
GPU Skinning 加速骨骼动画
- 作者:admin
- /
- 时间:2017年04月02日
- /
- 浏览:32897 次
- /
- 分类:厚积薄发
场景中有很多人物动画模型的时候,性能会产生大量开销,其中很大一部分来自于骨骼动画。此文推荐的方法是将CPU中的蒙皮工作转移到GPU中进行,从而能够较大地提升多角色场景的运行效率,在大规模群体动画模拟如MMO、RTS等游戏中有较大的应用性。
一、起因
我们知道,场景中有很多人物动画模型的时候,性能会产生大量开销。这些开销除了 Draw Call 外,很大一部分来自于骨骼动画。Unity 内置了 GPU Skinning 功能,但笔者测试下来并没有对整体性能有任何提升,反而增加了不少。有很多种方法来减小骨骼动画的开销,每一种方法都有其利弊,都不是万金油,这里介绍的方法同样如此。其实本质还是由我们自己来实现 GPU Skinning,只是和 Unity 内置的 GPU Skinning 有所区别。


使用了 ShadowGun中的角色模型

开启 Unity 内置的 GPU Skinning
从上图中可以看到,Unity 调用到了OpenGL ES 的 Transform Feedback 接口,这个接口至少要在 OpenGL ES 3.0 中才有。