扒一扒Profiler中这几个“占坑鬼”
- 作者:admin
- /
- 时间:2016年03月20日
- /
- 浏览:30541 次
- /
- 分类:厚积薄发
WaitForTargetFPS、Gfx.WaitForPresent 和 Graphics.PresentAndSync是我们经常会被问到的参数。想必正在读此文的你也经常在Profiler中遇到过这几项CPU开销过大的情况。对此,我们今天就来好好地聊一聊这几个参数的具体含义和触发规则。
WaitForTargetFPS
该参数一般出现在CPU开销过低,且通过设定了目标帧率的情况下(Application.targetFrameRate)。当上一帧的耗时低于目标帧率的耗时时,将会在本帧产生一个WaitForTargetFPS的空闲等待耗时,以维持目标帧率。
解析:该项在Unity引擎的主循环中其实是最早执行的,即引擎实际上是根据上一帧的CPU耗时,在当前帧中通过增补WaitForTargetFPS的方式来将运行FPS维持到目标值。比如,目标帧率为30帧/秒,上一帧耗时15ms,那么当前帧中WaitForTargetFPS将会是18(33-15)ms,但是这一帧中其他耗时为28ms,那么在Profiler中这一帧的总耗时就变成了46(18+28)ms。
因此,由该值造成了Profiler开销较高的现象,其实是耗时的“假象”,在优化过程中,你对它可以“视而不见”。
