
浅谈Virtual Texture
- 作者:admin
- /
- 时间:2020年05月27日
- /
- 浏览:11132 次
- /
- 分类:厚积薄发
一、摘要
随着更多开放大世界的游戏的流行,游戏引擎就会需要使用到更多的资源,这无论是对带宽还是存储都是一个挑战。当然,这个问题需要很多的解决方案共同完成,本文介绍其中一个解决方案:Virtual Texture,用来解决巨量Texture的加载问题。
二、总览
Virtual Texture是由id Software提出,用来解决Texture加载问题的一套解决方案,不仅解决了带宽和内存问题,还带来了其它的好处。随后,在这个方案的基础上,行业又相继提出了如:Procedural Virtual Texture、Adaptive Procedural Virtual Texture、Hardware Virtual Texture等解决方案。本文会从id Software的方案出发,逐步介绍到最新的基于新一代图形API的硬件Virtual Texture。
1. 在Virtual Texture之前
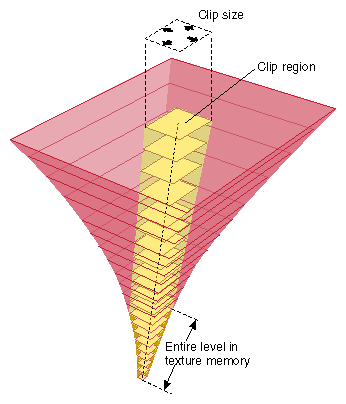
其实在Virtual Texture之前,已经出现过一些解决方案,这些方案中的思想直接促成了Virtual Texture的诞生。由于Mesh的LOD,产生了一种将Texture bake到不同LOD的解决方案,与之相类似的,在运行时动态决定要加载的Texture,给不同的LOD Mesh。一个名为Jonathan Blow的程序员在2000年提出了基于后者的方案,1998年Tanner发表了一篇论文:《The Clipmap: A Virtual Mipmap》,这篇论文中提到的Clipmap的技术本来用于地图渲染,后被id Software应用到游戏中,提出了一个叫做MegaTexture的技术。
Clipmap的基本思想是:设置一个Mipmap大小的上限,超过这个上限的Mipmap会被clip掉,也就是不会加载到内存中。
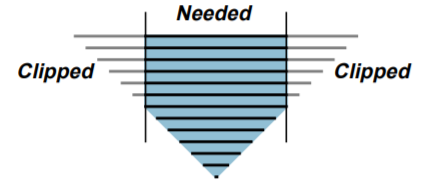
当我们的视野发生变化时,我们需要修改被clip的区域,让视野内Mipmap的部分加载:
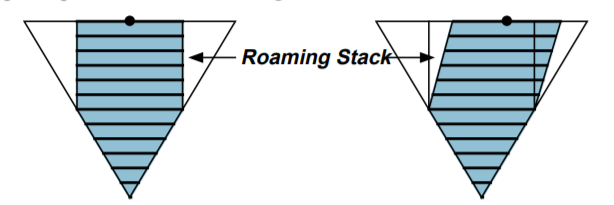
这项技术被用在了Doom3的开发上,而这项技术背后的推动者是John Carmack。
2. Software Virtual Texture
在MegaTexture的基础上,id Software进一步提出了Virtual Texture的概念,这个概念取自于Virtual Memory。与虚拟内存类似的是,一个很大的Texture将不会全部加载到内存中,而是根据实际需求将需要的部分加载;与虚拟内存不同的是,它不会阻塞执行,可以使用更高的Mipmap来暂时显示,它对基于block的压缩贴图有很好的支持。
基本思路是:将纹理的Mipmap chain分割为相同大小的Tile或Page,这里的纹理是虚纹理,然后通过某种映射,映射到一张内存中存在的纹理,这里的纹理是物理纹理,在游戏视野发生变化的时候,一部分物理纹理会被替换出去,一部分物理纹理会被加载。
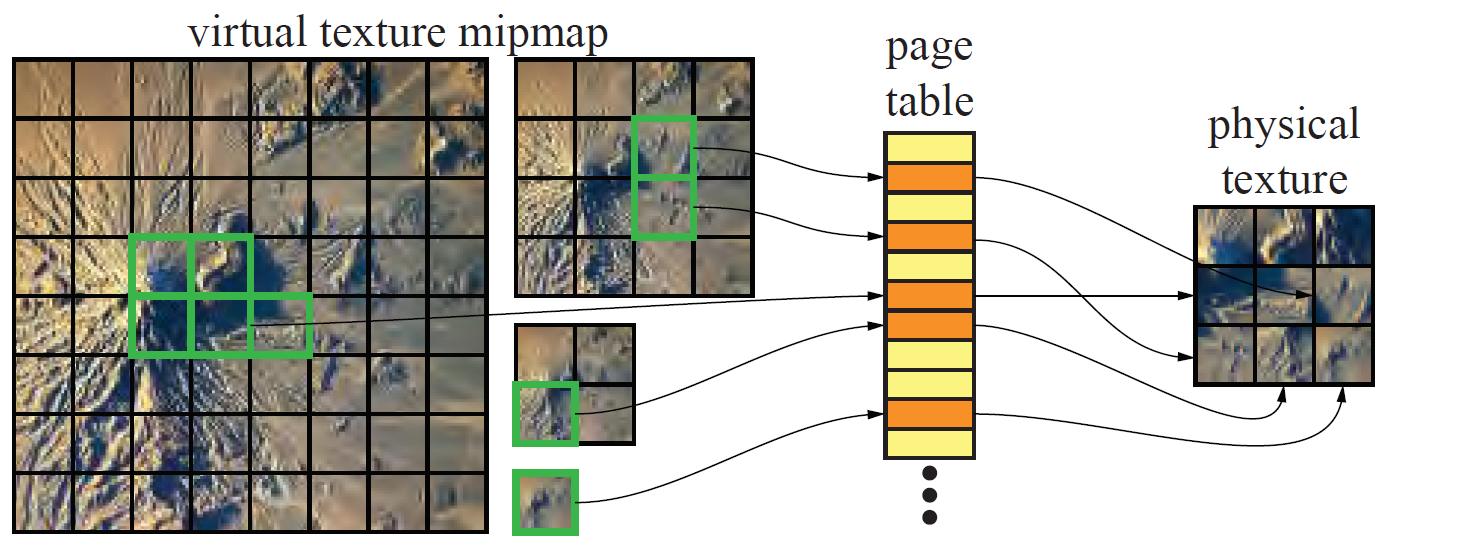
这样的机制不仅仅减少了带宽消耗和内存(显存)消耗,也带来了其它好处。比如有利于合批,而不用因为使用不同的Texture而打断合批,这样可以根据需求来组织几何使得更利于Culling。当然合批的好处是states change变少,LightMap也可以预计算到一张大的Virtual Texture上用来合批。