笔者理解的 Transform Feedback,就是将大批的数据传递给 Vertex Shader,将 GPU 计算过后的结果通过一个 Buffer Object 返回到 CPU 中,CPU 再从 Buffer Object 读取数据(或直接将 Buffer Object 传递给下一步),在随后步骤中使用。显然,在骨骼动画中,TransformFeedback 负责骨骼变换,Unity 将变换后的结果拿来再进行 GPU 蒙皮操作。
这次我们要动手实现的就是这个过程,但是不使用 Transform Feedback,因为要保证在 OpenGL ES 2.0 上也能良好运行,况且Unity引擎也没有提供这么底层的接口。
大致的步骤如下:
- 将骨骼动画数据序列化到自定义的数据结构中。这么做是因为这样能完全摆脱 Animation 的束缚,并且可以做到 Optimize
GameObjects(Unity 中一个功能,在不丢失绑点的情况下将骨骼的层级结构 GameObjects 完全去掉,减少开销); - 在 CPU 中进行骨骼变换;
- 将骨骼变换的结果传递给 GPU,进行蒙皮。
很简单的三大步骤,对于传统的骨骼动画来说没有任何特殊情况,下面我会对其中的每一步展开说明,并将其中的细节描述清楚。
二、实现
提取骨骼动画数据
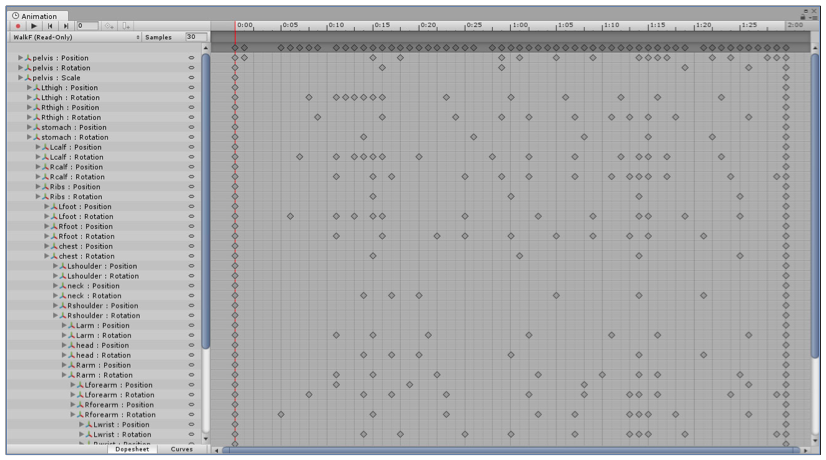
Unity 中的 Animation 数据