Gfx.WaitForPresent && Graphics.PresentAndSync
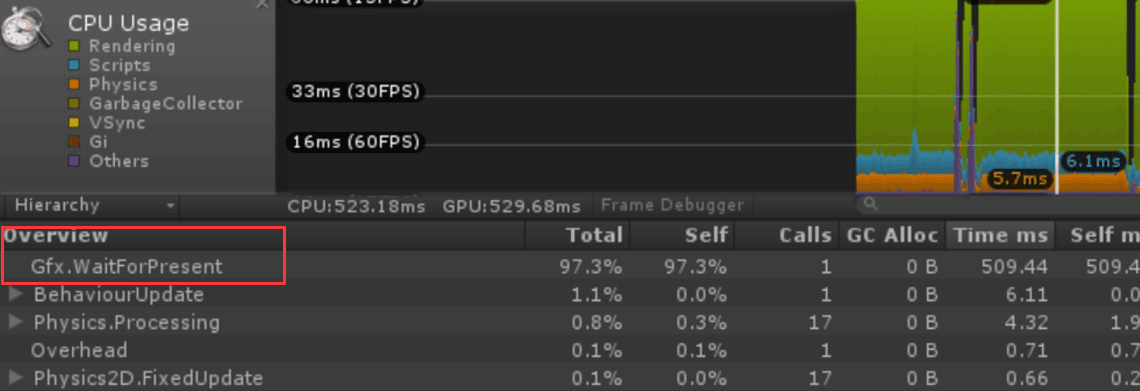
这两个参数在Profiler中经常出现CPU占用较高的情况,且仅在发布版本中可以看到。究其原因,其实是CPU和GPU之间的垂直同步(VSync)导致的,之所以会有两种参数,主要是与项目是否开启多线程渲染有关。当项目开启多线程渲染时,你看到的则是Gfx.WaitForPresent;当项目未开启多线程渲染时,看到的则是Graphics.PresentAndSync。
Graphics.PresentAndSync 是指主线程进行Present时的等待时间和等待垂直同步的时间。Gfx.WaitForPresent其字面意思同样也是进行Present时需要等待的时间,但这里其实省略了很多的内容。其真实的意思应该是为了在渲染子线程(Rendering Thread)中进行Present,当前主线程(MainThread)需要等待的时间。听起来依然很拗口,下面,我们就来进行详细地解释。
当项目开启多线程程渲染时,引擎会将Present等相关工作尽可能放到渲染线程去执行,即主线程只需通过指令调用渲染线程,并让其进行Present,从而来降低主线程的压力。但是,当CPU希望进行Present操作时,其需要等待GPU完成上一次的渲染。如果GPU渲染开销很大,则CPU的Present操作将一直处于等待操作,其等待时间,即为当前帧的Gfx.WaitForPresent时间,如下图所示。
