
Unity手游实战:浅谈CPU缓存命中和Unity面向数据技术栈(DOTS)
- 作者:admin
- /
- 时间:2019年09月18日
- /
- 浏览:7996 次
- /
- 分类:厚积薄发
本文主要围绕浅谈CPU缓存命中和Unity面向数据技术栈(DOTS)进行讲解。本系列前四章相关内容之前已经推送,ECS设计思想和Entitas插件戳此回顾,逻辑与表现分离以及实战ECS架构和优化戳此回顾,本文由第五章开始。
五、浅谈CPU缓存命中
ECS在游戏里的运用,最初是用来解决预测和回放问题的。但是由于面向数据的编程结构,天然符合了现代CPU的编程思想,所以目前Unity ECS主要还是推动展现性能方面的优势。那么ECS是如何提升程序性能的呢?最重要的其实就是CPU的缓存命中。讲CPU命中之前,我们先说说CPU的一些基础知识。
1、CPU架构
我们现在经常听到的关于CPU的描述里会有高通骁龙,华为麒麟,英特尔奔腾,酷睿I3、I5、I7或者X86,ARM,PowerPC,又或者32位、64位等等。那么它们之间的关系是什么?
首先,我们说区别CPU最核心的指令集,指令集决定CPU的工作方式,所以指令集就决定了一个CPU的架构。CPU发展到现在,衍生了很多不同的架构方式,到目前为止,接触最多的就是X86和ARM架构。
X86是复杂指令集(CISC)的代表,ARM是精简指令集(RISC)的代表,这二者之间最核心的区别就在于指令的复杂程度,指令的复杂程度又决定了硬件的设计工艺和工作时的调度方式。
比如,我们把大象放进冰箱,一共需要三步:第一步把冰箱门打开,第二步把大象放进去,第三步把冰箱门关上。X86(复杂指令集)推崇的就是分成三步执行,当我想把长颈鹿也放进去的时候,我只要替换第二步就可以了。但是ARM推崇的是,我要训练一个机器人(硬件加速),告诉它怎么把大象放进去,我以后就只要对它说:“把大象放冰箱”,就能完成工作。这两种方式有什么优劣呢?
首先,复杂指令集在面对多种相似或者相近的需求时,只要更换部分的执行顺序就能完成工作,但前提是需要消耗额外的时钟周期,如果是一个任务还好,想想现在软件的复杂程度,那多出的执行周期不是一点两点。ARM的方式虽然更优,但是灵活度不足,当遇到没有训练过的部分还是需要走基础步骤去解决。
除了从复杂程度上来说,二者还有哪些区别呢?
首先,X86帮助Intel坐稳了CPU产业龙头的位置,直到现在仍然是无可替代的架构。它穿插在各种PC、家用机、服务器中,占据现在主流台式设备的核心位置。但是当移动领域开启之后,它仍然试图用同一套架构方式硬塞进手持设备中,这就导致了ARM这种从设计之初就面向性能的架构得到了发挥的余地。要知道一个ARM在峰值的时候功耗也就在3W左右,是I7的十五分之一。越低的功耗意味着在移动设备上电量支撑的越久,这是智能移动设备初期非常大的优势所在。
