Lua的CPU开销性能优化
- 作者:admin
- /
- 时间:2017年09月14日
- /
- 浏览:15182 次
- /
- 分类:厚积薄发
这是一篇着重介绍如何写好Lua代码,并做好优化工作的技术文章。文中笔者并没有介绍那些通俗的优化方法,而是首先总结了自己在优化过程中常见的性能问题,并通过实际优化案例的分析,来为大家提供更为实在的参考。
大家好,我是舒航,现任职于心动网络,主要负责《仙境传说RO:守护永恒的爱》(以下简称“RO”)的优化工作。今天主要想和大家分享一下,我这段时间在优化Lua的CPU性能方面的一些经验。
上一篇文章主要讲的是写一个LuaProfiler的思路,即如何快速定位到内存和CPU问题。而这一篇则着重于介绍如何写好Lua代码,以及优化的一些经验。在我优化RO和隔壁项目组手游的CPU性能时,发现CPU性能问题非常个性化,两个项目遇到的问题截然不同。而通用的Lua性能优化的Tips,往往并不能解决问题。所以这篇文章的前半部分是我总结的优化过程中常见的性能问题,后半部分是实际优化案例的一个分析,希望这样的形式更能帮到大家。
常见优化
首先需要说明的是,在我们项目中用的是Lua5.3,并且没有用到LuaJIT。
常见优化主要是参考了Lua作者Roberto Ierusalimschy所写的Lua性能优化建议:
https://www.lua.org/gems/sample.pdf
一、使用局部变量
这个点是绝大部分Lua性能问题产生的原因,尤其是和一个频繁调用的函数组合,会产生大量的开销。总的来说,我们在一个频繁调用的函数内,应该避免重复地去查询Table,应该把Table内我们常用的值缓存起来。
这里的值通常有两种: 1)函数 2)对象
虽然Lua是first-class,但是我发现实际使用中,大家意识上还是认为函数有别于其他值。所以分开来列举,方便大家对号入座。
使用局部变量是优化Lua性能的一条重要准则。
不管是函数还是对象,不管是Lua自身的库,还是我们自己写的,在Lua中都是储存在_G中的某个节点下。当我们调用一个函数/对象的时候,Lua首先会去他们的表中查找到这个函数/对象,而我们使用局部变量的话,由于Lua的局部变量是储存在寄存器(这里的寄存器不对应CPU的寄存器)内的,所以这个访问就会快很多。更严重的是,如果使用的是父类的函数/对象,还会触发__index,这样不仅会有额外的耗时还有内存开销。
对于不熟悉Lua的开发者来说,容易忽视局部变量的使用,而有些时候这会造成比较严重的性能问题。比较常见的就是写UI的同学在一个定时器或者一个循环内,使用GetComponent来获取组件然后进行一些操作。由于没有用变量缓存起来,每次用完了就抛弃,再用再获取。这不仅会造成很大的耗时,还会造成很大的内存开销,而写UI的工作又容易被大家所忽视,所以目前为止,我发现大部分项目这一块都有优化的空间。
这里提供了一段缓存Lua函数的代码(摘自Roberto原文):
function memoize(f)
local mem = {}
setmetatable(mem, { __mode = "kv" })
return function(x)
local r = mem[x]
if r == nil then
r = f(x)
mem[x] = r
end
return r
end
end
二、使用对象池
现在大部分团队,在使用Lua的时候,一般只用来写一些UI界面。而UI界面经常交给项目组的新人来做,以熟悉项目代码,所以这里的性能问题很容易被大家所忽视。这里经常遇到的性能问题一般出现在复杂滚动列表的重用、消息协议的重用、以及C#对象的重用中。
在我帮隔壁项目组优化性能的时候,就发现一个有趣的现象。他们项目Lua使用的不重度,但是平均每帧分配内存3.4KB,而RO高峰时期的内存分配也只有0.5KB,是RO的17倍。每帧Lua耗时在0.47ms,是RO的20%-30%。总体来说,对于普通使用Lua的团队来说这里面已经有很大的性能问题了,只是总量比较少,影响不是那么大。
而造成这么大性能问题的原因只有两个,一个是在一个定时器内频繁地给GameObject设位置,一个是每隔几帧收发一条移动消息。最后优化成,设位置时避免了重复创建LuaVector3,移动消息做了个简单的对象池。
优化了这两条以后,不管是每帧分配内存,还是CPU耗时都降低了50%。而在所有的项目中,除了使用局部变量,其他优化中最显著的就是使用对象池了。因为正确地使用对象池能有效地减少创建新对象的过程,在Lua中也就是newindex这个函数的耗时明显减少。newindex减少了以后,不仅避免了频繁开辟回收内存,还能避免额外的CPU开销。尤其是使用对象池缓存一个经常复用的对象时,这样的优化更明显,比如说LuaVector3、GameObject、滚动列表中的对象。
三、字符串拼接使用table.concat
