
分享一次查找GfxDriver内存暴涨的经历
- 作者:admin
- /
- 时间:2022年09月29日
- /
- 浏览:4451 次
- /
- 分类:厚积薄发
前言
网上有很多有关内存的优秀文章(比如《Unity游戏内存分布概览》),看完后收益颇多,总感觉对内存(比如PSS的分布)已经了如指掌。直到最近遇到游戏中播放奥义导致GfxDriver内存暴涨500MB左右的问题,才发现之前的“了如指掌”到真正解决问题之间,还有一段路要走。这段路,就是理论到实践过程中的方法论,而这方法论,或多或少是有迹可寻的。因此借这个机会,尝试去总结一下,同时分享给大家,欢迎讨论。
“分享一次查找GfxDriver内存暴涨的经历”这个标题,其实是取自UWA上的一篇分享。正所谓“幸福”(GfxDriver内存暴涨)是类似的,但各有各的“不幸”(暴涨原因不尽相同)。好了,废话不多说,让我们进入正题。
问题描述
某个角色进入战斗后,只要释放奥义,PSS瞬间暴涨接近500MB,如下图所示:PSS直接从1228MB涨到1724.19MB,并且瞬间到达峰值后又会回落一部分,直到维持在一个高位。
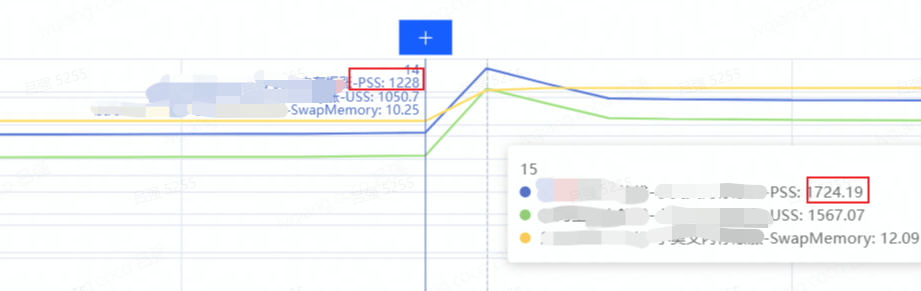
从上图中我们可以看出两个问题:
- PSS瞬间暴涨
- PSS到达峰值后又会回落一部分
问题定位
1. 初步定位
1.1 缩小范围
通过以上的问题描述,首先通过简单的测试缩小问题范围:
1)是否跟设备兼容性有关
2)是否跟后效有关
3)PSS暴涨的大头部分在哪里
对于第1条和第2条,自测或请QA帮忙能够很快定位:这是个通用问题且跟后效无关;对于第3条,我的方法是使用以下三个工具进行组合判断:
1)GamePerf(或者UWA、PerfDog、UPR等都可以)
2)ADB shell dumpsys meminfo
3)Unity Profiler
下面详细解说一下:
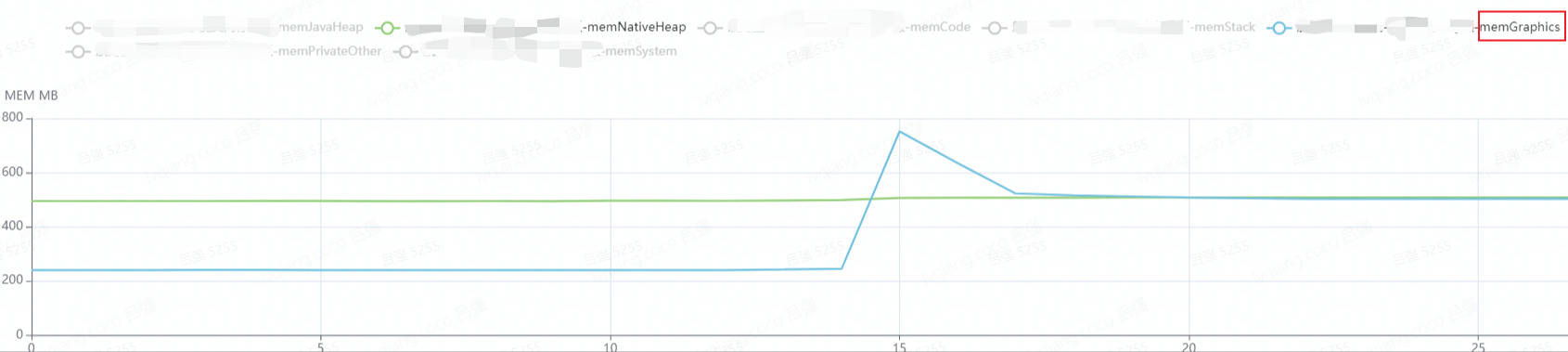
- 从GamePerf报告分析初步判定是显存部分增长过快,如下图所示:
- 与此同时,使用dumpsys meminfo查看播放奥义前后两次PSS的快照,这样能够大体定位问题所在:
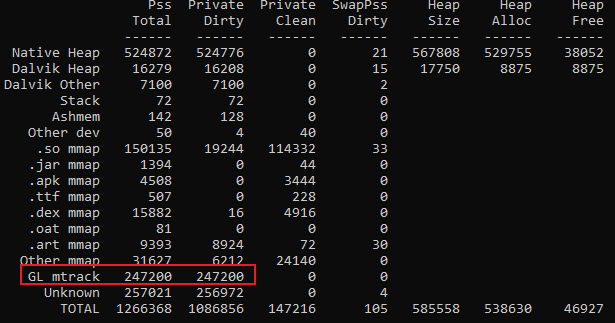
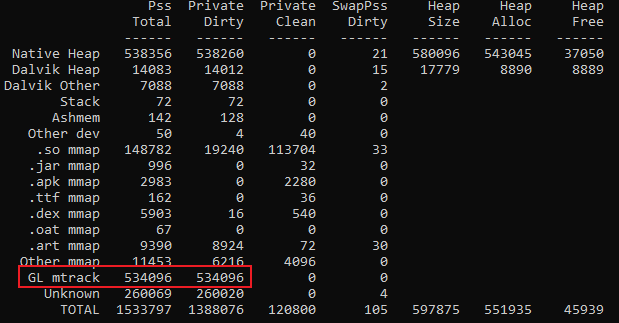
上图是奥义播放前的快照,下图是奥义播放后的快照,通过对比发现涨幅都集中在GL mtrack。