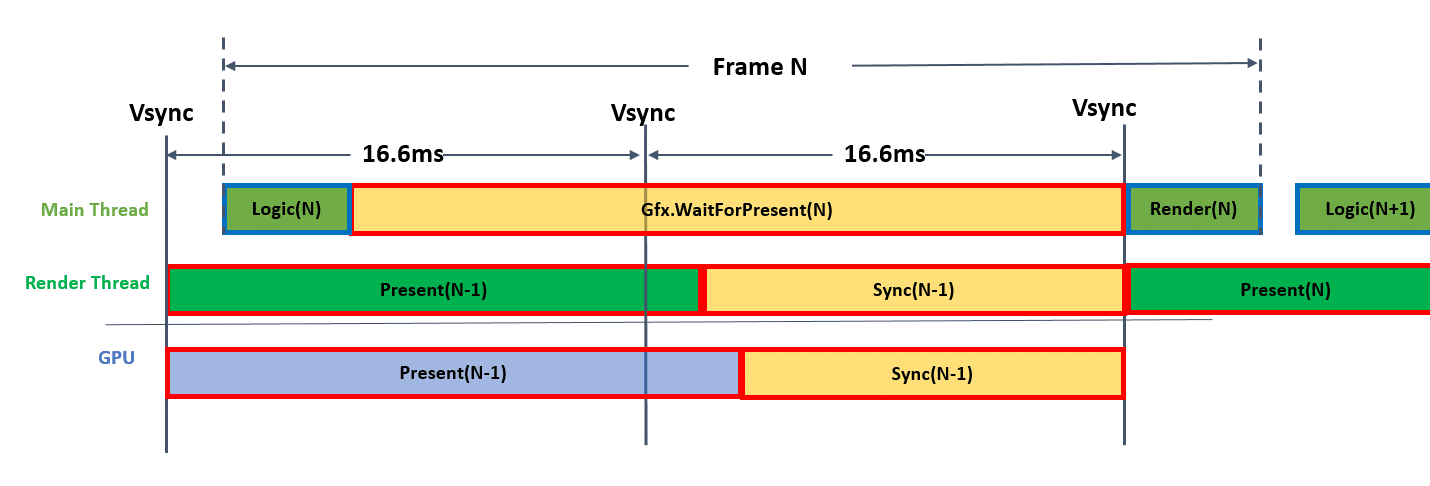
同理,当项目未开启多线程渲染时,引擎会在主线程中进行Present(当前绝大多数的移动游戏均在使用该中操作),当然,Present操作同样需要等待GPU完成上一次的渲染。如果GPU渲染开销很大,则CPU的Present操作将一直处于等待操作,其等待时间,即为当前帧的Graphics.PresentAndSync时间,如下图所示。
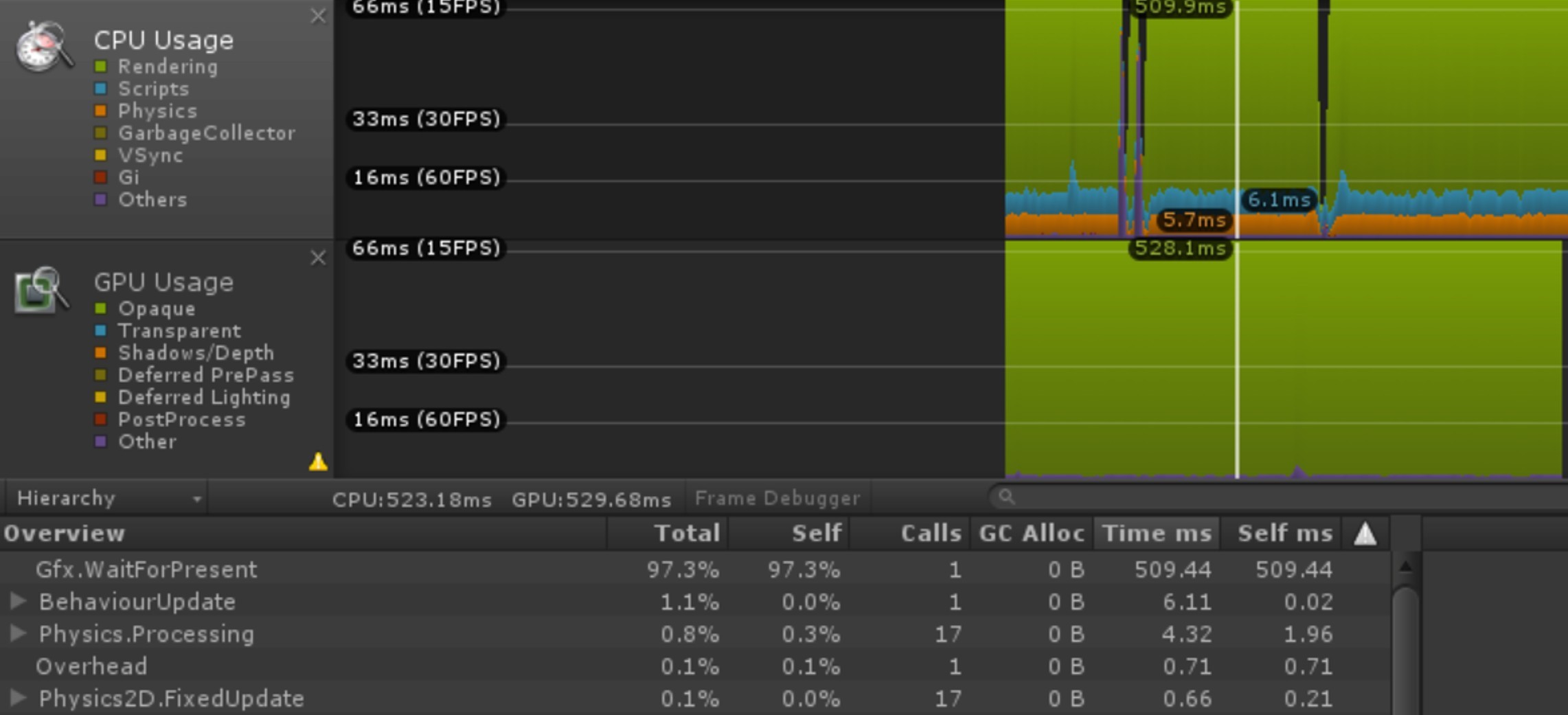
我们做了一个较为极端的例子来展示这种情况。在Unity 5.3.3版本上,创建60个全屏UIPanel,分别开启和关闭多线程渲染,并不设置TargetFPS。那么,在三星S6设备上该参数的CPU开销如下:
开启多线程渲染时:
关闭多线程渲染时:
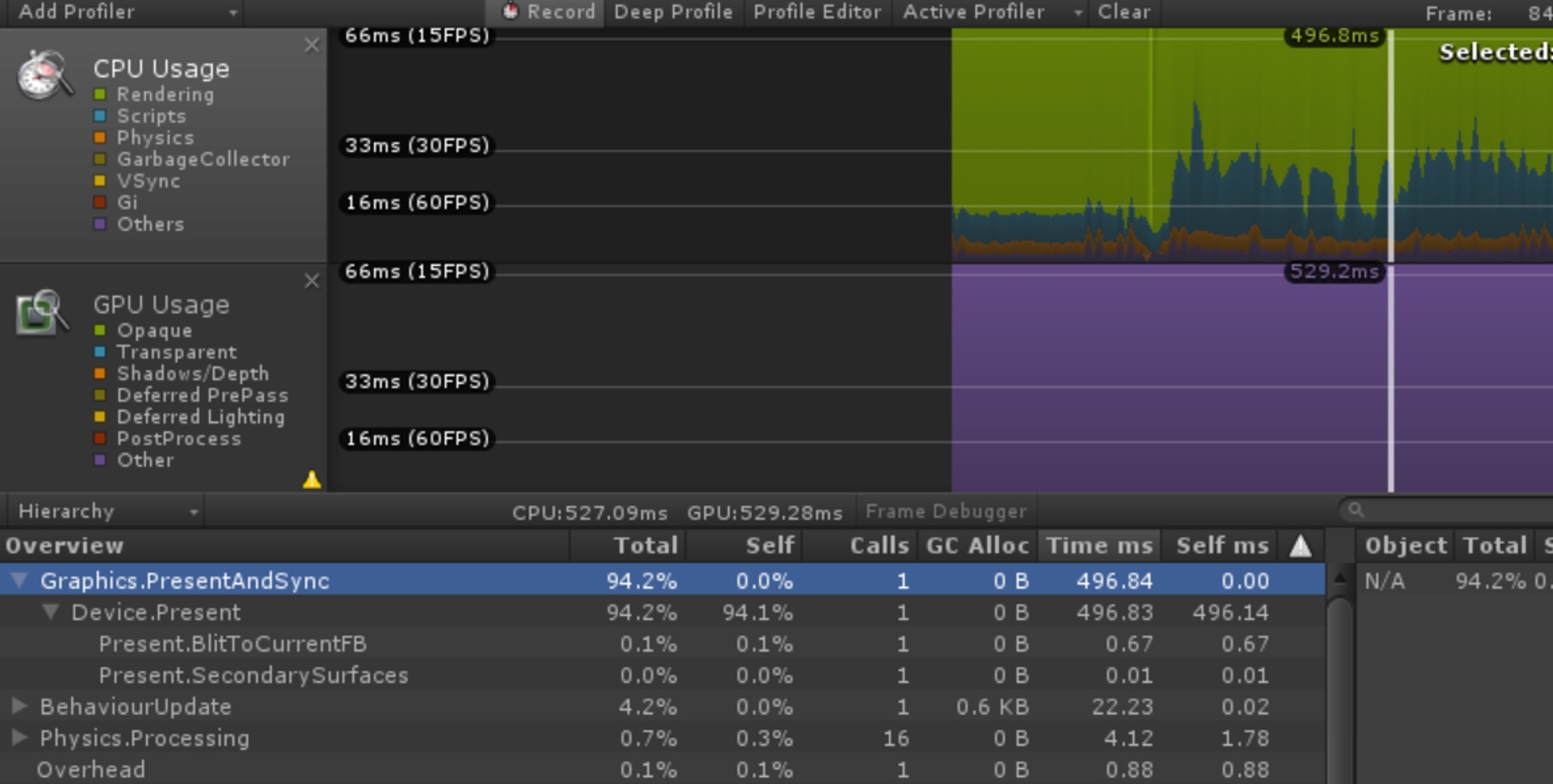
所以,如果你的项目中,Gfx.WaitForPresent或Graphics.PresentAndSync的CPU耗时非常高时,其实并不是它们自己做了什么神秘的操作,而是你当前的渲染任务太重,GPU负载过高所致。