2.1 地址映射
地址映射在Virtual Texture中是一个很重要的环节,但是如何将一个Virtual Texture的Texel映射到Physical Texture的Texel上,需要适配到高分辨率的Page没有加载的情况,并得到已经加载的对应低分辨率的Page地址。
2.1.1 四叉树映射
使用四叉树主要是为了和Mipmap对应,也就是每个低MIP的Map会对应有四个高MIP的Map,四叉树中只存储加载的Mipmap信息。这里的对应关系就是每个加载的Virtual Texture的Page对应一个四叉树的节点,具体的计算如下:
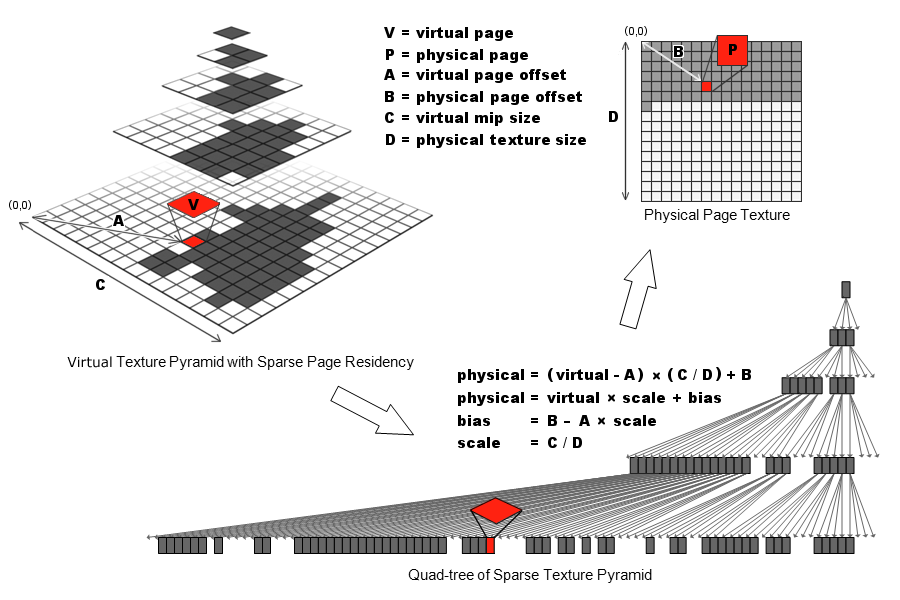
这里存在每个四叉树的节点中的内容就是bias和scale,这样就可以将虚拟纹理的地址转换成物理纹理的地址。如果没有找到,也可以用父节点的地址来得到低分辨率。但是这里要找到对应的节点需要搜索这个四叉树,搜索的速度取决于树的高度,也就是Mipmap的层级,在差的低MIP的地址上效率会比较低。
2.1.2 单像素对应虚纹理的一个Page的映射
为了减少索引,首先容易想到的就是,为每个虚纹理的Page都存储一份信息,这样就能直接转换了。这个方案就是创建一个带Mipmap的Texture,一个Texel对应虚纹理的一个Page,Texel的内容就是四叉树映射里面的bias和scale。
假如对应的MIP没有加载,存储的就是高MIP的转换信息,这样显然就提高了地址转换的效率。但是这会带来内存增加,因为我们需要每个虚纹理的Page都对应一个Texel。其中bias和scale都是二维的向量,即使设计虚纹理和物理纹理的比例一致,我们也需要至少scale、SBias、TBias三个量,而且这三个量的精度要求很高,至少需要16bit的浮点数精度。如果要达到这样的精度就需要F32*4的纹理格式,那么必然会产生一个巨大的映射纹理,因此需要减小映射纹理的大小。
2.1.3 双纹理映射
这个方案仍然有一个对应每个虚纹理Page的Texture,但是不同的是,纹理的内容存储的是物理纹理Page的坐标,用这个坐标再去索引另外一张Texture。另外一张贴图的内容才是bias和scale,但不是每个虚拟纹理,而是每个物理纹理Page一个Texel。下图是虚拟纹理对应的Texture:
这样就减少了映射纹理的大小,但是同时多了一次纹理查询。
2.1.4 Page和MIP level映射
总结上面两个基于映射纹理的方案,要么是纹理需要很大的存储,要么是需要多次查询。如果从映射纹理比较大的角度考虑优化,可以考虑适当减少每个像素的大小,这个方案就是从这个角度出发的。在这个方案中,仍然是每个虚拟纹理的Page对应一个texel,但是存储的内容是物理纹理Page的Offset和虚拟纹理所在的MIP level。
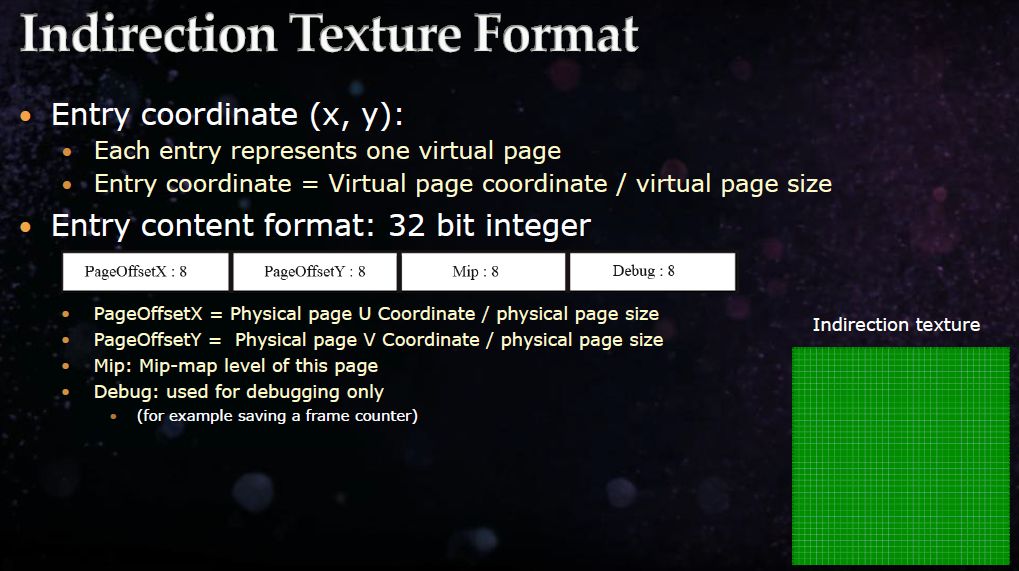
这样存储的好处就是,Page Offset对精度的要求没有那么大,用32bit的Texture即可。当然也可以压缩到更小格式的纹理中,如RGB565。这种方案的使用最广泛,基本各家引擎的实现都使用了这种方案。
2.1.5 HashTable映射
这是最直接的方法,好处是节省内存,查询速度快,但是当遇到没有加载的virtual Page的时候,需要多次查询。这个和四叉树还有一个问题,即如何设计一个GPU友好的数据结构。
2.2 Texture Filtering