- 再结合真机在Unity Profiler上的结果,显示GfxDriver从127MB涨到0.56GB:

1.2 小结
通过以上三个工具组合,我们可以大致定位PSS的增长大头在“显存”上。但我们知道,手机上是没有独显的,SoC中GPU和CPU共用一块LPDDR物理内存,因此我在显存上加上了引号。而以上三个工具分别引出了有关“显存”的三个概念,后面我们会深入了解一下以下三个概念:
GamePerf——memGraphics
PSS——GL mtrack
Unity Profiler——GfxDriver
2. 单元测试
既然已定位到,那么接下来就可以通过单元测试来进一步定位问题所在了。在这个阶段,就要引入新的工具——System Profiler。在测试之前,先简单介绍一下这个工具。
2.1 工具选择——System Profiler
System Profiler是华为提供给开发者的一款用于Android平台应用程序的性能数据实时采样工具。通过性能数据的实时动态变化与应用的动态场景相结合做关联分析,帮助开发者快速定位应用程序的性能问题。它可以采集的数据有:
- CPU性能数据指标:CPU负载、CPU各核使用率、CPU各核频率和CPU性能计数器。
- GPU性能数据指标:GPU频率、GPU负载和GPU性能计数器。
- Memory性能数据指标:系统Memory使用情况、应用APP进程Memory使用情况和GPU Memory使用情况。
- Graphics性能数据指标:帧耗时FrameTime、实时帧率FPS、卡顿Jank和严重卡顿Big jank。
- 其他性能数据指标:设备CPU温度、GPU温度、电池温度、网络数据流量速率、Disk数据读写速率和用户自定义性能数据事件。
为什么会选用这个工具呢,主要是从以下几个方面考虑的:
- 经过以上的初步定位,内存暴涨问题跟机型无关
- 需要看到PSS的实时变化
- dumpsys meminfo无法满足实时这个需求
- Unity Profiler的数据又比较局限,无法纵观全局
- Android Profiler虽然能够看到PSS的实时变化,但跟dumpsys相比,Android Profiler没有System和Private Other项,但是多了一个Others项,需要通过一些换算才能跟dumpsys出来的PSS匹配
- 最好能够看到除了PSS之外其它的一些性能指标,方便对问题做进一步排查定位
2.2 单个特效播放测试
2.2.1 测试数据
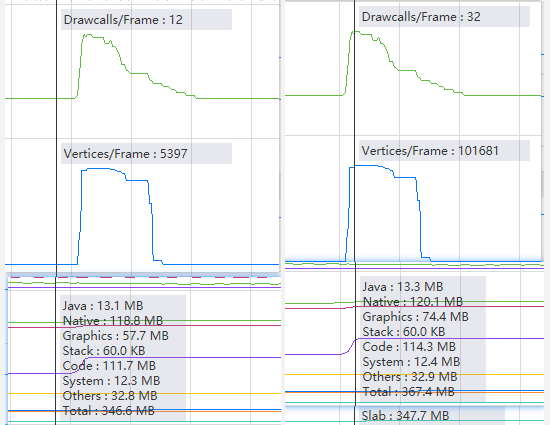
2.2.2 分析
