
uSpringBone开源库测评
- 作者:admin
- /
- 时间:2019年07月25日
- /
- 浏览:4661 次
- /
- 分类:博物纳新
本期博物纳新要给大家推荐的这个开源库,也是在UWA DAY 2019上分享过的一个使用ECS和JobSystem改造的加速版SpringBone,叫做uSpringBone。
一、介绍
在开源库中我们常看到使用到ECS、Job System以及Burst编译器的项目。之前在【博物纳新】中也介绍过这类项目:
《Unity网格变形开源库测评》
《超级变变变,万人同屏开源库推荐!》
它们大都擅长于解决大量复杂计算的场景。
今天介绍的uSpringBone是在之前的SpringBone基础上,改成了ECS+JobSystem的版本。
原SpringBone链接:https://lab.uwa4d.com/lab/5b563ca3d7f10a201fd8c2a2
uSpringBone链接:https://lab.uwa4d.com/lab/5bf67e9d72745c25a836b5ca
二、项目解读
在项目中提供了一个Setup场景,用于展示uSpringBone的效果。同时还有原始版本的SpringBone作为对比参考。

在OriginSpringBone中,通过一个SpringManager来进行管理,需要添加弹簧效果的骨骼全都挂载在SpringManager上。
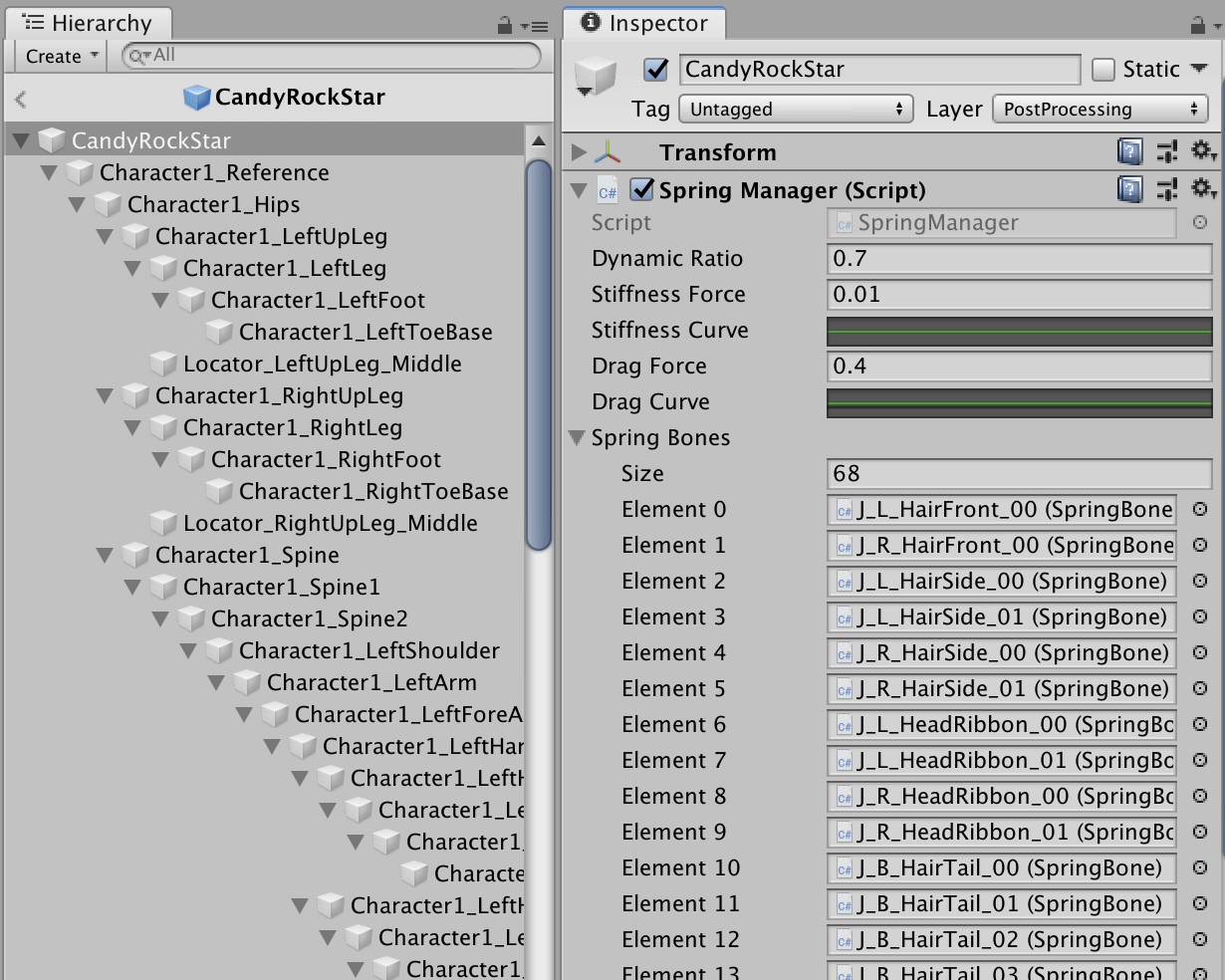
然后通过SpringManager中在LateUpdate里循环遍历这些SpringBone计算每根骨骼的弹力及位置,并进行碰撞冲突解决。
而uSpringBone的核心,就是把这些复杂的计算逻辑改成ECS版本,并通过JobSystem执行下发。
把uSpringBone的核心脚本找出来,是四个脚本:
- SphereColliderComponent:球形碰撞体组件,用于添加到需要计算碰撞的必要节点上。当然,由于要用Job System来加速,这必须是一个IComponentData类型的数据结构。
- SpringBoneComponent:弹簧骨骼组件,用于添加到需要应用弹簧效果的骨骼节点上,同样这也是一个IComponentData类型的数据。
- SpringBoneChain:弹簧骨骼管理组件,用于添加到一个所有SpringBone的父节点上。
- SpringBoneJobScheduler:SpringBone的运行进程管理脚本。
前两个Component组件都比较简单,主要定义了其中的一些属性及方法。主要的计算逻辑都在SpringBoneChain的Execute方法中。包含弹力计算、碰撞计算、位置计算等。
SpringBoneChain.cs中的Execute方法的核心代码如下:
// spring.
for (int i = 0; i<boneData.Length; ++i)
{
var bone = boneData[i];
// set root parent data.
...
// get local and grobal position.
...
// calculate force.
float3 force = mul(grobalRotation, (bone.boneAxis * bone.stiffnessForce)) / sqrDt;
force += (bone.previousEndpoint - bone.currentEndpoint) * bone.dragForce / sqrDt;
force += bone.springForce / sqrDt;