由于虚拟纹理并没有完整加载,所以各种采样过滤在Page的边界会有问题,我们需要自己设计解决这些问题的方法,适当的使用软实现的采样。
2.2.1 Bi-linear Filtering
这个解决方案比较简单,就是给Physical Page加上一个像素的border。
2.2.2 Anisotropic Filtering
Anisotropic Filtering可能需要更多的相邻像素,假如我们需要支持8倍的Anisotropic Filtering,那我们需要采样步长为4的相邻像素,也就是我们的border要增加到4个像素。增加4个像素的border会增加Physical Texture的大小,但是带来了一个好处,就是适配了block compression。
具体实现可以分为软实现和硬实现,硬实现放到下文的Tri-linear说,这里说软实现。软实现其实就是在Shader中实现Anisotropic Filtering的算法,在决定采样的MIP level的时候,需要把虚纹理相对于物理纹理的比例考虑进去,剩下的就是正常的Anisotropic Filtering。

2.2.3 Tri-linear Filtering
Tri-linear Filtering的实现方案可以分为两种:一种是软实现,一种是硬实现。
所谓的软实现与Anisotropic Filtering一样,在Shader中实现Tri-linear Filtering。也就是说,需要在Shader中计算MIP level,然后进行两次地址的转换,采样两个物理纹理的Page后进行插值。
硬实现的方法是直接给物理纹理生成一个一层的Mipmap,然后利用硬件去直接采样。同样的,对于Anisotropic Filtering,也打开Anisotropic Filtering直接进行采样。这样的好处当然是由于硬件的加速,采样的效率会提升,但是这样同时会导致增加25%的纹理大小,而且由于Mipmap的边界会变成两个像素,对于block compression和超过4倍的Anisotropic Filtering来说,在遇到Page的边界时都会出现问题。
2.3 Feedback Rendering
在Virtual Texture中一个很重要的事情是要有一个可以决定加载哪些Page的策略,这个策略要有一个Feedback Rendering的过程。这个可以设计为一个单独的pass,或者在渲染Pre-Z Buffer,GBuffer的时候同时渲染。渲染生成的这张Texture里面存的就是虚纹理的Page坐标,MIP level和可能的虚纹理ID(用来应对多虚纹理的情况)。

可以看到上图,由于Page的变化在屏幕空间是比较低的,所以Feedback的RenderTexture不需要全分辨率,低分辨率渲染就可以。对于半透明物体或者Alpha Test的物体,在Feedback Rendering的过程中只能当作是不透明物体来渲染,那样就会在屏幕像素上随机产生当前像素的可能结果。
与之类似的,如果一个屏幕像素用到了两个Page,也会是随机出现一种在最后的结果RenderTexture上。这样虽然可以让所有需要的Page都加载,但是可能会遇到另外一个问题,即可能会发生这一帧加载的Page,下一帧的时候被卸载掉,然后再下一帧又要加载,这样会导致物理纹理一直在置换,即便屏幕像素并未改变,物理纹理的Page也无法稳定下来。