- System Profiler中Graphics的含义跟APP Summary中的Graphics一样,播放前后的差距为16.7MB
现在只粗略算一下特效的其中一个Shader,一个顶点占用为:4*(4+3+2+4+4)= 68Byte,数量为:101681,由此算出占用大小大概为:68 * 101681 / 1024 / 1024 = 6.59MB。
struct VertexInput
{
float4 vertex : POSITION;
float3 normal : NORMAL;
float2 texcoord0 : TEXCOORD0;
float4 texcoord1 : TEXCOORD1;
float4 vertexColor : COLOR;
};
2.3 12个特效瞬间播放测试
先说明一下,经过前期的情况摸底,游戏中奥义的播放会瞬间播放12个相同特效。因此,单元测试还需要模拟测试一下游戏中的真实情况,看看瞬间播放12个相同特效的话效果如何。
2.3.1 测试数据
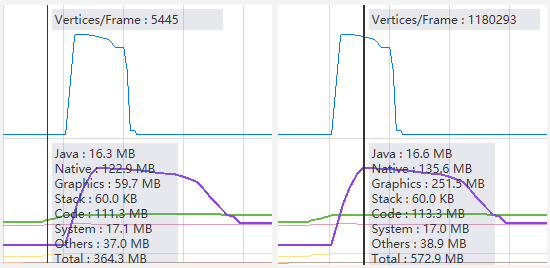
2.3.2 分析
NativeHeap相差13MB(135.6-122.9)左右,Native表示从C或C++代码分配对象的内存(因为Unity的底层是C++写的,大部分对象的创建都是在C++完成的,这部分内存就会进入Native中,而C#那边就是一个对C++引用和操作的“壳”,这部分会进入到堆内存即Mono中,而Mono内存则在Unknown中体现),主要由以下几部分组成:
- Mesh
- Font
- Fmod
- Texture(R/W)
- Material/Shader
- Animation Clip等
Graphics依然是大头所在,随着12个特效瞬间播放,Graphics从59.7MB瞬间增长到了251.5MB。再结合上图中顶点数从5445暴涨到1180293,基本可以判定,造成PSS瞬间增长200MB的原因是顶点数量的暴涨。同时推测游戏中PSS暴涨500MB也是这个逻辑:如下图所示,游戏中奥义播放后每帧顶点数峰值为212万,相比单元测试中的115万,数量正好是2倍左右,再加上游戏中小奥义播放时还有其它特效在同时播放,基本就会达到500MB左右了。
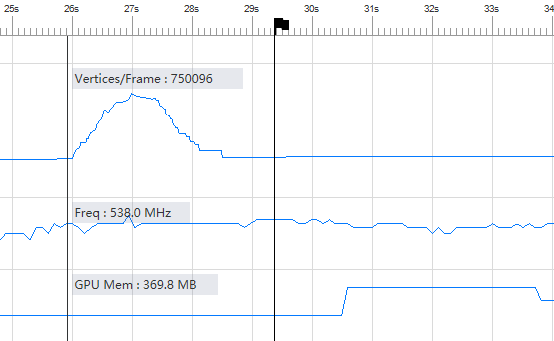

- 为什么Graphics到达峰值后会回落一部分直到维持在一个高位呢?
对于这个问题,我这边也翻阅了大量资料,尽可能地解释一下,估计还是会有不对的地方,欢迎大家来讨论!
