
用好Lua+Unity,让性能飞起来—LuaJIT性能坑详解
- 作者:admin
- /
- 时间:2017年04月23日
- /
- 浏览:26775 次
- /
- 分类:厚积薄发
导语:大家都知道LuaJIT比原生Lua快,快在JIT这三个字上。但实际情况是,LuaJIT的行为十分复杂。尤其JIT并不是一个简单的把代码翻译成机器码的机制,背后有很多会影响性能的因素存在,下面笔者将带大家一一说明。
这是侑虎科技第231篇原创文章,感谢作者招文勇供稿,欢迎转发分享,未经作者授权请勿转载。当然,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者博客:http://www.cnblogs.com/zwywilliam。同时,作者也是U Sparkle活动参与者哦,UWA欢迎更多开发朋友加入 U Sparkle开发者计划,这个舞台有你更精彩!
一、LuaJIT分为JIT模式和Interpreter模式,首先要弄清楚你使用的模式
同样的代码,在PC下可能以不足1ms的速度完成,而到了iOS却需要几十ms,是因为PC的CPU更好?是,但要知道顶级iOS设备的CPU单核性能已经是PC级,几十甚至百倍的差距显然不在这里。
这里要了解LuaJIT的两种运行模式:JIT、Interpreter
JIT模式:这是LuaJIT高效所在,简单地说就是直接将代码编译成机器码级别执行,效率大大提升(事实上这个机制没有说的那么简单,下面会提到)。然而不幸的是这个模式在iOS下是无法开启的,因为iOS为了安全,从系统设计上禁止了用户进程自行申请有执行权限的内存空间,因此你没有办法在运行时编译出一段代码到内存然后执行,所以JIT模式在iOS以及其他有权限管制的平台(例如PS4,XBox)都不能使用。
Interpreter模式:那么没有JIT的时候怎么办呢?还有一个Interpreter模式。事实上这个模式跟原生Lua的原理是一样的,就是并不直接编译成机器码,而是编译成中间态的字节码(bytecode),然后每执行下一条字节码指令,都相当于switch到一个对应的function中执行,相比之下当然比JIT慢。但好处是这个模式不需要运行时生成可执行机器码(字节码是不需要申请可执行内存空间的),所以任何平台任何时候都能用,跟原生Lua一样。这个模式可以运行在任何LuaJIT已经支持的平台,而且你可以手动关闭JIT,强制运行在Interpreter模式下。
我们经常说的将Lua编译成bytecode可以防止破解,这个bytecode是Interpreter模式的bytecode,并不是JIT编译出的机器码(事实上还有一个在bytecode向机器码转换过程中的中间码SSA IR,有兴趣可以看LuaJIT官方WIKI),比较坑的是可供32位版本和64位版本执行的bytecode还不一样,这样才有了著名的2.0.x版本在iOS加密不能的坑。
二、JIT模式一定更快?不一定!
iOS不能用JIT,那么安卓下应该就可以飞起来用了吧?用脚本语言获得飞一般的性能,让我大红米也能对杠iPhone!然而,并不是安卓不能开启JIT,而是JIT的行为极其复杂,对平台高度依赖,导致它在以arm为主的安卓平台下,未必能发挥出在PC上的威力,要知道LuaJIT最初只是考虑PC平台的。
首先我们要知道,JIT到底怎么运作的。LuaJIT使用了一个很特殊的机制(也是其大坑),叫做trace compiler的方式,来将代码进行JIT编译的。什么意思呢?它不是简单的像C++编译器那样直接把整套代码翻译成机器码就完事了,因为这么做有三个问题:
- 编译时间长,这点比较好理解。
- 更关键的是,作为动态语言,难以优化。例如对于一个function foo(a),这个a到底是什么类型,并不知道,对这个a的任何操作,都要检查类型,然后根据类型做相应处理,哪怕就是一个简单的a+b都必须这样(a和b完全有可能是两个表,实现的__add元方法),实际上跟Interpreter模式就没什么区别了,根本起不到高效运行的作用;
- 很多动态类型无法提前知道类型信息,也就很难做链接(知道某个function的地址、知道某个成员变量的地址)。