为了解决这个问题,需要设计一个调色板,对于半透明物体,间隔出现全透明或者不透明;对于多Page的情况,则需要设计为间隔出现不同Page的结果,这样就能同时加载所有Page,并且保持稳定。但是,如果出现了多层半透明物体的叠加或者多个Page的情况,如何设计一个合理的调色板就变成了一个问题。这里可以考虑为每个像素匹配一个linked list,但需要额外的硬件支持:structured append and consume buffers。
接着就是对这个Feedback的结果进行分析,分析需要将Feedback的结果读回CPU,这里可以使用Compute Shader解析这个结果,然后输出到一个更简单的buffer上去:
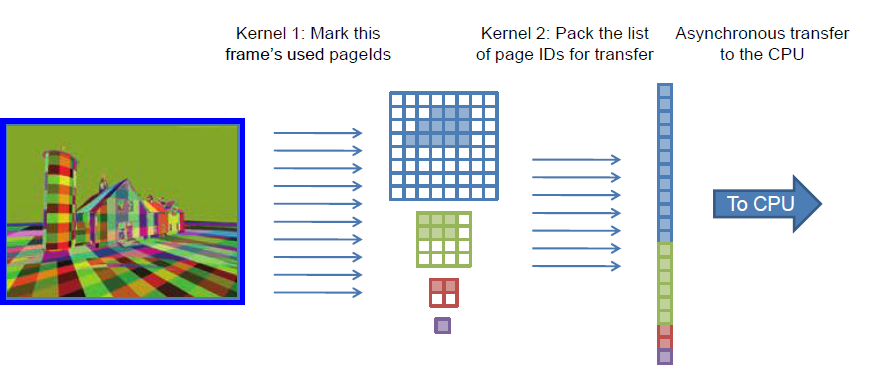
这样可以使回读操作更快,处理Page更新也能更快。对于如何更新Page,也需要策略,我们需要尽量不阻塞执行,异步地加载Page,但是对于完全不存在任何一个MIP的Page,我们还是需要同步加载防止显示出错。在异步的过程中,我们要对需要加载Page设置优先级,比如需要加载的MIP level和已经存在的MIP level相差越大的优先级越高,被越多像素要求加载的Page的优先级越高,这里需要设计一个完整的加载策略。
2.4 Texture Poping
由于Page是异步加载的,所以会有延时,当加载的MIP比当前显示的相差很远时,我们渲染会使用新加载的更清晰的MIP,这样我们会看到非常明显的跳变。假如我们用了软实现的Tri-linear Filtering,那么当加载的MIP level跟当前显示的MIP level相差很大的时候,需要做一个delay,等待中间的MIP Page的加载,然后再去更新。对于没有Tri-linear Filtering的实现,就得逐渐更新Page,使得过度平滑。一个可能的方法是,Upsample低分辨率的MIP,直到高分辨率的MIP加载。但是,因为采样的位置其实发生了突变,仍然会出现跳变。
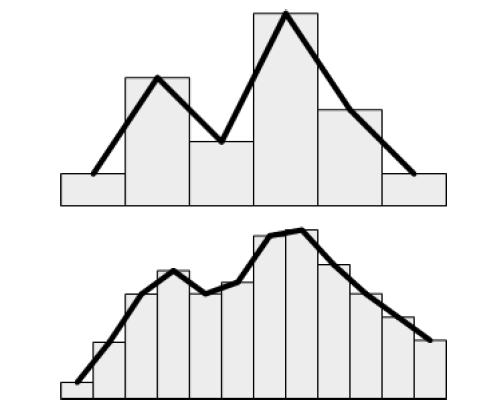
上图可以看到,当分辨率增加2倍之后,结果会发生很大的不同。解决的方案是,先把Upsample的低分辨率Page加载到一个物理纹理的Page,当高分辨率的Page加载好了,插值过度物理纹理的Page,这样采样的位置没有发生改变,只是每个像素的颜色在渐变,就不会有跳变出现了。
2.5 存储和流式加载
这一部分本文会说的比较少,因为这一部分内容甚至比Virtual Texture本身还要繁杂,所以只提一些Virtual Texture比较特殊的部分。
2.5.1 存储和压缩
对于存储和压缩,在光盘或者磁盘上存储的,需要选择一个适合的JPEG等的压缩方式。重点是当加载到内存之后,提交给GPU,根据之前的内容,需要用一个block compression来适配各种Filtering,也可以使用不同颜色空间来进行进一步压缩。
2.5.2 离线烘焙Feedback Data
就如同可见性烘培一样,对于Feedback Data是可以离线烘培的,《Titanfall 2》中实现了这个方案。
2.6 Pipeline
总结一下Software Virtual Texture的流程:
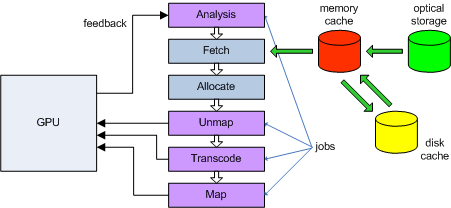
首先执行一个Feedback Rendering,或者从烘培好的Feedback Data中取出当前数据,然后分析需要加载的Page,尝试从内存中找到这个Page,如果没有,就从磁盘或者光盘中加载。然后申请一个新的物理纹理Page,在使用这个纹理之前,假如是之前用过的Page,我们需要先与GPU解绑。确定完之后,把这个Texture转换成一个GPU能用的压缩的Texture内容,并将这块Texture与GPU绑定。其中分析Feedback、Unmap、Transcode、Map过程是可以异步发生的,也就是需要一个Job System去驱动,他们的关系是生产者与消费者的关系。
