
Live2D 性能优化
- 作者:admin
- /
- 时间:2019年12月17日
- /
- 浏览:8135 次
- /
- 分类:厚积薄发
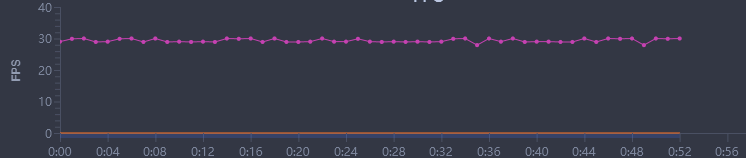
随着Live2D在项目研发中被广泛使用,其性能优化的需求已经不容忽视。笔者通过模型资源、Mesh、RenderTexture、Material和CPU耗时这5个方面来阐述优化的过程,并且最终实现了低端机上6个模型30帧的效果,值得大家参考。
优化结果
测试机型:低端机——红米4X
测试样例:同样的6个模型(游戏中同屏最多6个模型)
版本:3.2.05

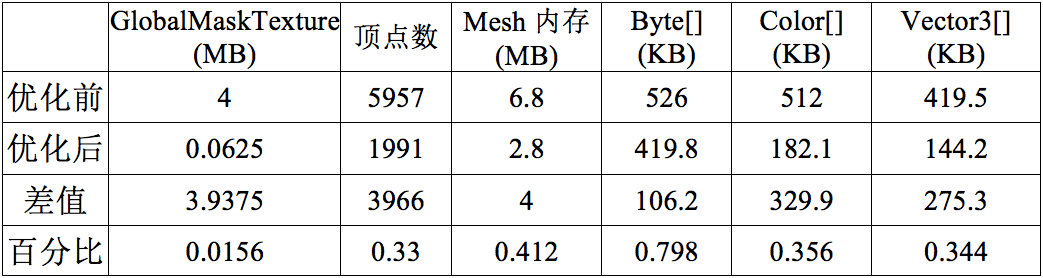
CPU优化主要在CubismModel.Update、CubismModel.OnRenderObject;
内存优化主要在Texture2D、Mesh、RenderTexture、Material以及Mono内存分配。
接下来介绍从模型资源、Mesh、RenderTexture、Material和CPU耗时5个方面来优化性能。
1、模型资源
项目前期没有制定Live2D美术规范,美术导出文件的时候,直接使用自动布局顶点的方式,而Live2D自动生成Mesh的时候对于每个部件的内外边界各生成一份顶点,发现如下问题:
1、模型Mesh数量太多
2、模型的总顶点数达到6K左右
后续跟美术沟通之后,对Live2D模型(后续的模型都指Live2D模型)的导出规定如下:
1、手动布局顶点
2、ArtMesh数量控制在100以内(之前的模型由于改动的工作量太大,暂时不做修改)
3、模型顶点数控制在2k面以内(游戏最多有6个模型)
4、Edit Texture Altas中贴图大小1024*1024,自动布局且Margin为5px
5、为了避免多贴图导致DrawCall升高,一个模型只使用一张贴图
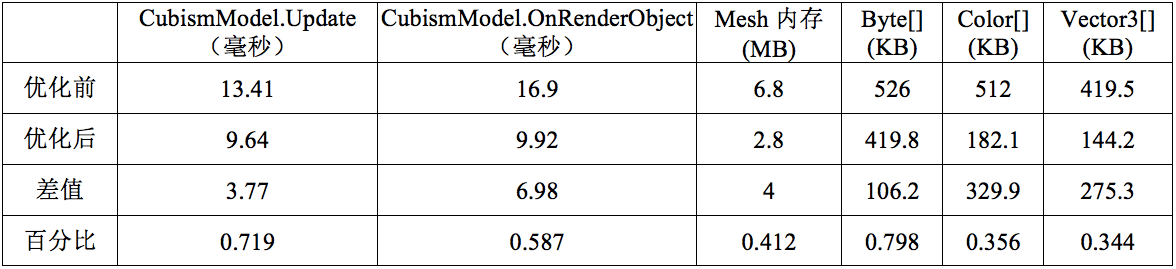
2小时后,通过Live2D Cubism Editor->File->Model Statistics查看优化结果如下:


性能数据测试结果如下:
2、Mesh
测试发现游戏一个模型的Mesh数量在80-200之间,同屏最多有6个模型,通过UWA GOT测试发现Mesh峰值达到107MB(27380个),Material数量达到10.2MB(14968个),其中Unlit(Instance)数量14563个明显异常。
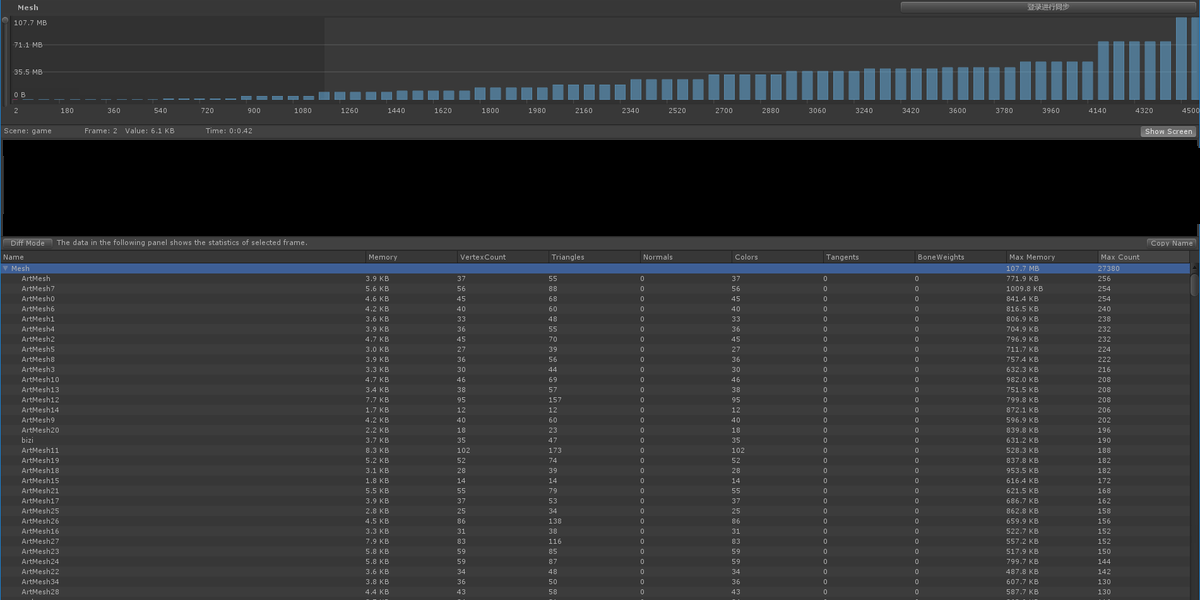