首先明确几个概念:
- CPU的内存一般称之为主存(Main Memory),GPU自己的存储则称为Local Memory,即GPU的本地存储,有时候也称为Video Memory(即我们通常所说的显存)
- 手机SoC上GPU没有自己的物理存储设备,而是共享CPU的存储空间,即Unified Memory Architecture(一致性存储架构),通常是从CPU的存储中划分一部分出来作为该GPU的Local Memory
其次,我们要了解CPU和GPU在渲染时数据传输的工作原理:
CPU将顶点数据放入主存当中,供GPU使用。由于主存的内容对GPU来说是不可见的,所以GPU是不能直接访问这些数据的。为了让GPU访问CPU主存的内容,业界引入了一个叫GART(即Graphic Address Remapping Table)的技术。GART是一个内存地址的映射表,可以将CPU的内存地址重新映射到GPU的地址空间,这样就可以让GPU直接访问(DMA,Direct Memory Access)Host System Memory。
Pinned Memory就是CPU内存上的一块专门用于GART的存储区域。
以OpenGL为例,当CPU需要更新数据给GPU使用时,比如顶点数据的更新、纹理数据的上传等,可以通过这两个函数:glBufferData和glBufferSubData,将数据从Main Memory拷贝到Pinned Memory,一旦拷贝完成,就会发起一次异步的DMA传输,将数据传输给GPU,然后就会从函数调用返回,一旦函数返回,就可以对原来CPU主存中的数据做任何处理——修改或者删除。
所以,这里大胆猜测一下,Graphics到达峰值后迅速下降的部分应该是Main Memory。
3. 精准定位
终于来到了最后一步:查出顶点暴涨的真相。
下图是模拟同时播放12个相同特效的截帧,可以看到,光是baozha_01这么一个特效结点,它的顶点数就有120660。把该特效中的baozha_01节点用到的模型拉出来看,也就只有2011个顶点,乘上12的话也只有24132,这差的10w左右的顶点去哪了?
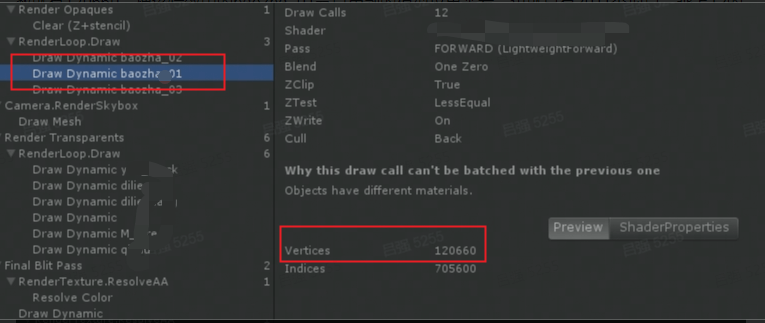

继续找原因,这次要通过RederDoc来截帧看看,这120660个顶点来自哪里。

看到这5个排列整齐的球体,瞬间明白了什么,赶紧到粒子设置的地方看一下:

改成2个试试:
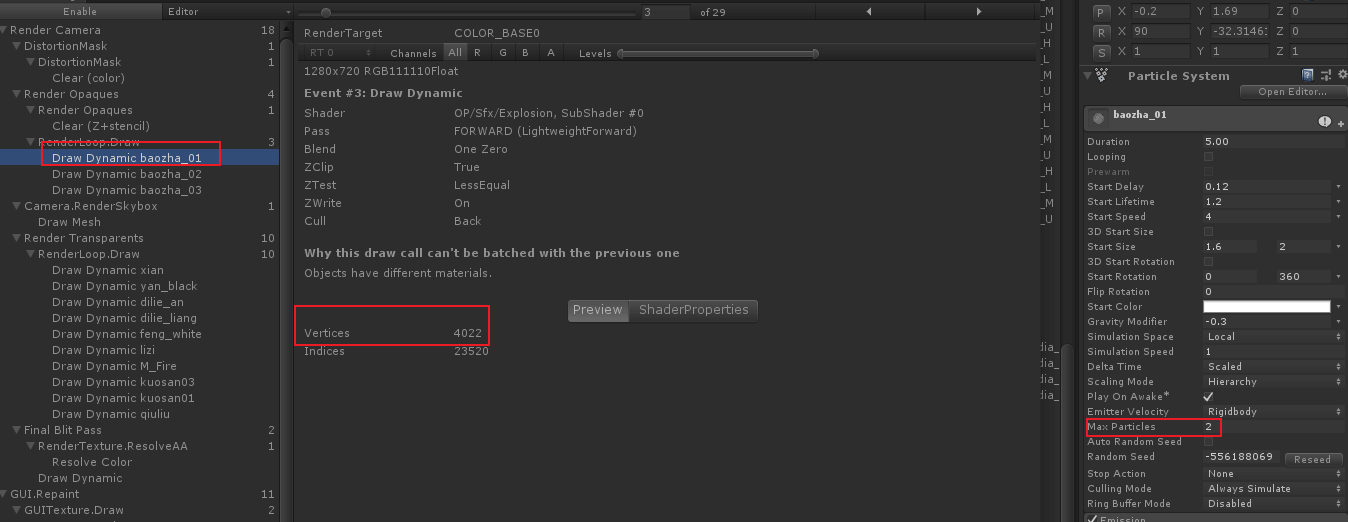
所以120660就是这么来的:120660 = 2011 x 5 x 12
至此,真相大白。
理解“显存”的三个概念
- GamePerf的memGraphics,它的官方文档上写着让我们参考Unity的文章,里面没有memGraphics的概念,都是对内存的相关说明,不过很值得一看。结合数据,这里大胆猜测memGraphics就对应着APP Summary中的Graphics:指渲染相关的所有内存之和,包括Gfx dev、EGL mtrack和GL mtrack中所有Private部分之和。
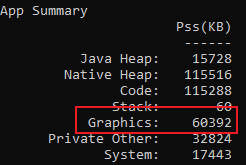
