
技术分享连载(五十九)
- 作者:admin
- /
- 时间:2017年04月11日
- /
- 浏览:8270 次
- /
- 分类:厚积薄发
本期我们聚集了这些话题:AssetBundle粒度规划、Android上的多线程渲染、Instantiate实例化堆内存占用、动画模块中函数的CPU占用...
我们将从日常技术交流中精选若干个开发相关的问题,建议阅读时间15分钟,认真读完必有收获。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。
UWA QQ群:793972859
UWA 问答社区:answer.uwa4d.com
资源管理
Q1:关于AssetBundle(下称“AB”)拆分粒度问题。在我的项目中,我是基于逻辑以及最终的打包大小来分的,比如尽量不让压缩后的AB包超过1MB, 这是UWA之前的推荐,同时也是因为当前版本Android包的SerializedFile占用大小所考虑。经过这样的规划之后,我打包这块的代码基本是写死的, 包括手动把公共包拆成多个(公共包略大,不拆的话压缩后会有6、7MB), 还有每个AB包的内容也是人为拆成多个。 这样虽然最后功能实现了,但个人依旧觉得不够自动化。每次新添加资源的时候, 都得走一遍这种手动流程。也研究了别人写的开源方案 ,全自动分析依赖关系,但问题是最后包打得实在太细了,不太符合科学(但还是推荐大家学习)。所以就想问下各位的公司项目是如何解决这个AB 粒度划分问题的?
这是一个相当开放的问题,仁者见仁,智者见智。UWA目前无法总结出一个大一统的方式来建议如何进行打包,首先需要说明我们看到的两点情况:
(1)没有最好的打包方式,只有最适合项目需求的打包方式;
(2)无论是粗粒度打包还是细粒度打包,现在都有成功的项目在采用,这说明只要符合需求,两种打包方式都是很好的。
接下来,我们就粒度问题给出一些我们的看法:
1. AB粒度建议不宜过细,特别是一个资源一个AB。
粒度过细,一方面会导致加载IO次数过多,从而增大了硬件设备耗能和发热的压力;另一方面,在我们测试过的Unity 5.3 ~ 5.5 版本中,Android平台上在不Unload的情况下,每个AB的加载,其每个文件的SerializedFile内存占用均为512KB(远高于其他平台),所以当内存中贮存了大量AB时,其SerializedFile的内存占用将会非常巨大。同时,需要进一步说明的是,该问题已在Unity5.6中进行完善。2. 在Unity 5.3版本之后,对于AB文件的文件大小其实不必再限定于1MB之内。