那怎么办呢?这个解决方案可以另写一篇文章了。这里只是简单说一下LuaJIT采用的trace compiler方案:首先所有的Lua都会被编译成bytecode,在Interpreter模式下执行,当Interpreter发现某段代码经常被执行,比如for循环代码(是的,大部分性能瓶颈其实都跟循环有关),那么LuaJIT会开启一个记录模式,记录这段代码实际运行每一步的细节(比如里头的变量是什么类型,猜测是数值还是table)。有了这些信息,LuaJIT就可以做优化了:如果a+b发现就是两个数字相加,那就可以优化成数值相加;如果a.xxx就是访问a下面某个固定的字段,那就可以优化成固定的内存访问,不用再走表查询。最后就可以将这段经常执行的代码JIT化。
这里可以看到,第一,Interpreter模式是必须的,无论平台是否允许JIT,都必须先使用Interpreter执行;第二,并非所有代码都会JIT执行,仅仅是部分代码会这样,并且是运行过程中决定的。
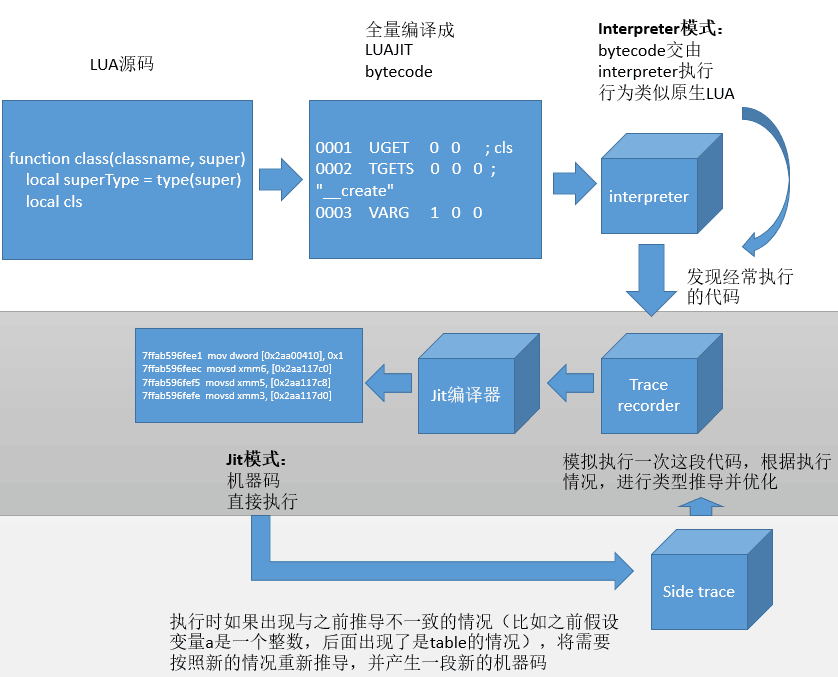
三、要在安卓下发挥JIT的威力,必须要解决掉JIT模式下的坑:JIT失败
那么说了JIT怎么运作的,看起来没什么问题呀,为何说不一定更快呢?这里就有另一个大坑:LuaJIT无法保证所有代码都可以JIT化,并且这点只能在尝试编译的过程中才知道。
听起来好像没什么概念。事实上,这种情况的出现,有时是毁灭性的,可以让你的运行速度下降百倍。对,你没看错,是百倍,几ms的代码突然飙到几百ms。具体的感受,可以看看我们之前的技术推文《Unity项目常见Lua解决方案性能比较》中S3的测试数据,一个纯Lua代码的用例(Vector3.Normalize没有经过c#),却出现了巨大的性能差异。而JIT失败的原因非常多,而当你理解背后的原理后会知道,在安卓下JIT失败的可能要比PC上高得多。
根据我们在安卓下的使用来看,最常见的有以下几种,并且后面写上了应对方案。
3.1 可供代码执行的内存空间被耗尽->要么放弃JIT,要么修改LuaJIT的代码
要JIT,就要编译出机器码,放到特定的内存空间。但是arm有一个限制,就是跳转指令只能跳转前后32MB的空间,这导致了一个巨大的问题:LuaJIT生成的代码要保证在一个连续的64MB空间内,如果这个空间被其他东西占用了,LuaJIT就会分配不出用于jit的内存,而目前LuaJIT会疯狂重复尝试编译,最后导致性能处于瘫痪的状态。
虽然网上有一些不修改LuaJIT的方案,在Lua中调用LuaJIT的jit.opt的api尝试将内存空间分配给LuaJIT,但根据我们的测试,在Unity上这样做仍然无法保证所有机器上能够不出问题,因为这些方案的原理要抢在这些内存空间被用于其他用途前全部先分配给LuaJIT,但是uLua可以运行的时候已经是程序初始化非常后期的阶段,这个时候众多的Unity初始化流程可能早已耗光了这块内存空间。相反Cocos-2dx这个问题并不多见,因为LuaJIT运行早,有很大的机会提前抢占内存空间。
无论从代码看还是根据我们的测试以及LuaJIT maillist的反馈来看,这个问题早在2.0.x就存在,更换2.1.0依然无法解决,我们建议,如果项目想要使用jit模式,需要在android工程的Activity入口中就加载LuaJIT,做好内存分配,然后将这个luasate传递给Unity使用。如果不愿意趟这个麻烦,那可以根据项目实际测试的情况,考虑禁用jit模式(见文章第9点)。一般来说,Lua代码越少,遇到这个问题的可能性越低。
3.2 寄存器分配失败->减少local变量、避免过深的调用层次
很不幸的一点是,arm中可用的寄存器比x86少。LuaJIT为了速度,会尽可能用寄存器存储local变量,但是如果local变量太多,寄存器不够用,目前JIT的做法是:放弃治疗(有兴趣可以看看源码中asm_head_side函数的注释)。因此,我们能做的,只有按照官方优化指引说的,避免过多的local变量,或者通过do end来限制local变量的生命周期。
3.3 调用c函数的代码无法JIT->使用ffi,或者使用2.1.0beta2
这里要提醒一点,调用c#,本质也是调用c,所以只要调用c#导出,都是一样的。而这些代码是无法JIT化的,但是LuaJIT有一个利器,叫ffi,使用了ffi导出的c函数在调用的时候是可以JIT化的。
另外,2.1.0beta2开始正式引入了trace stitch,可以将调用c的lua代码独立起来,将其他可以jit的代码jit掉,不过根据作者的说法,这个优化效果依然有限。
3.4 JIT遇到不支持的字节码->少用for in pairs,少用字符串连接
有非常多bytecode或者内部库调用是无法JIT化的,最典型就是for in pairs,以及字符串连接符(2.1.0开始支持JIT)。