这个问题在很多优化Tips里经常提到,相信大家也不陌生。究其原因,是因为Lua的String是内部复用的,当我们创建字符串的时候,Lua首先会检查内部是否已经有相同的字符串了,如果有直接返回一个引用,如果没有才创建。这使得Lua中String的比较和赋值非常地快速,因为只要比较引用是否相等、或者直接赋值引用就可以了。而另一方面这个机制使得Lua在拼接字符串上开销比较大,因为在一些直接持有字符串buffer的语言中,往往可以直接把后者的buffer插入到前者的buffer的末尾,而Lua先要遍历查找是否有相同的字符串,然后会把后者整个拷贝然后拼接。
尽管是这样,我们还是有一些手段来优化Lua的字符串拼接,使用table.concat来代替。通过查看Lua的源码可以发现,这里的原理主要是table.concat只会创建一块buffer,然后在此拼接所有的字符串,实际上是在用table模拟buffer;而用“..”来连接则每次都会产生一串新的字符串,开辟一块新的buffer。这个问题在《Programming in Lua》一书也有提及:
local buff = ""
for line in io.lines() do
buff = buff .. line .. "\n"
end
-- 这段代码读取一个350kb大小文件的时候需要约1分钟,同时会移动(开辟后又被回收)50GB内存
这个问题确实真实出现过,我有一次发现的一个性能问题就是因为写聊天界面的同学,每次都会用旧的聊天字符串,拼接上新增的聊天字符串得到一串新的聊天字符串。以致于当聊天信息过猛的时候,只要几分钟内存就会爆炸。但是相比较前面两点,这个问题对内存的影响更大,对CPU耗时的影响比较小。
四、优化配置表
--如果polyline内有一百万个点,则下面的表结构会占用95kb内存
polyline = {
{x = 1, y = 2},
{x = 3, y = 4},
{x = 5, y = 6},
...
}
--这样优化可以减少到65kb
--只是我们不得不使用polyline[1][3]来代替比较直观的polyline[1].x了。
polyline = {
{1, 2},
{3, 4},
{5, 6},
...
}
--这样优化最终可以减少到24kb
--我们必须使用polyline.x[2]来代替polyline[2].x
polyline = {
x = {1, 3, 5 ... },
y = {2, 4, 6 ... }
}
对于我们RO来说,table配置表就占了几十兆的内存,每一点小的优化都能节省很多内存空间。通过平时定义配置表的谨慎小心,再配合之前UWA的这篇文章Lua配置表存储优化方案,能给项目带来非常可观的优化空间。
五、细枝末节
以下是一些比较小的优化,但确实出现过。所以列举出来供大家参考,另外如果想写出完美的Lua代码的话强烈建议读一下Roberto的原文。
1)使用闭包代替loadstring()
loadstring(string.format("return %d", i))
function oploadstring (k)
return function () return k end
end
loadstring总是会动态地编译传入的字符串,而这个操作是非常耗时的。有时候我们可以使用闭包的形式来达到一样的效果,而且开销更小。
2)使用pairs代替next
next总是从第一个非nil值开始遍历,直到找到一个非nil值,在删除一个表或者一个足够空的表时,很慢。使用next删除一个10万个元素的表时,耗时约为20秒。而使用pairs仅需要0.04秒。
3)不要在for循环中创建表和闭包
4) 重用coroutine
--lua中的coroutine本身是不支持重用机制的,但是我们可以使用一些小技巧来实现它。
co = coroutine.create(function (f)
while f do
f = coroutine.yield(f())
end
end)
5)用C实现一些功能
如果性能实在吃紧,但是有苦于不能使用LuaJIT,可以用C实现一些功能,这样可以使模块的性能可优化的空间大大增加。需要注意的是,使用C越多,则LuaJIT能优化的越少,这两者是不能叠加的。目前我们项目中并没有使用到C来实现一些模块,一来是纯用Lua性能并没有那么吃紧,二来是如果使用C来实现一些功能就失去了使用Lua的意义。反正都不能热更,那还不如直接用C#实现。只要小心一些,用Lua还是用C写不会是性能的瓶颈。
实际案例分析
广度搜索的Lua写法优化
通用的优化经验相信大家都有所了解,这里再给大家分享一段我自己写Lua代码的优化过程。这段代码是求解一个无向图中的最短路径问题。在一个773个顶点,812条边的无向图中,求任意一点到原点(一个特殊点,即local origin = 10000)的最短路径。这个无向图储存在一个table中,每个顶点有个全局ID作为key,children记录了该顶点的邻接点,示意如下:
graph = {
[ID] = { children = { ID1, ID2, ID3 } },
[ID1] = { ... },
[ID2] = { ... },
...