在Software Virtual Texture中提到的一些内容,在其它的实现中也是需要的,比如Feedback Rendering在Hardware Virtual Texture中需要使用,地址影射在Hardware Virtual Texture和Procedural Virtual Texture中都要用到,接下来描述方案的时候,我就不一一再去说,只提一下他们的方案名字。
3. Hardware Virtual Texture
Software Virtual Texture的提出,对整个行业产生了重要的影响。但是由于需要适配各家显卡和图形接口,id Software的工程师们在戴着脚镣跳舞。由于显卡的虚拟内存是早就存在的东西,这里更多的工作是需要各家图形API去完成。这里不会探究API厂商是如何使用GPU的虚拟内存实现的,而只讨论如何使用和使用它所带来的好处。
3.1 地址映射
虚拟内存系统为我们做的就是,虚拟到物理的地址映射,从物理内存中读取我们想要的Texel信息。假如Page不在内存中,返回一个错误告诉我们。这里需要注意的是,GPU的虚拟内存的大小固定是64KB,也就是说每个Page存储的像素的个数与定义的像素格式大小有关。

工作过程跟Software差不多,仍然需要Feedback Rendering,分析Feedback数据,不同的是如何更新和采样的过程。
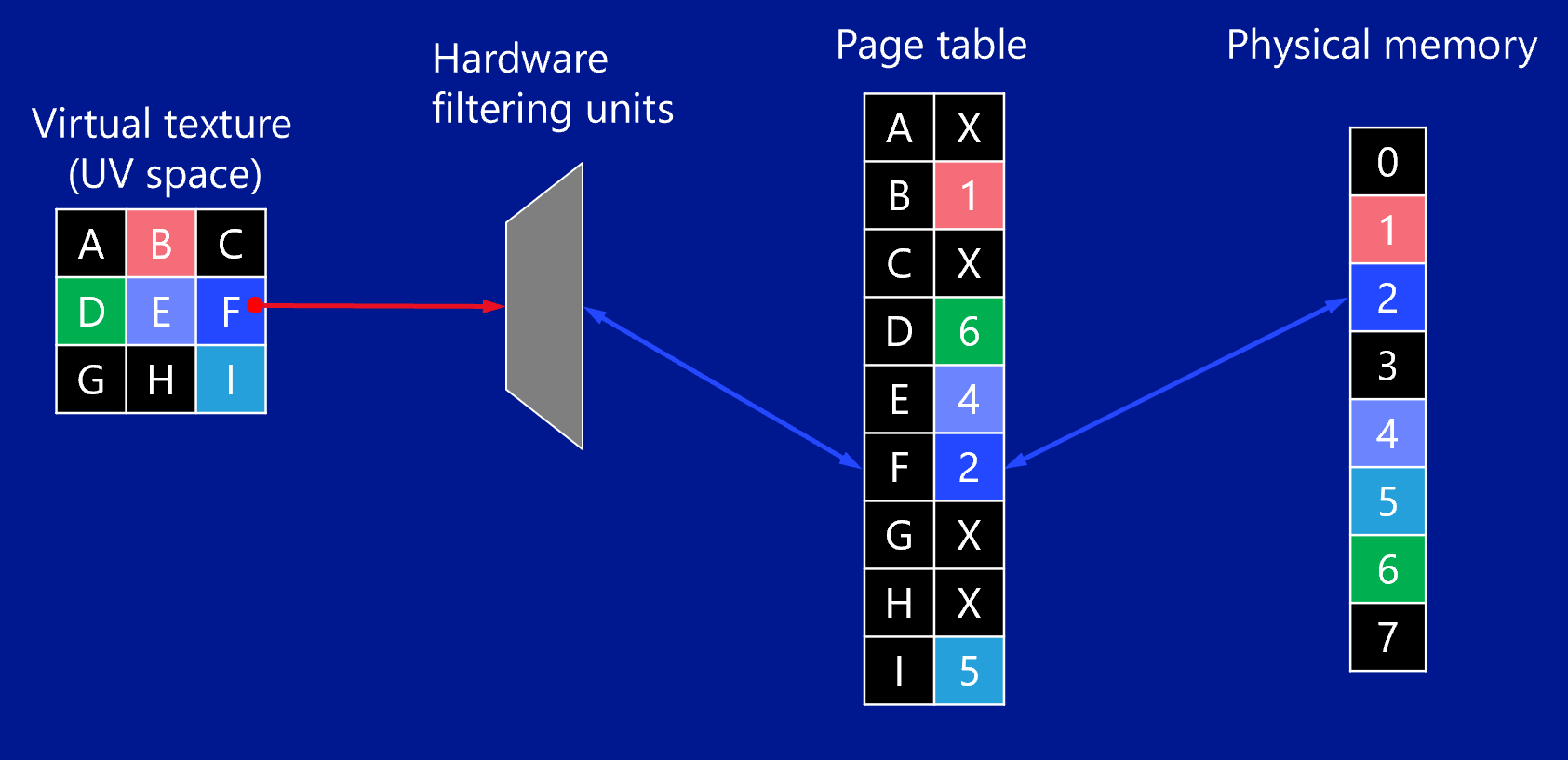
首先需要在内存中创建一个Page pool,这是用来存放从磁盘中加载的纹理内存,可以理解为物理纹理。然后,我们再创建一个特殊格式的Texture,代表那张Virtual Texture,这个时候,图形API会帮我们创建一个Page table用于映射。在更新的过程中,我们需要首先更新映射关系,也就是Page pool和Page table的关系,然后再将加载的Page pool中的内容更新到Virtual Texture中。
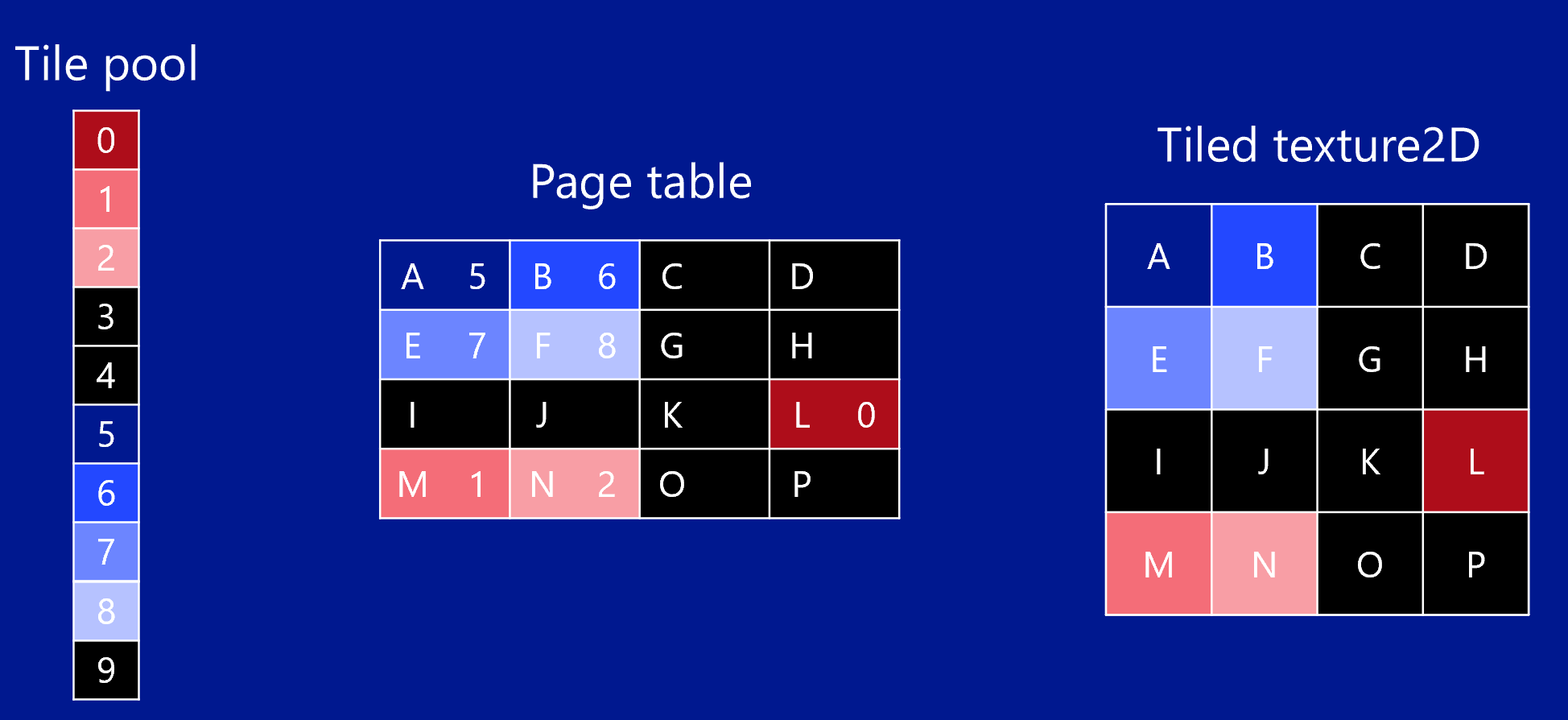
中间的Page table是与Virtual Texture Page一一对应的,对于维护这样一个Page table要比Software简单很多。当使用这样的Texture的时候,我们跟使用普通Texture一样就可以了,所有的采样、内存的映射都是图形API在底层为我们实现,这大大降低了代码复杂度,我们唯一需要处理的就是出现采样错误的情况。
3.2 Hardware Virtual Texture益处
Hardware Virtual Texture对比Software有很多优势,上面已经提到过,可以当一个普通Texture来采样,而且支持所有硬件的采样包括Bi-linear、Tri-linear、Anisotropic filtering。不需要为物理Page增加border,不需要为映射地址创建另外的Texture,减少了内存的占用。地址的映射不需要再多余的采样其它的Texture,完全是硬件驱动,所以效率会更高。
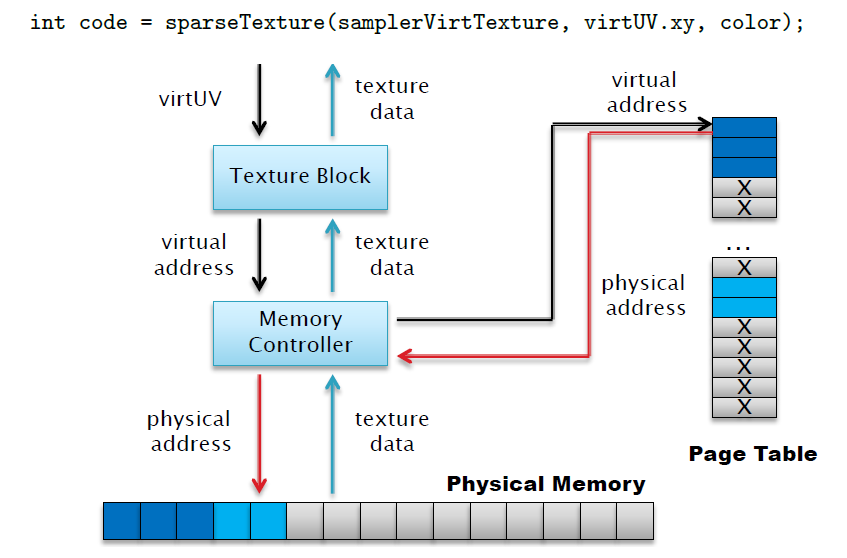
当然,这一切都是需要各家图形API的支持,只有一些比较新的API版本才能支持,DirectX叫Tiled Resource,Vulkan叫Sparse Partially-Resident Images,OpenGL叫ARB_sparse_texture,Metal叫Sparse Texture,为每个API做适配也是一个成本。