同时,对于开启垂直同步的项目而言,Gfx.WaitForPresent 和 Graphics.PresentAndSync也会出现CPU占用较高的情况。在解释这种问题之前,我们先以“大家乘坐地铁”来举个例子。一般来说,地铁到达每一站的时间均是平均且一定的,假设每10分钟一班接走一批乘客。但是几乎没有多少乘客可以按点到达,如果提前两分钟到达,则只需要等待两分钟即可乘上地铁,但是,如果你错过了,哪怕只差了一分钟,那么你也不得不再等待九分钟才能乘上地铁。
上述的情况我们经常会遇到。在GPU的渲染流水线中,其转换front buffer和back buffer的工作原理和“乘坐地铁”其实是一致的。大家可以把GPU的流水线简单地想象成为一列地铁。对于移动设备来说,GPU的帧率一般为30帧/秒或60帧/秒,即VSync每33ms或每16.6ms“到站一次”,CPU的Present即为“乘客乘上地铁”,然后前往各自的目的地。与乘客的早到和晚到一样,CPU的Present也会出现类似的情况,比如:
CPU端开销非常小,Present在很早即被执行,但此时VSync还没到,则会出现较高的等待时间,即Gfx.WaitForPresent 和 Graphics.PresentAndSync的CPU开销看上去很高。下图为Unity 5.3.3版本上,一个空场景在不开启多线程渲染、不设置TargetFPS的情况下,Graphics.PresentAndSync在三星S6设备上的CPU占用情况。
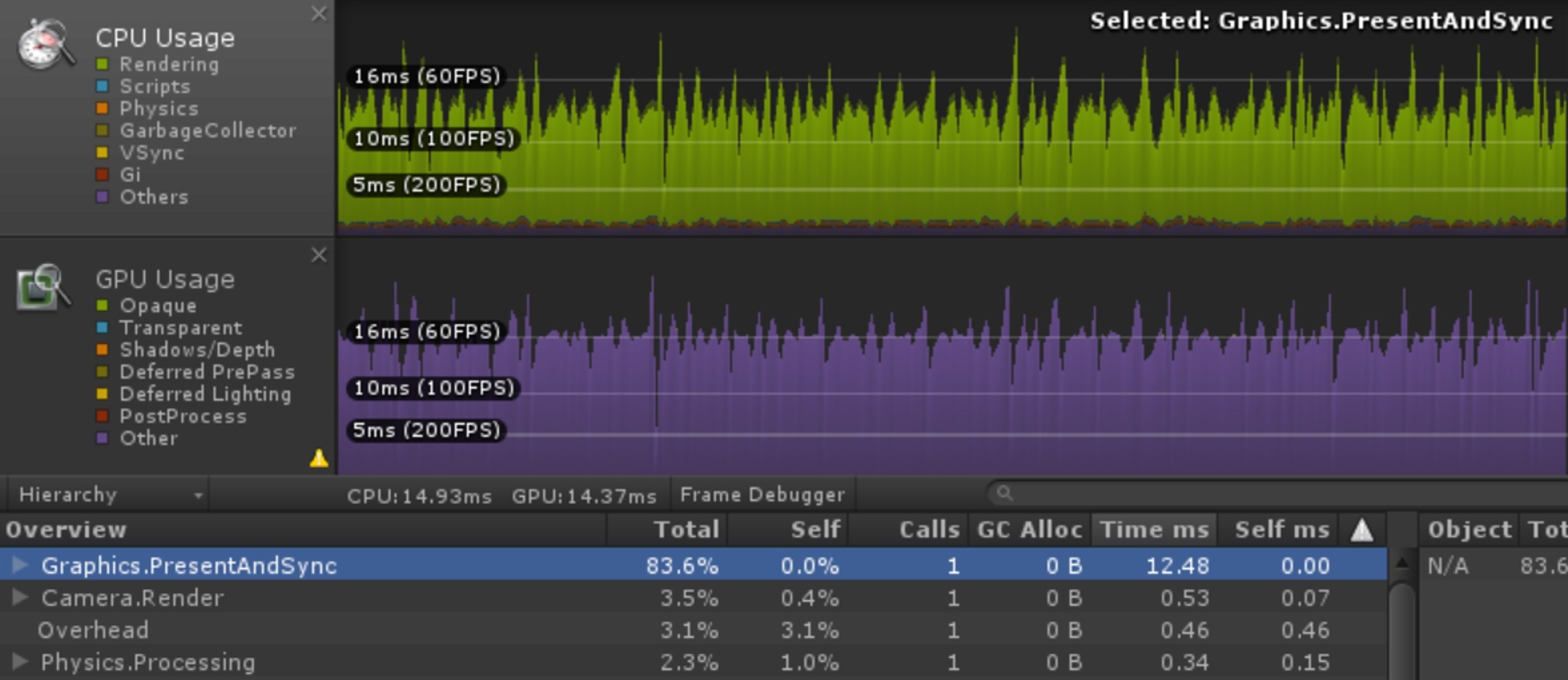