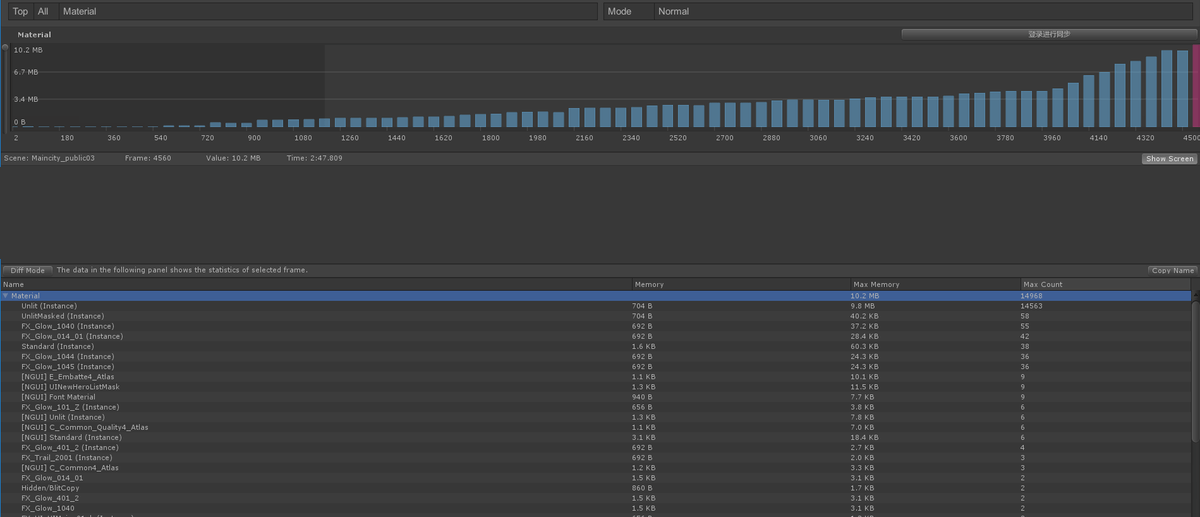
研究CubismRenderer.cs发现如下问题:
1、运行时创建了两份Mesh内存
2、Mesh资源未销毁,导致内存泄漏
3、顶点色每帧都会重新赋值
针对问题1,经测试发现,改成一份Mesh并没有明显的CPU变化,Mesh内存减少一半,由于每一帧都有顶点变化,_meshFilter.mesh = FrontMesh每帧700次的CPU消耗也可以省去。
针对问题2,可以在OnDestroy中调用Destroy接口销毁Mesh。
针对问题3,使用标记控制是否更新顶点色,减少顶点色赋值的0.5ms左右CPU消耗。
另外值得一提的是,Mesh中使用了顶点色处理透明和颜色变化,但是同一个Mesh的顶点色全部相同,可以想到在Shader中控制颜色,实际上为了动态合批不得不使用顶点色,合批之后控制在10个DrawCall左右,不合批每个模型DrawCall数量达到上百个。
3、RenderTexture
CubismMaskTexture.cs中创建的RenderTexture大小默认为1024*1024,项目中遮罩效果大部分使用在眼睛,在实际测试之后有如下优化:
1、将GlobalMaskTexture.asset的Size改成128,实际数值可以根据项目需要修改。
2、CubismMaskTexture.cs中RemoveSource函数加上如下检查,在没有遮罩模型的时候可以释放RenderTexture。
if(Sources.Count == 0)
{
if(_renderTexture != null)
{
RenderTexture.ReleaseTemporary(_renderTexture);
_renderTexture = null;
}
}
3、CubismMaskTexture.cs中OnDisable()和RefreshRenderTexture()函数中同样添加释放RT的接口。
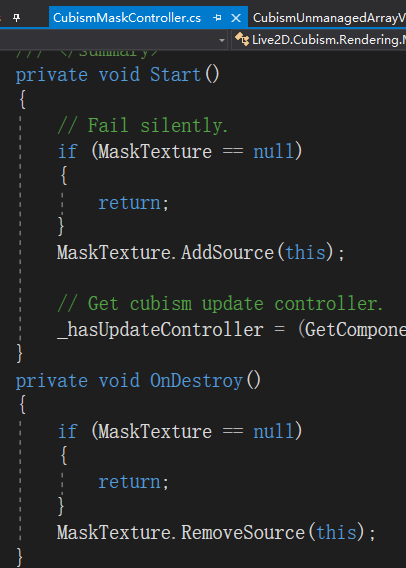
4、CubismMaskController.cs做如下修改,避免RenderTexture无法释放,同时避免切换模型且未销毁时CubismMaskCommandBuffer.Lateupdate持续CPU消耗。

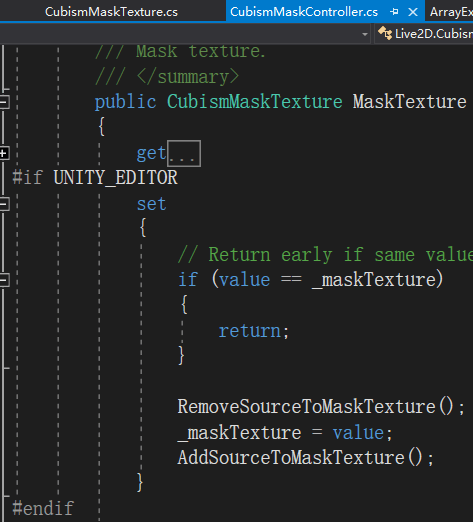
修改后:

4、Material
通过UWA GOT测试发现材质数量也达到1w多个,研究发现材质有明显的泄漏问题,解决方案如下:
1、CubismRenderer.cs中Material属性