4. Procedural Virtual Texture
上面提到的两种Virtual Texture中,Texture的内容来源都是离线的,也就是我们需要将它们从磁盘或者光盘中加载到内存中。现在介绍的这个方案的Texture是运行时产生的,所以叫Procedural,在Unreal里称为Runtime Virtual Texture。这个方案首次提出是在Battlefield3中,另外一位华人工程师ChenKa在FarCry4中进行了改进,提出来叫Adaptive Virtual Texture的概念。与离线的Virtual Texture一样,仍然需要去维护一个Virtual Texture到Physical Texture的映射,这样的映射可以用Software实现,也可以用Hardware。
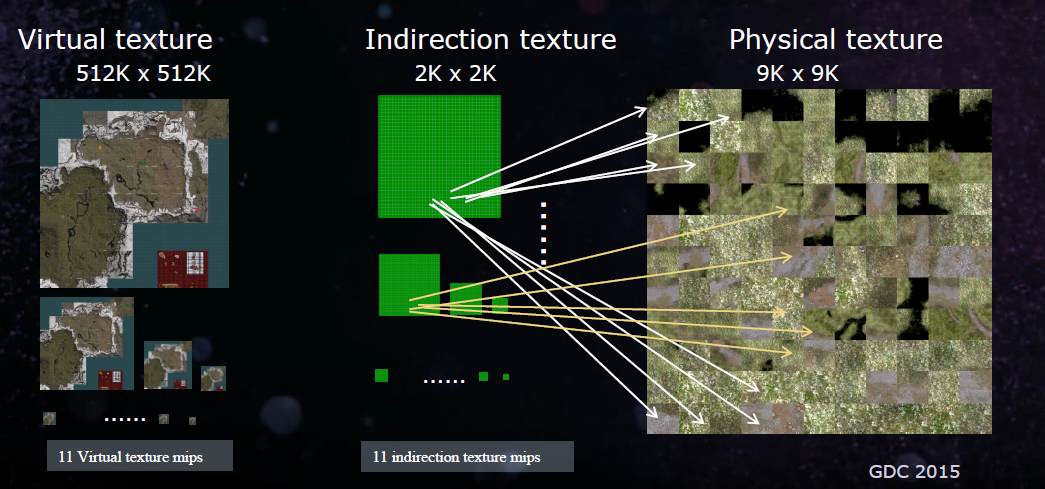
4.1 BattleFiled3方案
由于这项技术是用在地形渲染上的,对于地形渲染,以及对于大世界的地形渲染,如果将整张地形映射到一张Texture的坐标上,而且要保持精度足够,那虚拟纹理的坐标就会很大。假如我们用Software来实现,就会带来一个问题,就是Indirection Texture的大小会很大。为了解决这个问题,BattleFiled3使用了上文提到的Clip Map的技术,让Indirection Texture高精度的Mip只有部分存在。
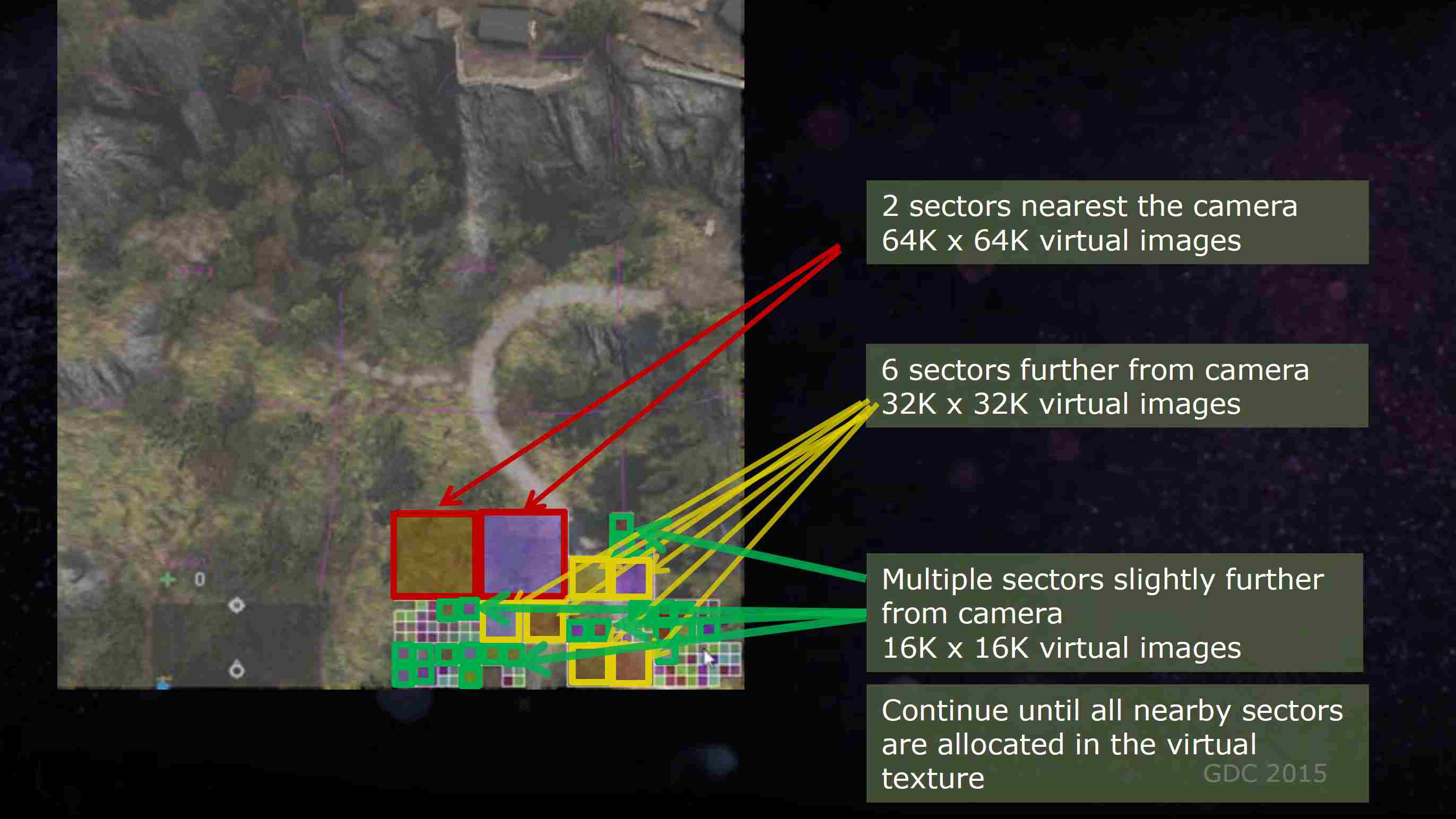
4.2 Adaptive Procedural Texture
FarCry4中的方案则更加彻底,它的想法是突破最高的MIP精度,也就是在MIP0的上面让虚纹理的Page更大,这样就超过了MIP0的精度。虚纹理的Page的设计也被设计成非等大的Page,允许虚纹理出现各种不同大小的Page。
以下描述是我对Adaptive Procedural Texture的个人理解,由于在反复看完PPT和GPU Pro中的文章后,发现ChenKa的书写中存在一定的错误,按照其中的说法是无法完成实现的,所以我只能根据他书写的内容,加上自己的推断来尽量还原实现。
首先,需要理解的是,虚纹理是个不存在的纹理,主要是用来寻址和易于理解,所以一切对虚纹理Page大小的修改,落实到实现的时候,其实是在更改Indirect Texture,所以上图显示不同大小Page的虚纹理其实是Indirect Texture存在这样不同大小的Page。
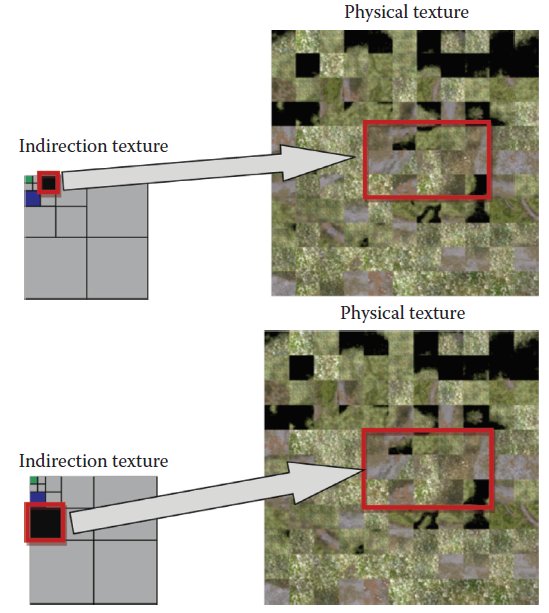
可以看这张图的左边。所以,我们根据相机的位置,其实改变大小的是Indirect Texture Page的大小。在之前的实现中,Indirect Texture的一个Page就是一个像素,这里就不同了,一个Page对应的是多个像素,也就是说,其实一个Page对应了多个物理纹理的Page,上图也体现了这一点。上图的错误在于,当Page变大之后,应该是覆盖更多的Page,而不是相同数量的Page。还有一个问题没有解决:虚纹理如何映射到Indirect Texture的?或者说是根据当前的位置如何去决定Terrain用到的Indirect Texture?这里引入另外一个概念:Sector,它用来描述地形块。