}
原始代码:
local origin = 10000
function Util.BFS(fpIdx)
local visited = {}
local Q = {}
local firstNode = BFSNode.new(nil, fpIdx)
Q[#Q + 1] = firstNode
visited[fpIdx] = firstNode
while #Q > 0 do
local node = Q[1]
table.remove(Q, 1)
local v = graph[node.ID]
for i=1, #v.children do
local id = v.children[i]
if id == origin then
local bfsNode = BFSNode.new(node, id)
bfsNode:Log()
return bfsNode:GetPath()
end
if not visited[id] then
local bfsNode = BFSNode.new(node, id)
visited[id] = bfsNode
Q[#Q + 1] = bfsNode
end
end
end
return nil
end
一、第一次优化
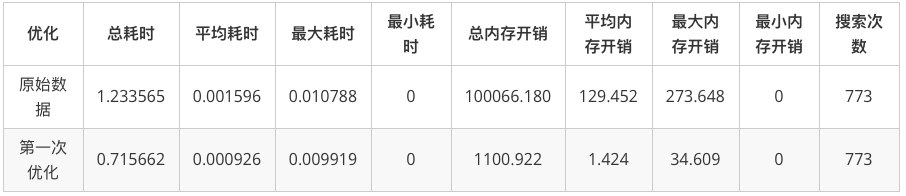
由于我自作聪明,为了提供Log和GetPath这些方法。将节点包装成了一个“BFSNode类”的形式,事实上是存在了一个table内。但是这部分的内存开销和CPU耗时都是非常大的,第一次优化主要就是将这个地方简化了。简化的代码应该是大家实现BFS算法的常用版本了,CPU耗时和内存开销都有所下降了。优化后性能数据如下:
local origin = 10000
local visited = {}
local queue = {}
local remove = table.removoe
local node
local id = 0
function Util.BFS(fpIdx)
visited = {}
queue = {}
queue[#queue + 1] = fpIdx
visited[fpIdx] = -1
while #queue > 0 do
node = remove(queue, 1)
local v = graph[node]
for i=1, #v.children do
id = v.children[i]
if id == origin then
return Util.GetPath(visited, id, node)
end
if not visited[id] then
visited[id] = node
Q[#Q + 1] = id
end
end
end
return nil
end
function Util.GetPath(visited, targetIdx, parentIdx)