public Material Material
{
get
{
return MeshRenderer.material;
}
set
{
MeshRenderer.material = value;
}
}
修改成:
public Material Material
{
get
{
return MeshRenderer.sharedMaterial;
}
set
{
MeshRenderer.sharedMaterial = value;
}
}
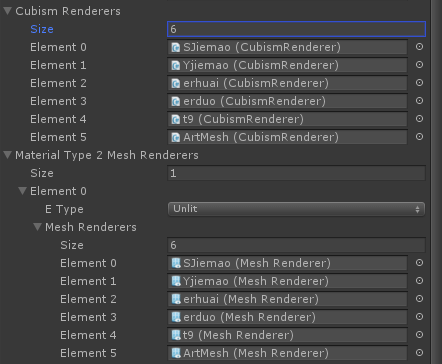
2、模型导入引擎后,将相同材质的MeshRender缓存,在运行时的Start函数中实例化材质,对所有同材质的MeshRender赋值同一个实例,离线实例化的问题时可能出现两个以上相同的模型共享材质。
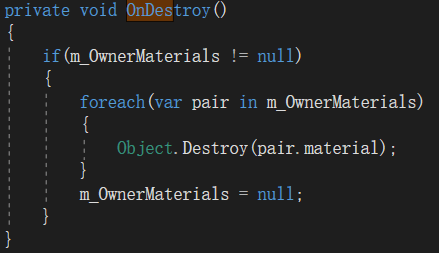
3、模型销毁的时候同时将实例化的材质销毁。
5、CPU耗时
通过UnityProfiler发现CPU消耗主要在:
1、CubismModel.OnRenderObject[9.92ms]
一部分时间消耗在CubismCoreDll.UpdateModel(Ptr)调用,该接口为Live2D底层封装暂时无法修改,只能通过减少Mesh数量减少CPU时间。
另一部分消耗DynamicDrawableData.ReadFrom(UnmanagedModel),通过分析代码发现这里只是复制数据到DynamicDrawableData,则可以省去该CPU消耗. 同时在使用DynamicDrawableData的逻辑中用UnmanagedModel替代。
2、CubismModel.Update[9.64ms]
这个接口最终调用到CubismRenderController.cs文件的OnDynamicDrawableData接口,其逻辑主要是同步底层数据变化同时更新Mesh信息,优化思路如下:
一方面更新是否可见,渲染顺序,透明度,顶点位置信息. 其中从C++底层获取数据的时候每一次都会进行范围合法性检查,此处可以在循环外对数组进行统一检查,有部分Mesh不可见,可以在Mesh不可见的时候避免更新。
具体逻辑如下:
///CubismUnmanagedArrayView.cs
public unsafe T this[int index]
{
get
{
return Address[index];
}
}
///CubismRenderController.cs