整个地形被分割成相同大小的Sector,每个Sector上存的是Indirect Texture的信息,包括位置和大小。这样,当采样地形某个位置的时候,就可以确定到某个Indirect Texture的像素,也就确定到了物理纹理的Page上,多了一次转换,即需要把Sector的坐标转换到Indirect Texture上。
以上是我根据ChenKa的描述来叙述的,其实换一种思路更好理解,把Sector理解成虚纹理,现在每个虚纹理的Page映射了多个物理纹理的Page,那么就需要更改Indirect Texture的Page大小。在实现的过程中还有一些细节,比如在变大或者变小的过程中,需要更改Mipmap的内容,直接拷贝旧内容会比较快。
这里的Virtual Image是Indirect Texture,另外在Feedback Rendering的时候除了要计算PageId和MIP level,还要加上一个Indirect Texture Page的大小。
4.3 Hardware Procedural Texture展望
上面说的是用Software的方式去实现,假如用Hardware来实现,一切似乎变得很简单,直接给虚纹理设置到精度最高,由于没有了Indirection Texture,只是直接的内存映射,所以不会出现内存占用过多的问题,只要根据相机位置确定MIP level即可。但是,由于并未实践过,需要去验证。由NASA的Mars项目可以看到,能支持的Texture尺寸非常大。
之前说了,这项技术主要被用在地形的渲染里面,当渲染地形的时候,可以将地形先渲染到类似于GBuffer的大贴图上,这个过程是分帧完成的。然后,再使用极简单的材质渲染地形,这样就大大降低了地形渲染中多层blending的消耗,同时也可以支持巨量动态的Decals。
三、后记
由于Virtual Texture所涉及的并没有很多高深的图形技术,只是在原有的技术上的一个优化,更多考验的是实现者的工程能力,本文只是粗浅介绍了Virtual Texture的实现原理,实现本身才是Virtual Texture的难点。下一篇准备以Unreal为例,谈谈Virtual Texture的工程实现。
Reference
[1]Chajdas, Matthaus G., et al. "Virtual texture mapping 101." GPU Pro (2010).
[2]Mittring, Martin, and Crytek GmbH. "Advanced virtual texture topics." ACM SIGGRAPH 2008 Games. 2008. 23-51.
[3]Widmark, Mattias. "Terrain in Battlefield 3: A modern, complete and scalable system." GDC Presentation publications. dice. se/attachments/GDC12_Terrain_in_Battlefield3. pdf (2012-05-31) (2012).
[4]Chen, K. "Adaptive virtual texture rendering in far cry 4." Game Developers Conference. 2015.
[5]Chen, Ka. "Adaptive Virtual Textures." GPU Pro 7: Advanced Rendering Techniques 131 (2016).