local path = { targetIdx }
while parentIdx > 0 do
path[#path + 1] = parentIdx
parentIdx = visited[parentIdx]
end
return path
end
二、第二次优化
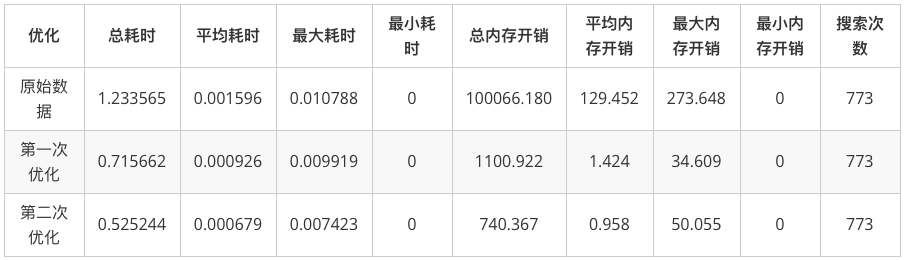
第一次优化后,CPU平均耗时1ms,平均内存开销1.4KB都处于可接受的范围了,但是这个代码还是有优化空间的。因为上面代码中visited没有得到复用,我们可以用一段简单的代码复用visited。这次优化做到了773次寻路总内存开销在740KB,visited和Q的开销约为50KB,其余的约700KB内存全部用于构造Path数组,此外没有内存浪费了。如果还需要优化的话就比较难了,不是一些简单的代码能实现的。而对于我们实际应用中,优化到这种程度已经完全够用了。优化后的代码和数据如下:
local noneIdx = 0
local invaildIdx = -1
local origin = 10000
local node
local id = 0
local g = graph
local GetPath = Util.GetPath
local ReuseTable = Util.ReuseTable
local head = 0
local last = 1
function Util.BFS(fpIdx)
head = 0
last = 1
Q[last] = fpIdx
visited[fpIdx] = noneIdx
while last > head do
head = head + 1
node = Q[head]
local v = g[node]
for i=1, #v.children do
id = v.children[i]
if id == origin then
local path = GetPath(visited, id, node)
ReuseTable(visited)
return path
end
if not visited[id] or visited[id] == invaildIdx then
visited[id] = node
last = last + 1
Q[last] = id
end
end
end
ReuseTable(visited)
return nil
end
function Util.GetPath(visited, targetIdx, parentIdx)
local path = { targetIdx }
while parentIdx > 0 do
path[#path + 1] = parentIdx
parentIdx = visited[parentIdx]
end