之前UWA有这一限定是出于两方面的考虑:一是New WWW在Unity 5.3之前是使用最为频繁的AB加载方式(虽然现在也是),在5.3版本之前,New WWW加载会形成一个比较大的WebStream,一般来说是压缩AB的4~5倍,会占用比较高的内存;另一方面,当AB较大(比如大于5MB)时,其加载开销会很大,由于是子线程中运行,所以真正反映到Profiler中时,大家会看到的一个“诡异”的CPU高开销——Graphics.PresentAndSync,具体原因可以看这里( 扒一扒Profiler中这几个“占坑鬼” )。所以,我们对此做了一些实验,发现将AB压在1MB以下是一个加载比较可以接受的情况。以上是我们之前为什么会提出1MB的主要原因。但Unity5.3之后,随着LZ4的引入,很多情况已经变化了,基于其Chunk的加载特点,AB加载很快,且内存占用要比之前小很多。所以LZ4的AB其实可以考虑更加粗粒度一些。但是,这里仍然有以下三点注意:
1. 对于需要热更新的AB,也如问答中其他朋友的所言,要考虑实际情况控制AB的大小;
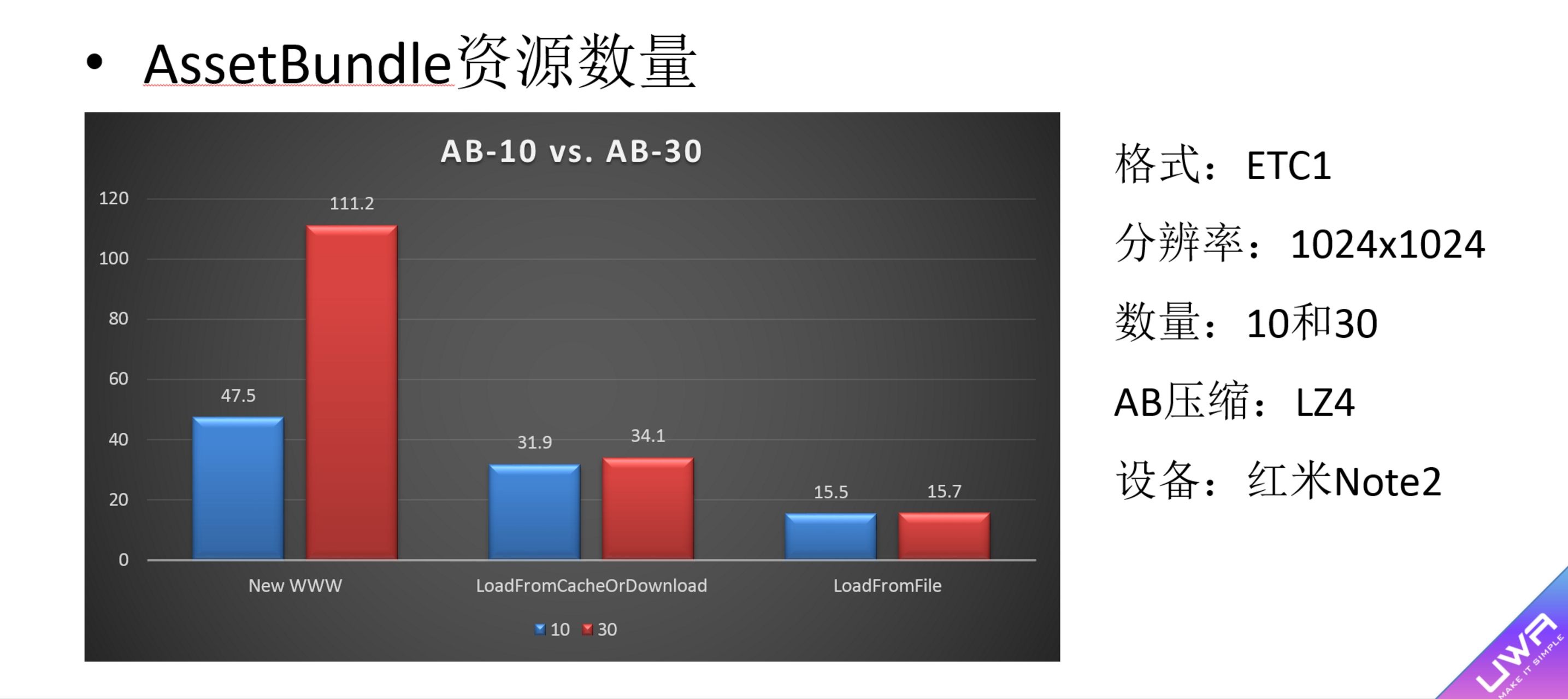
2. 即便是LZ4的AB,其加载方式不同,加载效率也可能完全不一致。以下是我们在UWA DAY 2017的分享,我们在两个不同的AB(LZ4格式)中都加载同一个资源,唯一不同的是一个AB包含10个Asset,而另一个AB包含30个资源,以下是三种不同方式从加载AB到AB.Load的耗时对比。可以看出,New WWW加载出现了明显的时间差异。因此,在Unity5.3之后,尽可能建议通过LoadFromFile(Async)来对AB进行加载。
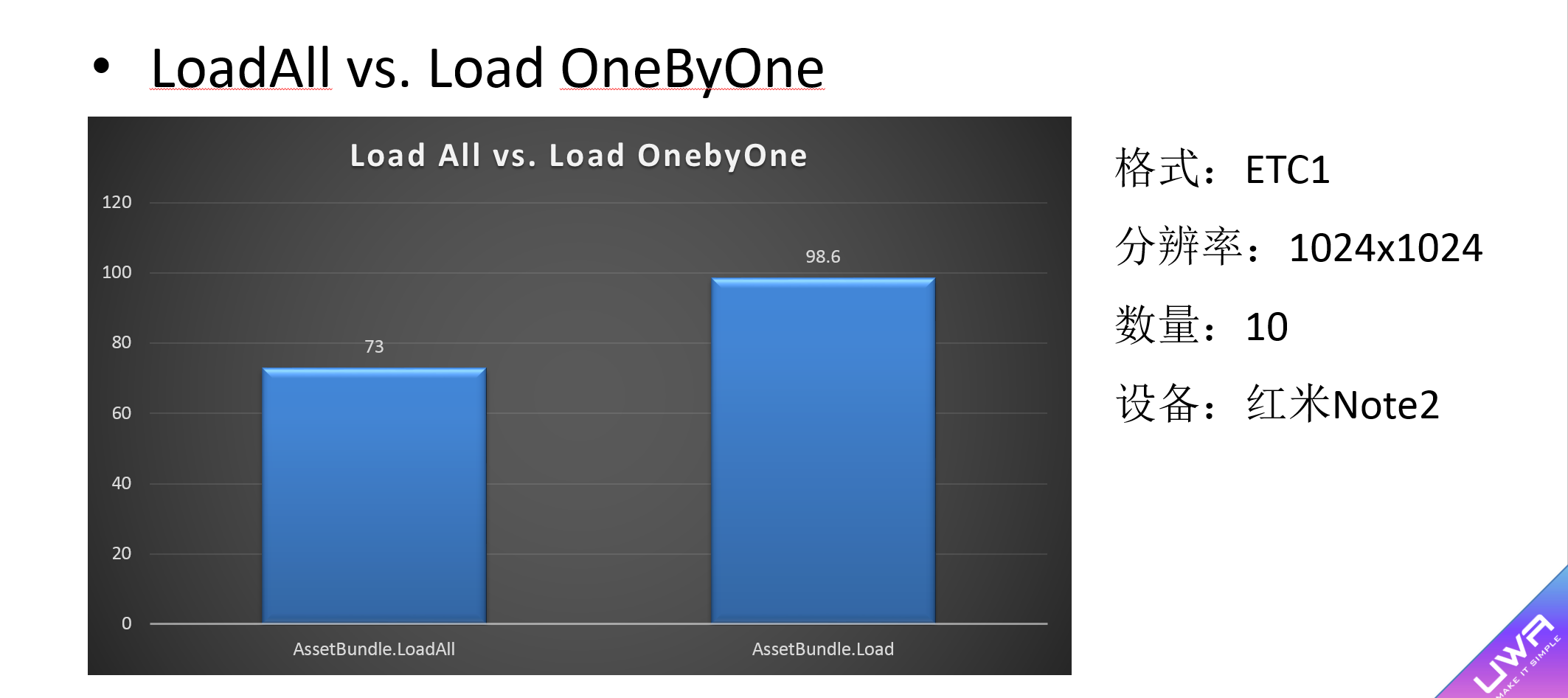
3. 对于AB的打包,尽可能把逻辑上同时出现(一个Prefab中非Share的Asset)、小而细碎的资源(Shader、Material、粒子系统等)尽可能打包在一起,并通过LoadAll来进行加载,因为这样会带来更好的加载效率。下图为LoadAll和Load One By One的性能对比。在我们做过的实验中,LoadAll确实会带来更好的性能开销。
上述是我们建议研发团队在AB打包时的一些注意点,希望对大家的项目优化有所帮助。
此问答来自于UWA 问答社区:
https://answer.uwa4d.com/question/58e5bd96e042a5c92c3484ec/AssetBundle-%E7%B2%92%E5%BA%A6%E8%A7%84%E5%88%92
如您对该问题仍有疑问,可以转至社区进行进一步交流。
性能优化
Q2:我之前在参加UWA讲座时,听说移动端开启多线程,把后期效果移动到渲染线程会节省后期的消耗。我测试了一下,虽然主线程中后期显示的CPU占用降低了,但是却多了Gfx.WaitForPresent的时间,最后两者相加基本还是一样的。那开启多线程这个功能,对后期到底有没有帮助呢?