[6]Obert, Juraj, J. M. P. van Waveren, and Graham Sellers. "Virtual texturing in software and hardware." ACM SIGGRAPH 2012 Courses. 2012. 1-29.
[7]Van Waveren, J. M. P. "Software Virtual Textures." (2012).
[8]Hollemeersch, Charles, et al. "Accelerating virtual texturing using cuda." GPU Pro: advanced rendering techniques 1 (2010): 623-641.
[9]Cebenoyan, Cem. "Real Virtual Texturing Taking Advantage of DirectX11. 2 Tiled Resources." Game Developer Conference. 2014.
[10]Barrett, Sean. "Sparse virtual textures." Talk at Game Developers Conference. 2008.
Blow, Jonathan. "Terrain rendering at high levels of detail." Proceedings of the 2000 Game Developers Conference. Vol. 3. sn, 2000.
[11]Tanner, Christopher C., Christopher J. Migdal, and Michael T. Jones. "The clipmap: a virtual mipmap." Proceedings of the 25th annual conference on Computer graphics and interactive techniques. 1998.
[12]https://channel9.msdn.com/Events/Build/2013/4-063
[13]http://twvideo01.ubm-us.net/o1/vault/gdc2017/Presentations/Barb_Chad_EfficientTextureStreaming.pdf
[14]http://renderingpipeline.com/2012/03/megatextures-in-rage/
[15]https://docs.microsoft.com/en-us/windows/win32/direct3d11/tiled-resources
[16]https://vulkan.lunarg.com/doc/view/1.0.37.0/linux/vkspec.chunked/ch28s04.html
[17]https://developer.apple.com/documentation/metal/textures/managing_texture_memory?language=objc
[18]https://www.khronos.org/registry/OpenGL/extensions/ARB/ARB_sparse_texture.txt
文末,再次感谢李兵的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/li-bing-77-8,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!