float3 temp = bone.currentEndpoint;
var dataTemp = boneData[i];
// calculate next endpoint position.
dataTemp.currentEndpoint = (dataTemp.currentEndpoint - dataTemp.previousEndpoint) + dataTemp.currentEndpoint + (force* sqrDt);
dataTemp.currentEndpoint = (normalize(dataTemp.currentEndpoint - grobalPosition) * dataTemp.springLength) + grobalPosition;
// collision.
for (int j = 0; j<selectedColliderList.Length; ++j)
{
var collider = colliderData[j];
var colliderPosition = position[selectedColliderList[j].entity].Value;
if (distance(dataTemp.currentEndpoint, colliderPosition) <= (bone.radius + collider.radius))
{
float3 normal = normalize(dataTemp.currentEndpoint - colliderPosition);
dataTemp.currentEndpoint = colliderPosition + (normal* (bone.radius + collider.radius));
dataTemp.currentEndpoint = (normalize(dataTemp.currentEndpoint - grobalPosition) * dataTemp.springLength) + grobalPosition;
}
}
dataTemp.previousEndpoint = temp;
// calculate next rotation.
float3 from = mul(parentRotation, bone.boneAxis);
float3 to = dataTemp.currentEndpoint - grobalPosition;
float diff = length(from - to);
quaternion targetRotation = Quaternion.identity;
if(float.MinValue<diff && diff<float.MaxValue)
targetRotation = Quaternion.FromToRotation(from, to);
// set calculated data.
dataTemp.grobalPosition = parentPosition + mul(parentRotation, localPosition);
dataTemp.grobalRotation = Quaternion.Lerp(dataTemp.grobalRotation, mul(targetRotation, parentRotation), 1f); // TODO: lerp parameter
parentPosition = dataTemp.grobalPosition;
parentRotation = dataTemp.grobalRotation;
// update data.
...
// update entity.
...