我们在UWA Day上详细讨论了多线程渲染的开销。需要注意的是,开启多线程渲染一般情况下会极大降低主线程的渲染耗时,但并不会降低其本身的总体计算量。因为这并不是底层算法或硬件上的提升,而是将部分计算从主线程搬到了子线程。所以,开启多线程的好处在于为主线程带来了大量空间来执行其他耗时模块(如代码逻辑等)。但这并不意味着开启多线程渲染就“万事大吉”。如果渲染模块本身开销就很高,那么子线程一样会很耗时,更有可能出现主线程等待子线程的现象,也就是WaitForPresent开销较高的情况。所以,开启多线程是会降低主线程的渲染压力,但其帧率未必会大幅提升,还需研发团队自行在自己项目中进行尝试和比较。
Instantiate实例化
Q3:为什么Unity里实例化一个Prefab会产生那么多GC Allocated?

图中的Instantiate实例化操作应该是实例化一个较为复杂的UI界面,其中还通过Active/Deactive激活和关闭部分UI界面。Instantiate实例化会触发Object上挂载脚本的构造函数(..ctor操作)和Awake操作,而这些函数中的堆内存分配均被计算在Instantiate实例化操作中;同时,UI界面的Active和Deactive也会造成UI代码底层的一些相关OnEnable和OnDisable操作,同样会造成一定的堆内存分配。而上图中之所以堆内存分配量较高,是因为Instantiate和Active的调用次数较多,分别为93次和183次。因此,图中堆内存分配过高并不是实例化一个Prefab所致,是同一帧中实例化和Active了大量UI Prefab所致。建议研发团队对项目运行时的UI实例化频率进行进一步检测。
动画模块
Q4:请问动画模块中,Animators.ProcessAnimationsJob和Animators.WriteJob的CPU占用较高,请问这些与什么因素有关?

Animators.WriteJob受模型骨骼数目影响较大(受animation curves影响不明显),骨骼数目越多,该函数耗时越大。同时,开启Optimize GameObject选项能够降低该函数耗时。Animators.ProcessAnimationsJob 同样受骨骼数目影响较大,同时也受animation curves数目影响,二者数目越多,该函数耗时越大。
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站(answer.uwa4d.com)上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
官方技术QQ群:793972859(非水群,仅限技术交流)