这个步骤的目的就是将这些数据提取出来,存储到自定义的数据结构中。代码大致如下:
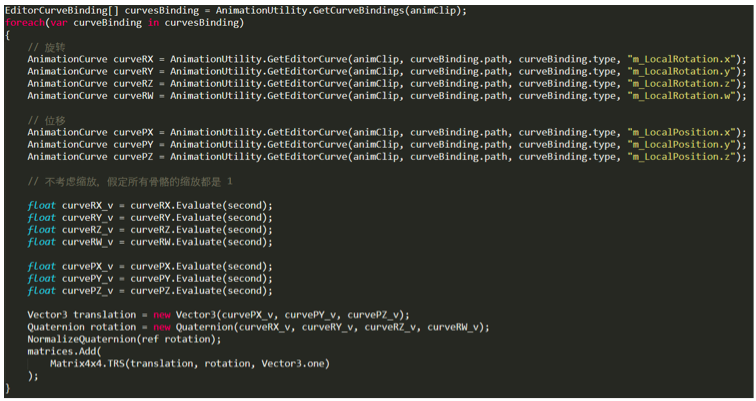
其中有两个注意点。第一,要清楚 AnimationCurve 中提取出来的旋转量是欧拉角还是四元数。这里我一开始就弄错了,想当然认为是欧拉角,所以随后计算得到的结果也就错了。第二,用来旋转的四元数,必须是单位四元数(模是1),否则你会得到 Unity 的一个报错信息。
以上的代码中,我将每一帧的数据以 30fps 的频率直接采样了出来,其实也可以不采样出来,而是等需要的时候再从 AnimationCurve 中采样,这样会更平滑但是运行时的计算量也更多了。
骨骼变换
骨骼变换是所有代码的核心部分了,看似挺复杂,其实想清楚后代码量是最少的:
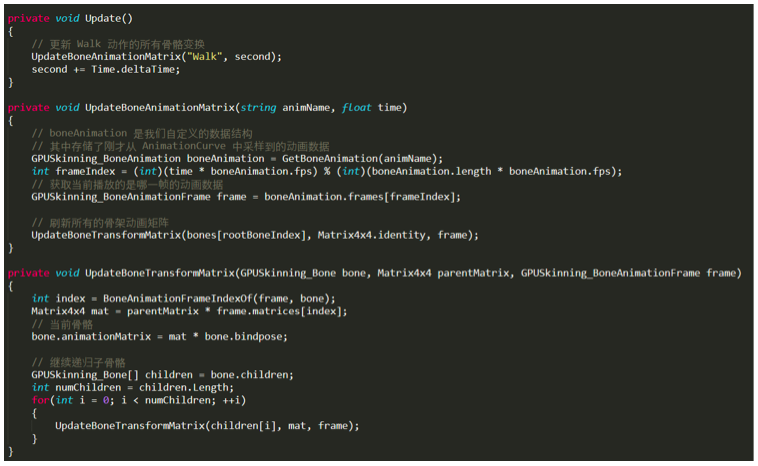
简单来说骨骼变换就是一个矩阵乘法,比如 bone0(简写为b0) 是 bone1(简写为b1)的父骨骼:

注意这里是矩阵左乘(从右往左读),trs 是 Matrix4x4.TRS,也就是从 AnimationCurve 采样到的数据。
Bindpose 的作用是将模型空间中的顶点坐标变换到骨骼空间中(是骨骼矩阵的逆矩阵),然后应用当前骨骼的变换,沿着层级关系一层层地变换下去。
蒙皮
蒙皮CPU部分的代码如下:
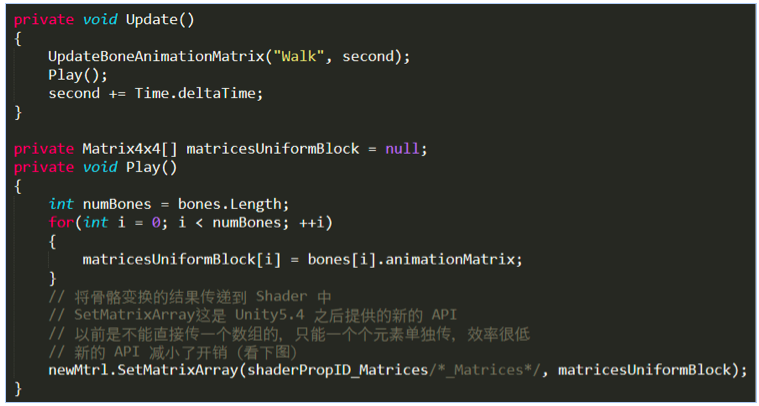


由于骨骼数量固定为 24,所以图中的 96 = 24 x 4
使用 SetMatrixArray 其实有点浪费了,因为对于一个 4x4 的矩阵(四个 float4 )来说,最后一维永远是 (0, 0, 0, 1),所以可以使用 3x4 的矩阵(三个float4)代替,这样就减少了数据传递的压力。
现在所有的骨骼变换矩阵已经传递到 Shader 中了,就可以使用这些数据来进行蒙皮(变换顶点坐标)。
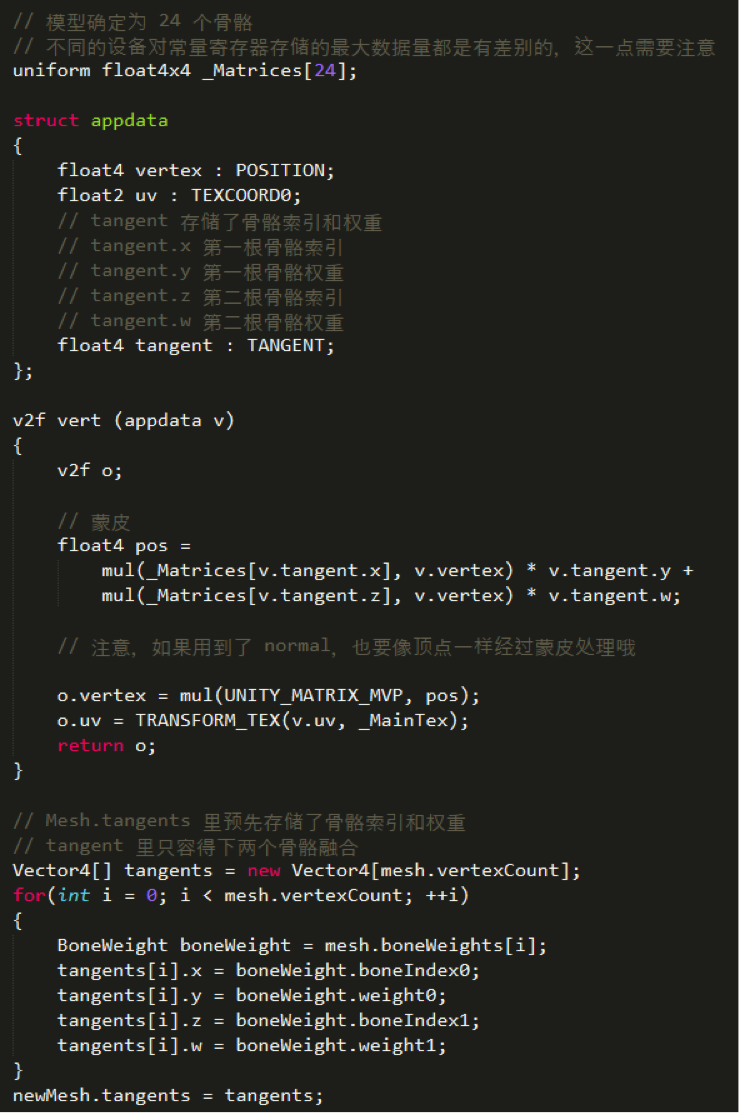
三、改进
此时所有角色的动作都是同步的。接下来进行改进,不再使用 uniform array 的方式来传递数据,而是将骨骼动画数据存储到纹理中,并加以一定的差异化,避免所有角色的动作完全同步的问题。在运行的最开始,将所有帧的动画数据存储到纹理中,代码如下:
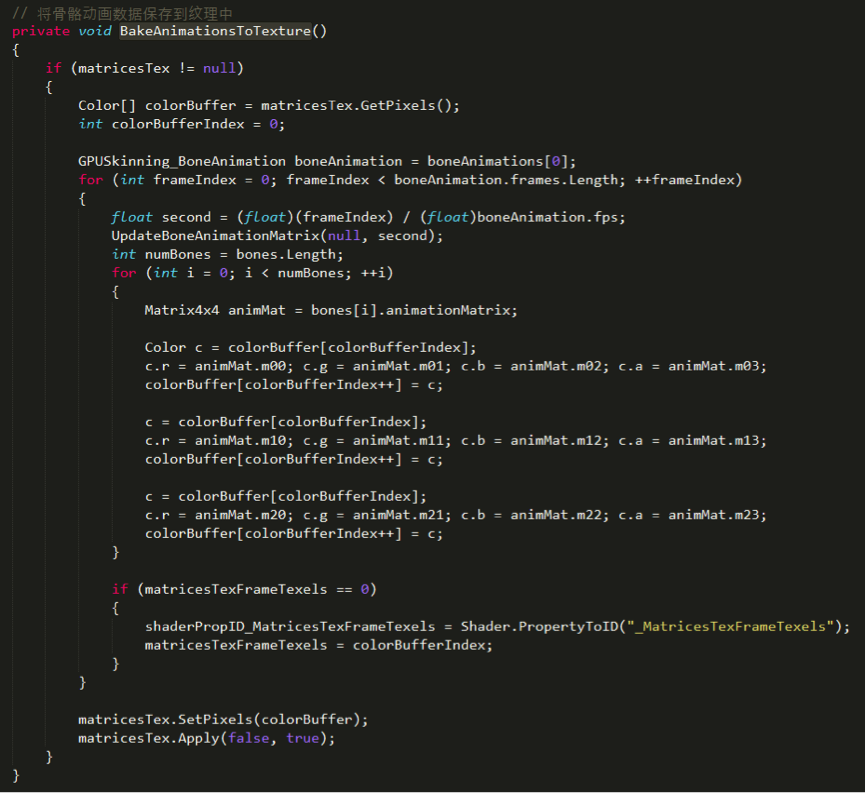
Shader中的蒙皮代码相应变为:
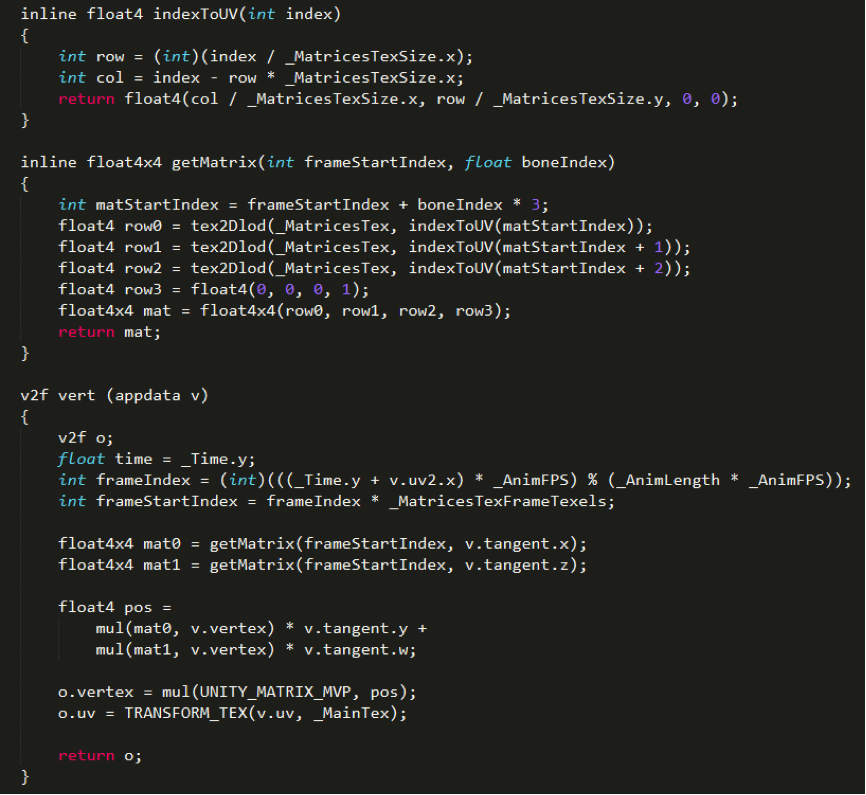
以上就是笔者实现 GPU Skinning 的细节。但没有一种方法是完美的,作为能够减少骨骼动画开销的备选方案之一,在恰当的情况下使用会大大地提高性能。
四、测试