private void OnDynamicDrawableData(CubismModel sender, CubismUnmanagedModel unmanagedModel)
{
var dataDrawables = unmanagedModel.Drawables;
var iLen = dataDrawables.Count;
var flags = dataDrawables.DynamicFlags;
var opacities = dataDrawables.Opacities;
var renderOrders = dataDrawables.RenderOrders;
var vertexPositions = dataDrawables.VertexPositions;
if(!flags.IsValid)
{
throw new InvalidOperationException("flags Array is empty, or not valid.");
}
if (!opacities.IsValid)
{
throw new InvalidOperationException("opacities Array is empty, or not valid.");
}
if (!renderOrders.IsValid)
{
throw new InvalidOperationException("renderOrders Array is empty, or not valid.");
}
if (flags.Length < iLen)
{
throw new InvalidOperationException(string.Format("flags Array Length[{0}] < iLen[{1}]", flags.Length, iLen));
}
if (opacities.Length < iLen)
{
throw new InvalidOperationException(string.Format("opacities Array Length[{0}] < iLen[{1}]", opacities.Length, iLen));
}
if (renderOrders.Length < iLen)
{
throw new InvalidOperationException(string.Format("renderOrders Array Length[{0}] < iLen[{1}]", renderOrders.Length, iLen));
}
// Get drawables.