CPU端开销很高,使得Present执行时错过了VSync操作,这样,Present将不得不等待下一次VSync的到来,从而造成了Gfx.WaitForPresent 和 Graphics.PresentAndSync的CPU开销较高。这种情况在CPU端加载过量资源时特别容易发生,比如WWW加载较大的AssetBundle、Resource.Load加载大量的Texture等等。
通过以上的讲解,我们希望此刻的你已经对Gfx.WaitForPresent 和 Graphics.PresentAndSync已经有了深入的理解。这两个参数无论CPU占用多少,其实都不是这两个参数的自身问题,而是项目的其他部分造成。对此,我们做一个总结,以方便你进一步加深印象。
造成这两个参数的CPU占用较高的原因主要有以下三种原因:
CPU开销非常低,所以CPU在等待GPU完成渲染工作或等待VSync的到来;
CPU开销很高,使Present错过了当前帧的VSync,即不得不等待下一次VSync的到来;
GPU开销很高,CPU的Present需要等待GPU上一帧渲染工作的完成。
最后,如何优化并降低这两个参数的CPU占用呢? 那就是,忽略Gfx.WaitForPresent 和 Graphics.PresentAndSync这两个参数,优化其他你能优化的一切!
有没有一种被欺骗很久的感觉,还好侑虎君救了你呀~