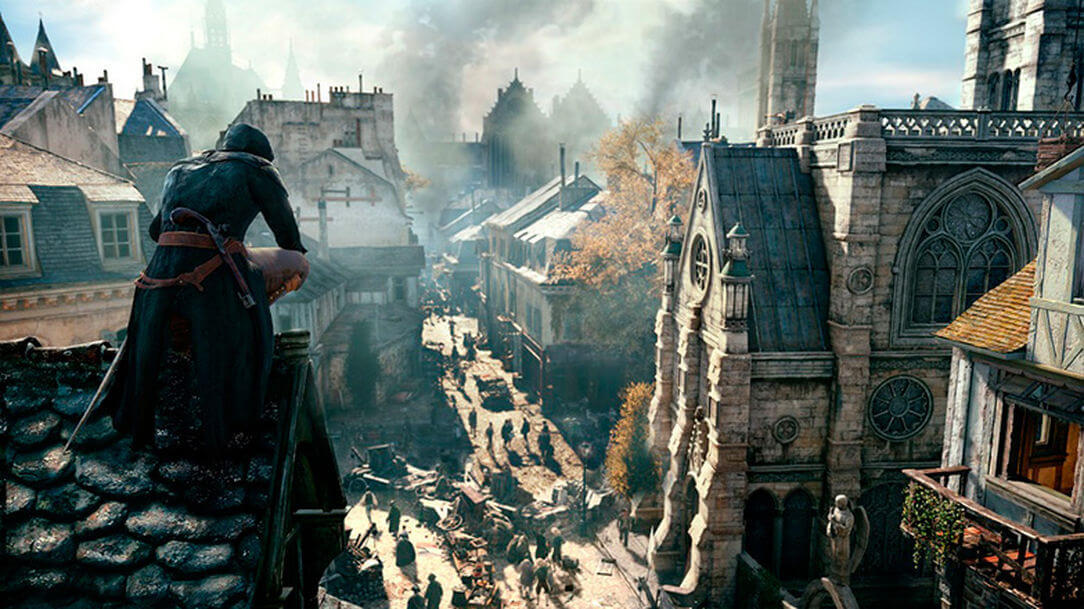
图为刺客信条大革命,在这部游戏中使用了GPUDRP技术,并在Siggraph 2015: Advances in Real-Time Rendering in Games course中发表(18)。
还有很多很多……
Simple, but not easy.
“Simple, but not easy”是我对Compute Shader的认识,也是对本文的总结。ES从3.1开始支持CS,也就是说,在手机上的支持率并不是很高。
另外,手机算力还是很低。GTX 1050 Ti的算力是1.9k~2.9k Gflops(floating point operations per second),有768个core。华为P20的Mali-G72 MP12的算力是300+ Gflops,只有12个core(28)。
所以,CS在手机上的使用,是困难的。但是,我认为它是有巨大潜力的,随着手机硬件的高速发展,我相信,用不了多久,Compute Shader的使用就可以在手机上普及。

引用
1)Graphic Processing Processors (GPUs) Parallel Programming
2)DirectCompute Optimizations and Best Practices
3)Compute Shaders: Optimize your engine using compute / Lou Kramer, AMD (video)
4)Introduction to Compute Shaders in Vulkan
5)Compute Shader(OpenGL)
6)Compute Shader Overview(Direct3D 11)
7)About Threads and Threadgroups(Metal)
8)ARM® Mali™ GPU OpenCL Developer Guide(Version 3.2)
9)Real-Time Rendering 3rd Edition. Chapter
10)GPU Particles (Github)
11)GPU Cloth Tool
12)Compute Shader Filters
13)Adaptive Scalable Texture Compression
14)Introduction to 3D Game Programming with DirectX 11
15)DirectX 11 Tessellation (NVIDIA)
16)DirectX 11 Rendering in Battlefield 3
17)Hi-Z GPU Occlusion Culling
18)GPU-Driven Rendering Pipelines
19)https://docs.unity3d.com
20)Problems with ComputeBuffer Readback
21)Volume Tiled Forward Shading (Github)
22)Low-level Shader Optimization for Next-Gen and DX11 (ppt) (video)
23)Post-processing Stack v2 (Github)
24)数字图像处理(冈萨雷斯)
25)General-purpose computing on graphics processing units (Wikipedia)
26)全局光照技术:从离线到实时渲染
27)Mythbusters Demo GPU versus CPU ( NVIDIA )
28)Glops
这是侑虎科技第498篇文章,感谢作者凯奥斯供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://zhuanlan.zhihu.com/commentsofchaos,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!