具体可以看http://wiki.luajit.org/NYI,只要不是标记yes或者2.1的代码,就不要过多使用。
四、怎么知道自己的代码有没有JIT失败?使用v.lua
完整的LuaJIT的exe版本都会带一个JIT目录,下面有大量LuaJIT的工具,其中有一个v.lua,这是LuaJIT Verbose Mode(另外还有一个很重要的叫p.lua,luajit profiler,后面会提到),可以追踪LuaJIT运行过程中的一些细节,其中就可以帮你追踪JIT失败的情况。
local verbo = require("jit.v")
verbo.start()
当你看到以下错误的时候,说明你遇到了JIT失败:
failed to allocate mcode memory,对应错误3.1
NYI: register coalescing too complex,对应错误3.2
NYI: C function,对应错误3.3(这个错误在2.1.0beta2中已经移除,因为有trace stitch)
NYI: bytecode,对应错误3.4
这在LuaJIT.exe下使用会很正常,但要在Unity下用上需要修改v.lua的代码,把所有out:write输出导向到Debug.Log里。
五、照着LuaJIT的偏好来写Lua代码
最后,趟完LuaJIT本身的深坑,还有一些相对轻松的坑,也就是你如何在写Lua的时候,根据LuaJIT的特性,按照其喜好的方式来写,获得更好的性能
这里可以看我们的另一篇文章《LuaJIT官方性能优化指南和注解》,这里比较详细地说明如何写出适合LuaJIT的Lua代码。
六、如果可以,用传统的local function而非class的方式来写代码
由于cocos2dx时代的推广,目前主流的Lua面向对象实现(例如Cocos-2dx以及uLua的simpleframework集成的)都依赖metatable来调用成员函数,深入读过LuaJIT后就会知道,在Interpreter模式下,查找metatable会产生多一次表查找,而且self:Func()这种写法的性能也远不如先cache再调用的写法:local f = Class.Func; f(self),因为local cache可以省去表查找的流程,根据我们的测试,Interpreter模式下,结合local cache和移除metatable流程,可以有2~3倍的性能差。
而LuaJIT官方也建议尽可能只调用local function,省去全局查找的时间。比较典型的就是Vector3的主流Lua实现都是基于metatable做的,虽然代码更优雅,更接近面向对象的风格(va:Add(vb)对比Vector3.Add(va, vb))但是性能会差一些。当然,这点可以根据项目的实际情况来定,不必强求,毕竟要在代码可读性和性能间权衡。我们建议在高频使用的对象中(例如Vector3)使用function风格的写法,而主要的代码可以继续保持class风格的写法。
七、不要过度使用C#回调Lua,这非常慢
目前LuaJIT官方文档(ffi的文档)中建议优先进行Lua调用c,而尽可能避免c回调Lua。当然常用的UI回调因为频次不高所以一般可以放心使用,但是如果是每帧触发的逻辑,那么直接在Lua中完成,比反复从Lua->C->Lua的调用要更快。这里有一篇blog分析,可以参考:http://www.cppblog.com/tdzl2003/archive/2013/02/24/198045.html
八、借助ffi,进一步提升LuaJIT与C/C#交互的性能
ffi是LuaJIT独有的一个神器,用于进行高效的LuaJIT与C交互。其原理是向LuaJIT提供C代码的原型声明,这样LuaJIT就可以直接生成机器码级别的优化代码来与C交互,不再需要传统的Lua API来做交互。
我们进行过简单的测试,利用ffi的交互效率可以有数倍甚至10倍级别的提升(当然具体要视乎参数列表而定),真可谓飞翔的速度。而借助ffi也是可以提高LuaJIT与C#交互的性能。原理是利用ffi调用自己定义的C函数,再从C函数调用C#,从而优化掉LuaJIT到c这一层的性能消耗,而主要留下C到C#的交互消耗。在上一篇中我们提到的300ms优化到200ms,就是利用这个技巧达到的。
必须要注意的是,ffi只有在JIT开启下才能发挥其性能,如果是在iOS下,ffi反而会拖慢性能。所以使用的时候必须要做好快关。