}
再在SpringBoneJobScheduler.cs脚本中,管理对SpringBoneChain的调用。在脚本上定义了执行顺序为-32000,以此来保证Job尽可能早地分发下去,最大程度利用Worker线程工作。
[ScriptExecutionOrder(-32000)]
public class SpringBoneJobScheduler : MonoBehaviour
{
...
}
三、性能测评
这么大费周章都是为了能有更好的性能表现,两种实现方式下性能到底有多大的差异呢?我们从FPS、CPU耗时、多线程分析等几个方面来做性能测评。
选择的测试场景为项目中给出的示例场景,包含了35个示例角色(68个SpringBone骨骼)。

在FPS的测试上,选择了两款高通CPU的安卓设备,都是中高端的机型,分别是骁龙845和骁龙660,也是这两年比较主流的CPU型号。分别选择IL2CPP和Mono两种编译方式进行打包,得到对应的FPS均值如下表:

从以上数据可以看出,uSpringBone相比于传统的SpringBone方式,还是有很明显的帧率提升效果的。在骁龙845这样的高端机上,即使同屏35个SpringBone的角色,帧率也是轻松超过30fps可以在40~50帧的范围内波动的,为手游更多人、更精致的画面效果提供了更多的可能性。
那么接下来就具体来看一下这些性能差异具体体现在哪些函数上,以及uSpringBone是如何充分发挥WorkerThread的作用的。
