
对于字体裁剪生僻字的做法
- 作者:admin
- /
- 时间:2023年02月14日
- /
- 浏览:4067 次
- /
- 分类:厚积薄发
1)对于字体裁剪生僻字的做法
2)协程中yield return CoFunction()和yield return StartCoroutine(CoFunction())的区别
3)Unity切换场景时对技能特效首次释放卡顿
4)《SLG手游的制作与优化》中Shadowmap优化的疑问
这是第324篇UWA技术知识分享的推送,精选了UWA社区的热门话题,涵盖了UWA问答、社区帖子等技术知识点,助力大家更全面地掌握和学习。
UWA社区主页:answer.uwa4d.com
UWA QQ群:465082844
Font
Q:我们项目中使用的中文字体TTF文件大于10MB,于是采用了通用的裁剪生僻字的做法,把字体中低频使用的字形数据删掉了,但是项目又有取名相关的需求,并且在玩家取名完成后无论是大厅主界面还是战斗界面都有显示玩家名字的需求,那么在这种情况下有什么方法既能兼容玩家取名一些被裁剪掉的生僻字,又能够有效降低字体TTF Asset内存的做法呢?
我的意思并不是指降低字体图集的大小,而是降低原字体TTF文件的大小。
A:我有个思路题主可以考虑试一下:
首先是一个前提,就是TMP图集的内存优化做法:是我参考了UWA DAY 2022中的议题《Unity移动游戏性能优化案例分析》结尾左右的一个分享。简单来说,就是在游戏项目中使用TMP方案时,很多时候内存中会用到一张4096x4096分辨率的Alpha格式的动态图集纹理,内存占用高达32MB。优化方式就是将常用字符构建为4096x4096的一张静态图集,并通过代码替换纹理、设置压缩格式(如ASTC8x8),则内存降至仅4MB。此时再使用一张512x512的动态图集作为它的Fallback,就能处理生僻字需求了。
基于上述的做法,我们还知道TMP中打静态图集后是可以解除对TTF文件的引用的,没有引用,也就不用打进包体、加载进内存;但问题在于,那张小的、用来处理生僻字的动态图集还是要引用TTF才能在运行时生成。那么,我们就可以考虑反向裁剪,也就是只把TTF里的已经打进静态图集里的常用字裁剪掉而保留生僻字,再把这个处理过的TTF资源作为那张动态图集的引用对象。
通过上面这一系列操作,字体图集纹理和TTF文件的内存占用应该都降低了,同时理论上能达成题主的功能需求。
感谢Faust@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/63e30f3b0638540599016732
Script
Q:请问协程中yield return CoFunction()和yield return StartCoroutine(CoFunction())有什么区别?
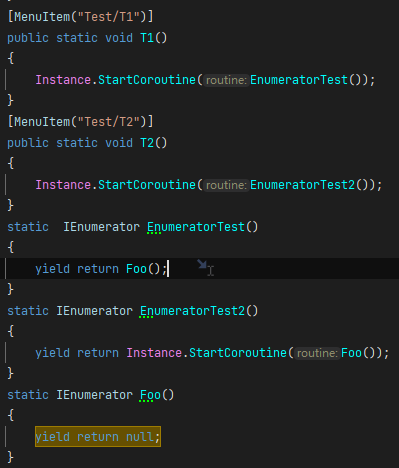
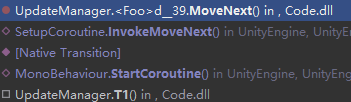
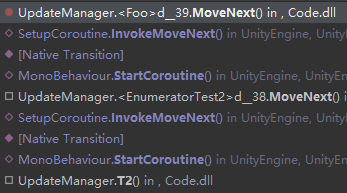
针对以上问题,有经验的朋友欢迎转至社区交流分享:
https://answer.uwa4d.com/question/63e9f86606385405990775cd
Performance
Q:在切换场景时对技能特效用缓存池提前做了缓存,进入场景后首次释放依然卡顿,这是为什么呢?
A1:首次特效释放的卡顿往往与Shader编译有关系,可以尝试收集Shader变种并提前Warmup一下。
感谢该用户匿名@UWA问答社区提供了回答
A2:比较全面的预加载应该模拟真实环境下的播放流程,因此可以在切场景Loading期间,创建一个临时Camera,随后将需要预加载的资源全部在Camera前面播放一下,并调用Camera.Render:
- 对于特效Prefab,在对象池里实例化,并在Camera视野里实例化并播放一帧,同时调用Camera.Render强制渲染,再回收到对象池。
- 对于Animator和Animation,Animator.Update(1.0)调用Animation.Sample模拟播放一遍,如果有动画事件,确保动画事件关联的特效和声音也在预加载列表里。
- 对于AudioClip,调用PlayOneShot并静音。
- 其他资源按需处理。
按以上步骤处理后,下次在真实场景播放时,不会再有任何耗时的逻辑步骤,一般不会再出现卡顿了。
感谢流浪猫咪2@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/63db58f10638540599fa494c
Shadow
Q:对于UWA DAY 2022系列课程中《SLG手游的制作与优化》的疑问:
Shadowmap改进里说可以在生成和接受时把WorldToLightMatrix的计算去掉,这个是怎么做到的?就算不转到光空间也得转到其他空间,怎么都得有矩阵运算得出shadowCoord,而且矩阵乘法是几个MAD,即使顶点很多,vs里跟其他方式比会有很大差异?
A:首先,顶点的投影点是在水平面上的,顶点和投影点的相对关系是比较稳定的,在WorldSpace是这样,在CameraSpace中也是如此。
其次,改进算法中的投影点的偏移计算是发生在CameraSpace中的,所以:
- 顶点本身MVP计算,是会计算到ViewSpace也就是CameraSpace下的viewPos;
- 光线方向V,在CameraSpace下,是可以提前算一遍的,CPU一帧算一次就好;
- 顶点到投影点的距离是很容易通过相似三角形算出来的,而且这个比值是固定的,其实就是光线和地平面夹角A的,1/sinA;而A也是可以提前就知道的,CPU一帧计算一次就好;
- 知道偏移长度和方向V,是很容易算出偏移的,那么也就很容易算出在ViewSpace下的投影点的位置;
- 到这里,看起来很多步骤(主要是思考过程),其实就是一个MAD的事情;
- 我只想知道投影点的UV(即Shadowmap的ShadowCoord),所以Projection的过程其实就是一个MAD的事情;
- 根据相似三角形的成像原理,Shadowmap中写入的是顶点在地平面上的Y值;
- 到现在为止VS过程中,一共只用了两个MAD,而一个矩阵运算是四个MAD(不同写法指令不一样)。
再次,生成和接收都需要经过这样的计算。
最后,从PPT中最后的性能对比来看,性能的提升是有的,相差也不算很大,低端机上表现更为明显一点,有1.5ms左右的差距,高端机上差距并不算显著。
它带来对Shadowmap利用率的提高,而导致使用更低Shadowmap Size达到相同的效果,对于高配机器来说,收益可能更大一点。
感谢Jessica@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/63e45ef20638540599029115
封面图来源于《SLG手游的制作与优化》课程
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:465082844