return path
end
function Util.ReuseTable(t)
for k,_ in pairs(t) do
t[k] = invaildIdx
end
end
三、了解SLua和C#交互
上面的优化示例局限于Lua的写法和用法层面,虽然这是项目中常见的一类优化点,但是我们的Unity项目中,Lua优化还有另一个大头——Lua和C#交互。而要优化这部分,就先要明白Lua和C#交互时发生了什么。因为笔者用的是SLua,所以这里分析Lua和C#交互就以SLua为例了。其中obj为Lua持有的一个C#的GameObject对象,当我们执行以下代码的时候,就产生了两次Lua和C#交互。
local pos = obj.transform.position
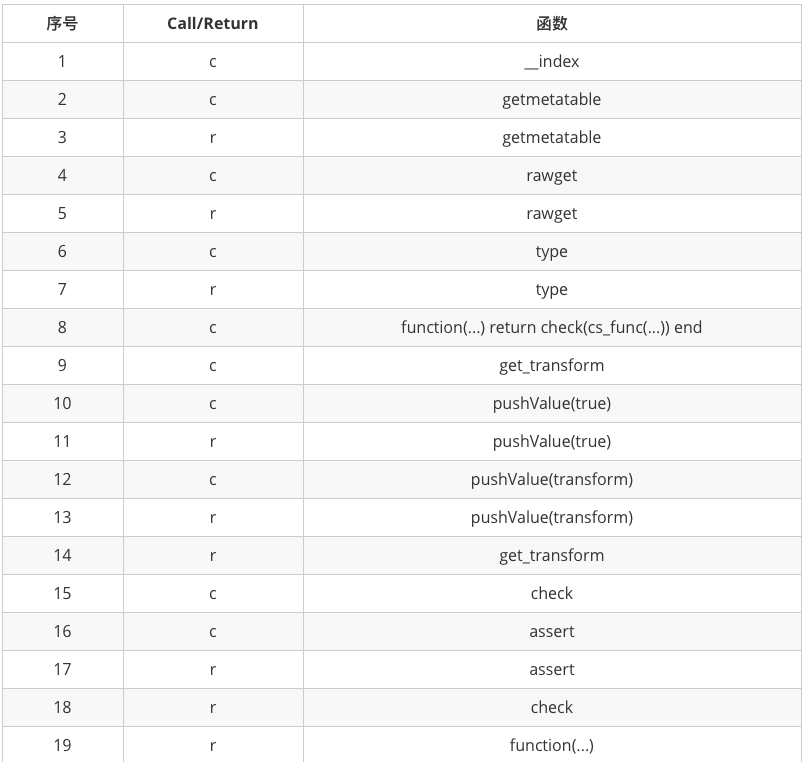
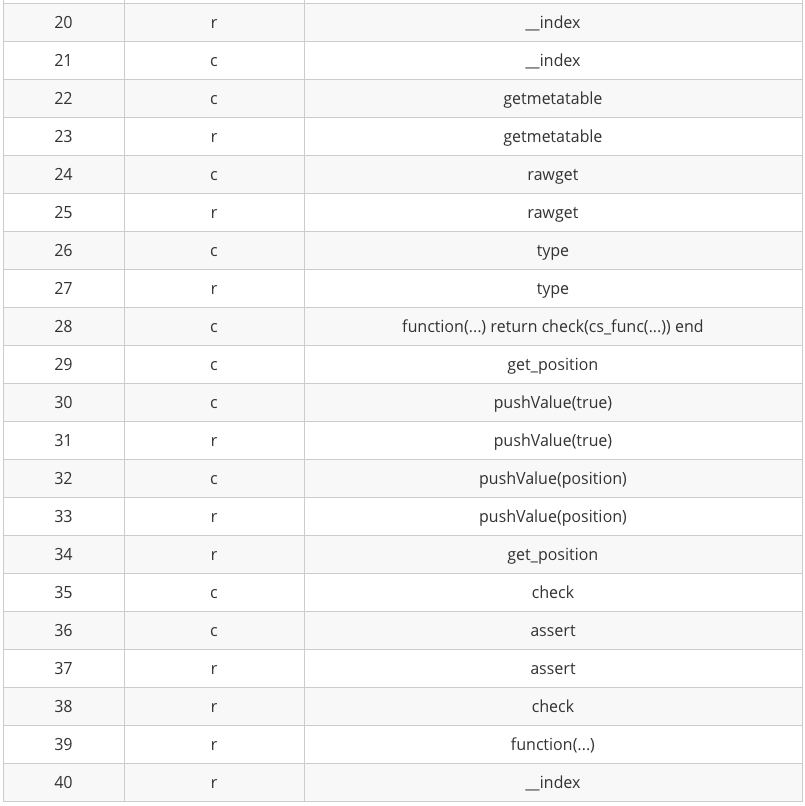
这次Lua和C#交互的过程中,全部的流程如上表。简述一下流程就是:
1)取得元表中存储的C#函数指针
2)调用C#函数
3)返回结果
以我的经验来说,LuaCPU性能往往是和内存的开辟密不可分的。所以我们关注的重点在第三步,怎么返回结果的。SLua有一个缓存机制,已经返回过的对象会缓存在一个Map中,并且有一个唯一的索引作为Key。返回的对象会先在C#的Map中查找,如果找到了则返回这个索引。然后用这个索引去Lua的Table中查找对应的值,这个值就是最后返回给Lua的值。这个值是一个Table,其中的元表包含了所有导出的C#函数。而值类型,因为它性质的特殊,每次返回都会新生成一个索引。也就是C#里多缓存一次,Lua里多缓存一个Table。所以从Lua中访问C#中的值类型时,要注意Lua内存的开销。除去常见的Vector2/3/4、Quaternion、Color等常用的值类型做了特殊处理,不经过缓存,其他的值类型都要注意这一点。
不仅是取值,还有设值的时候也要非常小心,上面提到的我们隔壁项目组遇到的问题就类似下面这行代码,在每帧调用的Update里创建LuaVector3。因为调用这个函数的时候,C#中取LuaVector3是分别取的这个Table下标为1\2\3的三个值包装为C#的Vector3,然后设给position。所以当设完值以后这个LuaVector3由于没有任何人引用(虽然看起来是复制给了一个对象),就会被回收掉,每一帧都会新建一个Table然后回收一个Table。
function Test:Update()
obj.transform.position = LuaVector3.New(0, 0, 0)
end
这是侑虎科技第299篇原创文章,感谢作者舒航供稿,欢迎转发分享,未经作者授权请勿转载。当然,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!