PSS的GL mtrack,其实是主要看Gfxdev和GL mtrack,这里为什么只提到GL mtrack呢?大家看上面我的PSS截图,里面确实没有Gfxdev,这是截自华为手机的,猜测是华为手机底层把Gfxdev和GL mtrack都统计成了GL mtrack了。因为如果换成高通SoC,就会出现Gfxdev。上面Unity对PSS的介绍文章中也是把Gfxdev和GL mtrack放在一起说明,这里直接翻译一下:GL和Gfx是驱动反馈的GPU内存,主要是GL纹理大小的总和、GL命令缓冲区、固定的全局驱动RAM消耗以及Shader。需要指出,这些不会出现在旧的Android版本上。注意:用户空间驱动和内核空间驱动共享同一个内存空间。在某些Android版本上,这个部分会被重复计算两次,因此Gfxdev要比实际上使用的数值更大。
Unity的GfxDriver其实统计的就是Textures和Buffer(Vertex Buffer以及Index Buffer)的内存,Unity源码是通过REGISTER_EXTERNAL_GFX_ALLOCATION_REF这个宏进行统计的,手头有源码的小伙伴可以去看一下 。但是,Unity官方文档上对GfxDriver的解释是:“The estimated amount of memory the driver uses on Textures, render targets, Shaders, and Mesh data”。对于多出的Render Targets,笔者这边表示存疑,后面需要验证一下。
总结
最后,简单总结一下“方法论”!
所谓大道至简,先初步定位缩小问题范围,其次单元测试分析问题所在,最后精准定位找到问题原因。我认为每个阶段中最重要的就是选择趁手的工具。
- 初步定位——GamePerf(UWA、PerfDog、UPR都可以)、Dumpsys Meminfo、Unity Profiler
- 单元测试——System Profiler
- 精准定位——Renderdoc
参考
[1] https://learn.unity.com/tutorial/memory-management-in-unity#5c7f8528edbc2a002053b59d
[2] https://developer.nvidia.com/vulkan-memory-management
[3] https://developer.huawei.com/consumer/cn/doc/development/Tools-Guides/overview-0000001050741459
[4] https://www.cnblogs.com/hellobb/p/11023873.html
[5] https://blog.csdn.net/msf568834002/article/details/78881341
[6] Unity游戏内存分布概览
这是侑虎科技第1217篇文章,感谢作者吕强供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者在UWA学堂发布的《五天实现PBR保姆级教程》课程,旨在对PBR(Physically Based Rendering,基于物理的渲染)技术进行深入浅出地讲解与实现。
再次感谢吕强的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)