var renderers = Renderers;
// Handle render data changes.
for (var i = 0; i < iLen; ++i)
{
var curRenderer = renderers[i];
var curFlags = flags[i];
// Skip completely non-dirty data.
if (curFlags.HasAnyFlag())
{
// Update visibility.
if (curFlags.HasVisibilityDidChangeFlag())
{
curRenderer.OnDrawableVisiblityDidChange(curFlags.HasIsVisibleFlag());
}
// Update render order.
if (curFlags.HasRenderOrderDidChangeFlag())
{
curRenderer.OnDrawableRenderOrderDidChange(renderOrders[i]);
}
// Update opacity.
if (curFlags.HasOpacityDidChangeFlag())
{
curRenderer.OnDrawableOpacityDidChange(opacities[i]);
}
// Update vertex positions.
if (curFlags.HasVertexPositionsDidChangeFlag())
{
curRenderer.OnDrawableVertexPositionsDidChange(vertexPositions[i]);
}
}
if (curRenderer.UpdateVisibility())
{
curRenderer.UpdateRenderOrder();
curRenderer.UpdateVertexColors();
curRenderer.UpdateVertexPositions();
}
}
// Pass draw order changes to handler (if available).
var drawOrderHandler = DrawOrderHandlerInterface;
if (drawOrderHandler != null)
{
var senderDrawables = sender.Drawables;
var drawOrders = dataDrawables.DrawOrders;
for (var i = 0; i < iLen; ++i)
{
var curData = flags[i];
if (curData.HasDrawOrderDidChangeFlag())
{
drawOrderHandler.OnDrawOrderDidChange(this, senderDrawables[i], drawOrders[i]);
}
}
}
dataDrawables.ResetDynamicFlags();
}
///CubismRenderer.cs
internal unsafe void OnDrawableVertexPositionsDidChange(Core.Unmanaged.CubismUnmanagedFloatArrayView newVertexPositions)
{
if (!newVertexPositions.IsValid)
{
throw new InvalidOperationException("srcVertexPositions Array is empty, or not valid.");
}
// Copy vertex positions.
var iLen = newVertexPositions.Length >> 1;
if (newVertexPositions.Length < iLen)
{
throw new InvalidOperationException(string.Format("newVertexPositions Array Length[{0}] < iLen[{1}]", newVertexPositions.Length, iLen));
}
if (VertexPositions.Length != iLen)
{
Debug.LogErrorFormat("TranslateVertexPositions dont same length iLen={0}|dstMesh.vertexCount={1}"
, iLen, VertexPositions.Length);
}
// Copy vertex positions.
fixed (Vector3* pDstVertexPositions = VertexPositions)
{
for (var v = 0; v < iLen; ++v)
{
var pDst = (pDstVertexPositions + v);
var offset = v << 1;
pDst->x = newVertexPositions[offset];
pDst->y = newVertexPositions[offset | 1];
}
}
// Set swap flag.
SetNewVertexPositions();
}
另一方面同步Mesh的信息,源代码使用了双缓冲Mesh优化性能,由于每一帧都有顶点变化,则每帧调用700次左右的Meshes[BackMesh].colors = VertexColors和MeshFilter.mesh = mesh占用大约一半的时间,这里我改成一份Mesh并没有发现明显的CPU变化,Mesh内存减少一半,同时MeshFilter.mesh = mesh的CPU消耗也可以省去。
总结
在低端机红米4X上:
CPU主要耗时优化到45%(30.2ms->13.5ms)
内存优化到32%(13.6MB->4.3MB)
内存和材质泄漏已解决,同时Mesh内存大量减少。
到此Live2D的优化告一段落,在低端机上6个模型已经可以达到30帧。
封面图来源于网络
https://www.live2d.com/zh-CHS/about/
这是侑虎科技第659篇文章,感谢作者晨星供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!