为了进一步验证该方案在移动设备上的可行性,UWA在真机上进行如下了实验。
我们在一个空场景中放置一定数目的模型播放动画,对 Mecanim 和 GPU Skinning 的运行效率进行对比。模型取自 ShadowGun,具有2600面片,24根骨骼。使用 Mecanim 时,模型使用 Generic 模式,并且使用 Optimize GameObject。在红米Note2运行1000帧的数据如下:
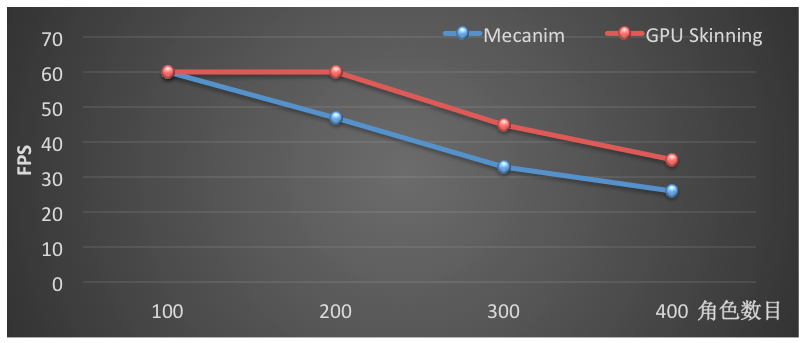
FPS 变化
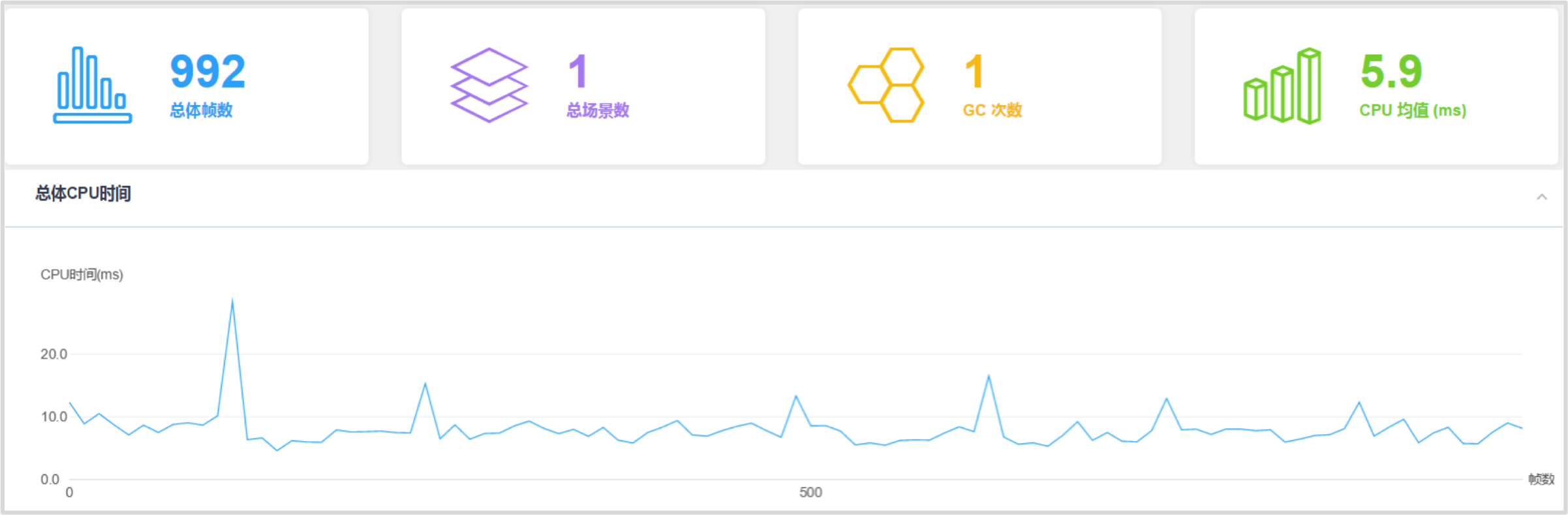
测试场景 CPU 耗时数据
上图是GPU Skinning方案在场景中存在300个角色时的主线程 CPU 耗时数据。不同角色数目的平均每帧 CPU 耗时(主线程)如下:
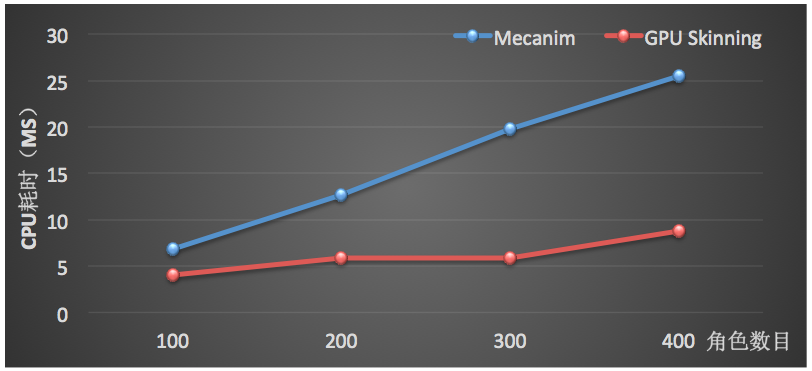
从数据可以看出,不论从整体的 FPS还是主线程平均每帧的 CPU 耗时,GPU Skinning都表现出了更好的性能,从而可以让宝贵的 CPU 耗时用于更多的游戏逻辑。
五、优点和局限性
该方法将CPU中的蒙皮工作转移到 GPU 中进行,真机上的测试数据验证了该方法能够较大地提升多角色场景的运行效率。该方法具备以下优点:
- 极大地降低 MeshSkinning.Render 的CPU耗时,同时还可以去除对 Animator 组件的依赖,从而完全避免 MeshSkinning.Update 和 Animator.Update 的 CPU 占用;
- 通过纹理保存动画数据,只需要少量内存开销即可带来巨大运行效率提升;
- 适用于大规模群体动画模拟,如 MMO、RTS 等游戏类型。
当然,该方法在当前也存在如下局限性:
- 增加 GPU 运算负担;
- 当前的 Shader 实现中使用了 tex2Dlod,该 API 在某些低端机型上可能存在适配问题;
- 目前还无法直接处理动画事件、动画融合等操作,需要研发团队进行进一步开发。
这是侑虎科技第222篇原创文章,感谢作者程可汗供稿提供了优化思路以及相关案例。同时,UWA根据作者提供的案例在不同的移动设备上进行测试和对比,并总结成此文,希望对使用骨骼动画的朋友有所借鉴。当然,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
相关Github:https://github.com/chengkehan/GPUSkinning ,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!




和MeshBaker这个插件生成的顶点动画比起来效率怎样?
GPU蒙皮是否意味着对骨骼数量有限制?
该方法没有。