首先,我们在c中定义一个方法,用于将C#的函数注册到c中,以便在c中可以直接调用C#的函数,这样只要LuaJIT可以ffi调用c,也就自然可以调用C#的函数了
void gse_ffi_register_csharp(int id, void* func)
{
s_reg_funcs[id] = func;
}
这里,id是一个你自由分配给C#函数的id,lua通过这个id来决定调用哪个函数。
然后在C#中将C#函数注册到c中
[DllImport(LUADLL, CallingConvention = CallingConvention.Cdecl, ExactSpelling = true)]
public static extern void gse_ffi_register_csharp(int funcid, IntPtr func);
public static void gse_ffi_register_v_i1f3(int funcid, f_v_i1f3 func)
{
gse_ffi_register_csharp(funcid, Marshal.GetFunctionPointerForDelegate(func));
}
gse_ffi_register_v_i1f3(1, GObjSetPositionAddTerrainHeight);//将GObjSetPositionAddTerrainHeight注册为id1的函数
然后Lua中使用的时候,这么调用
local ffi = require("ffi")
ffi.cdef[[
int gse_ffi_i_f3(int funcid, float f1, float f2, float f3);
]]
local funcid = 1
ffi.C.gse_ffi_i_f3(funcid, objID, posx, posy, posz)
就可以从Lua中利用ffi调用C#的函数了
可以类似ToLua,将这个注册流程的代码自动生成。
九、既然LuaJIT坑那么多那么复杂,为什么不用原生Lua?
无法否认,LuaJIT的JIT模式非常难以驾驭,尤其是其在移动平台上的性能表现不稳定导致在大型工程中很难保证其性能可靠。那是不是干脆转用原生Lua呢?
我们的建议是,继续使用LuaJIT,但是对于一般的团队而言,使用Interpreter模式。
目前根据我们的测试情况来看,LuaJIT的Interpreter模式夸平台稳定性足够,性能行为也基本接近原生Lua(不会像JIT模式有各种trace compiler带来的坑),但是性能依然比原生Lua有绝对优势(平均可以快3~8倍,虽然不及JIT模式极限几十倍的提升),所以在游戏这种性能敏感的场合下面,我们依然推荐使用LuaJIT,至少使用Interpreter模式。这样项目既可以享受一个相对ok的语言性能,同时又不需要过度投入精力进行Lua语言的优化。
此外,LuaJIT原生提供的profiler也非常有用,更复杂的字节码也更有利于反破解。如果团队有能力解决好LuaJIT的编译以及代码修改维护,LuaJIT还是非常值得推荐的。
不过,LuaJIT目前的更新频率确实在减缓,最新的LuaJIT2.1.0 beta2已经有一年没有新的beta更新(但这个版本目前看也足够稳定),在标准上也基本停留在Lua5.1上,没有5.3里int64/utf8的原生支持,此外由于LuaJIT的平台相关性极强,一旦希望支持的平台存在兼容性问题的话,很可能需要自行解决甚至只能转用原生Lua。所以开发团队需要自己权衡。但从我们的实践情况来看,LuaJIT使用5.1的标准再集成一些外部的int64/utf解决方法就能很好地适应跨平台、国际化的需求,并没有实质的障碍,同时继续享受这个版本的性能优势。
我们的项目,在战斗时同屏规模可达100+角色,在这样的情况下Interpreter的性能依然有相当的压力。所以团队如果决定使用Lua开发,仍然要注意Lua和C #代码的合理分配,高频率的代码尽量由C#完成,Lua负责组装这些功能模块以及编写经常需要热更的代码。
最后,怎么打开Interpreter模式?非常简单,最你执行第一行Lua前面加上。
if jit then
jit.off();jit.flush()
end
文末,再次感谢招文勇的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
也欢迎大家来积极参与U Sparkle开发者计划,简称"US",代表你和我,代表UWA和开发者在一起!