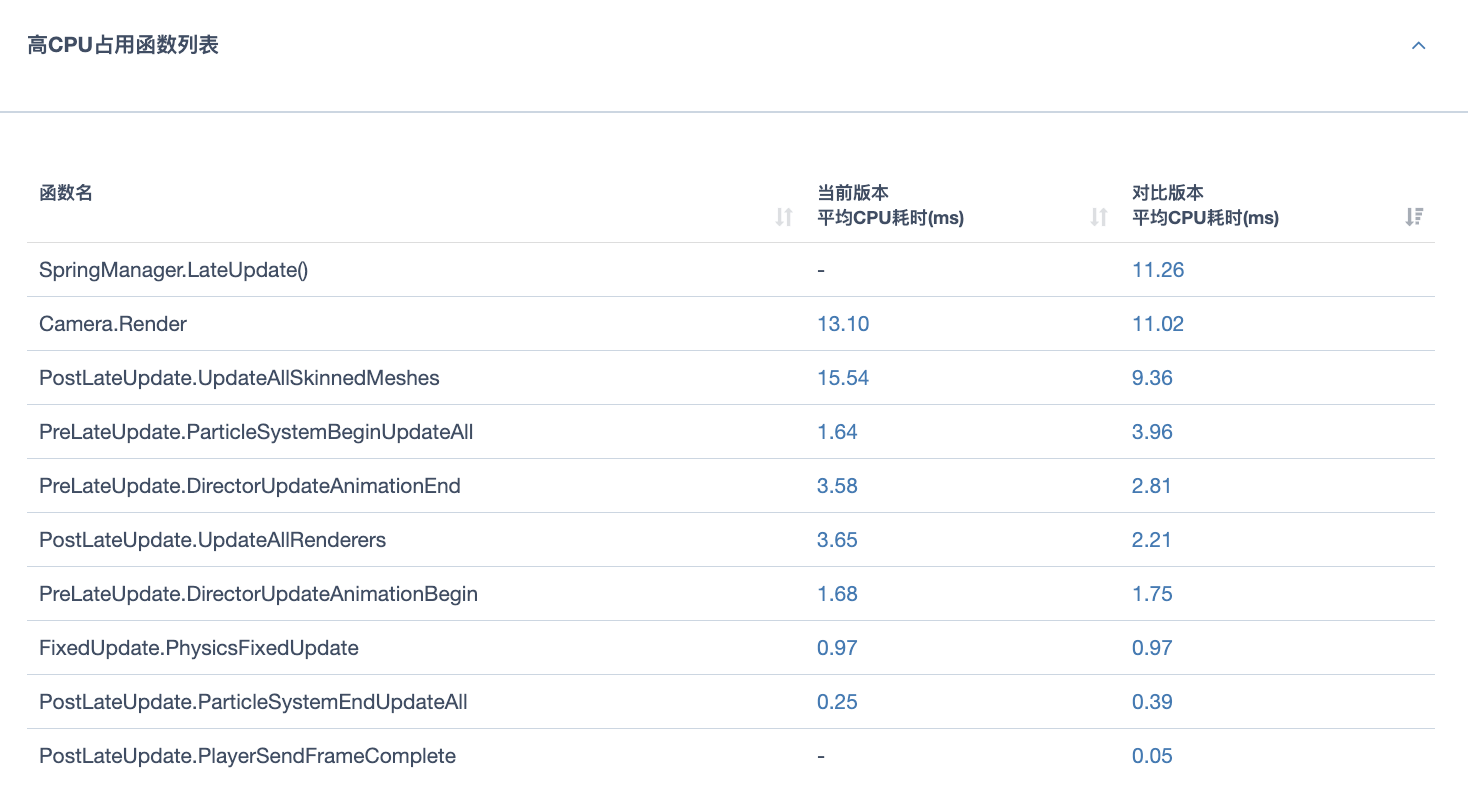
我们选择了骁龙845上的IL2CPP版本的两次测试数据,使用对比功能对比代码效率-CPU耗时的函数耗时。上图中对比版本为OriginSpringBone,当前版本为uSpringBone。可以看到OriginSpringBone中的SpringManager.LateUpdate耗时完全没有了。
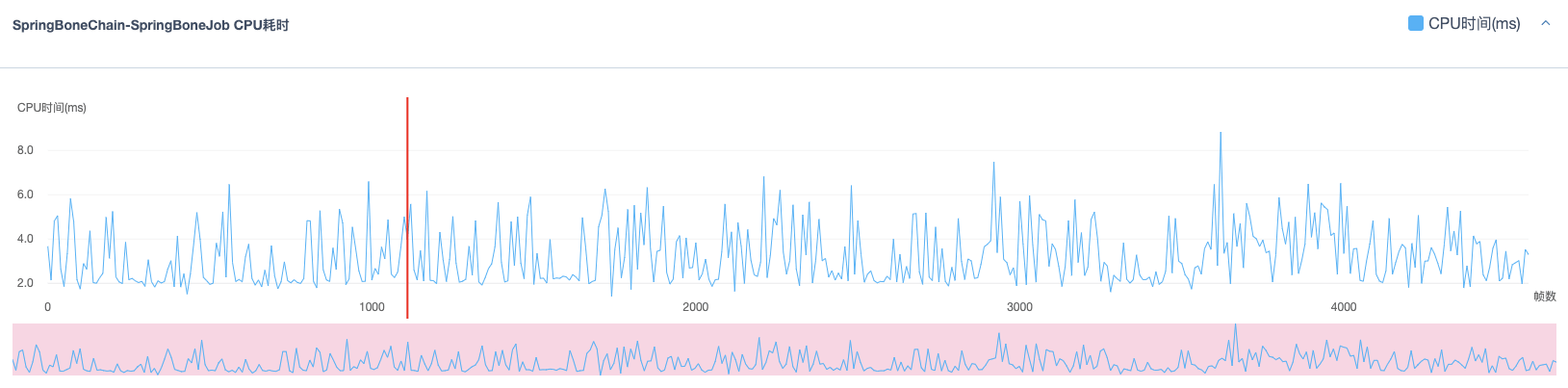
同时在uSpringBone的多线程耗时中,找到了SpringBoneChain-SpringBoneJob,也就是uSpringBone的Job System耗时,以下截图为其中一个Worker线程的耗时曲线,其他Worker线程中的耗时与之相近。
四、总结
uSpringBone是一个应用Dots优化计算密集型逻辑耗时的实践,可以看到改造过程并不复杂,性能优化效果却很明显。
今天的推荐就到这儿啦,或者它可直接使用,或者它需要您的润色,或者它启发了您的思路......
请不要吝啬您的点赞和转发,让我们知道我们在做对的事。当然如果您可以留言给出宝贵的意见,我们会越做越好。
【博物纳新】是UWA旨在为开发者推荐新颖、易用、有趣的开源项目,帮助大家在项目研发之余发现世界上的热门项目、前沿技术或者令人惊叹的视觉效果,并探索将其应用到自己项目的可行性。很多时候,我们并不知道自己想要什么,直到某一天我们遇到了它。
更多精彩内容请关注:lab.uwa4d.com