而Intel要在功耗上追上ARM,就需要在工艺上精进,所以一个28nm制造工艺的ARM架构,X86就要优化到22nm才能追赶上(麒麟处理器是7nm)。工艺的精进成本很高,7nm已经是2019的极限。我们知道制作集成电路都是需要在晶圆表面操作的,光刻机意味着是使用光来雕刻晶圆,光又是有波长的,波长越大越容易发生衍射(这也是5G信号不好的原因,5G技术最大的难点就是解决信号覆盖。5G快是因为波长短,携带的信息更多,但是不容易衍射过障碍物),所以要光刻,必须挑选指定的光源。
常见光源分为:
可见光,g线:436nm
紫外光(UV),i线:365nm
深紫外光(DUV),KrF 准分子激光:248nm,ArF 准分子激光:193nm
极紫外光(EUV),10~15nm
显然,极紫外光的波长都超过7nm的1-2倍了。
二者之间的差别还体现在另外一个方面:乱序执行。X86是面对桌面和多任务用户的,所以在设计上对于CPU指令的乱序处理非常好,这也就意味着要做更多更复杂的预测和设计,才能保证乱序的执行不出问题。虽然我们只是简单的一句描述,但是在设计上是非常复杂的。而ARM是面对移动的,它本质上就没打算支持乱序,并且移动芯片现在都是片上系统(SoC)架构,图像、音频等各种硬件都在一起,调度顺序也是可以预测和控制的,这里在耗电量和功率上又进一步拉开距离。
所以这两者的设计本身不太具有可比性,设计的目的不一样,专攻的领域也不一样。
2、CPU工作原理
不管架构如何不同,最终进行工作的时候都一样。CPU主要是由运算器、控制器和寄存器组成,顾名思义,就是控制器取指令,交给运算器计算然后将结果存储在寄存器里。
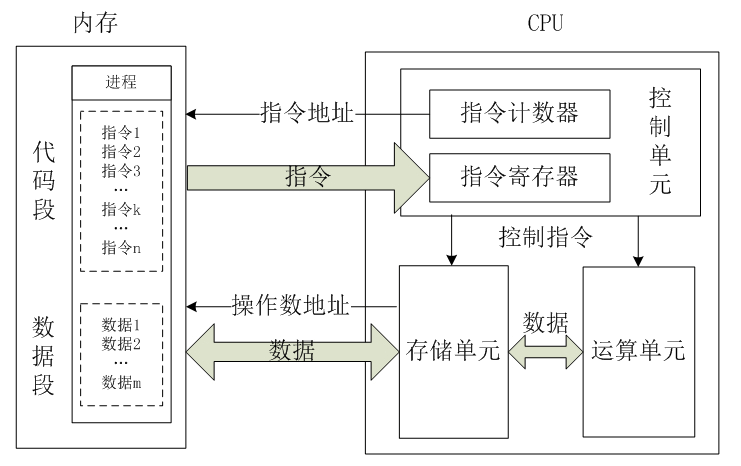
图片来自网络
YouTube上有课程可以查看整个CPU的执行顺序,地址:https://www.youtube.com/watch?v=FZGugFqdr60&list=PL8dPuuaLjXtNlUrzyH5r6jN9ulIgZBpdo&index=9&t=0s
我们截取其中一帧来说明:
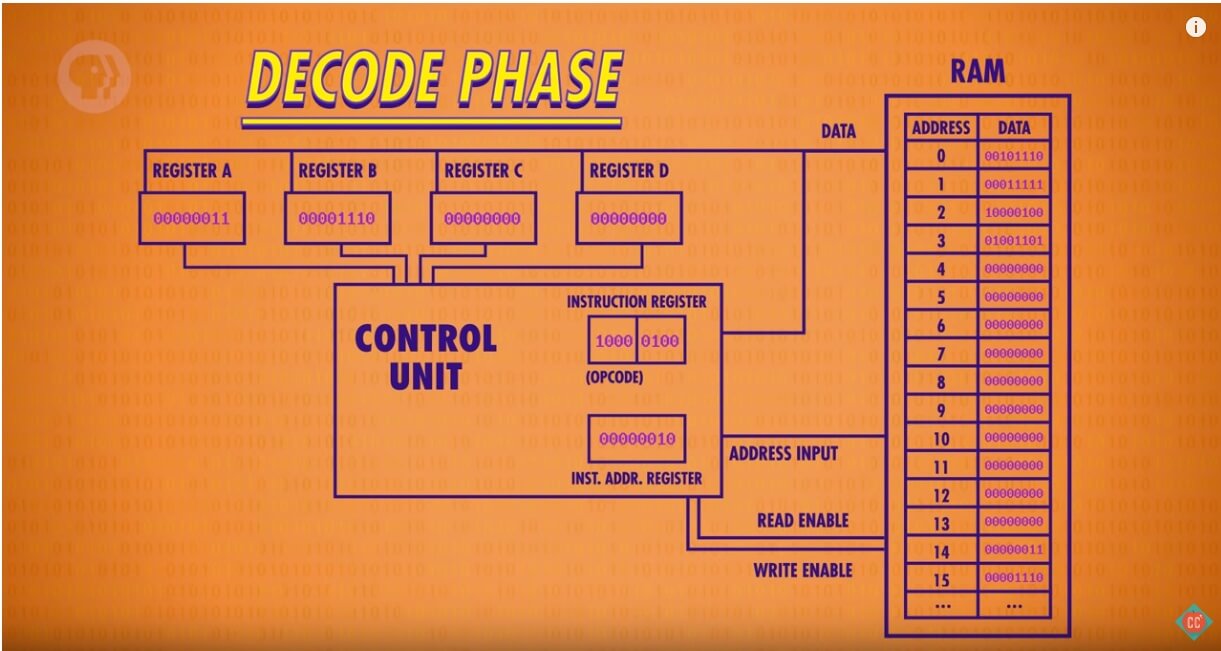
一条指令包含操作码和地址,操作码可以理解为CPU的支持的指令集,这个例子里,前面4位二进制标识操作码,后面4位地址:

所以我们从RAM的指令开始遍历,看看CPU怎么做事。
第一步先看地址0,将00101110拆解为0010和1110两个部分,前面的部分通过查询CPU指令得知是LOAD_A,就是把某个地址存放的值加载到A寄存器里,1110是14也就是把00000011加载到寄存器A。
第二步到地址1,按照同样的解析把00001110加载到B寄存器。
第三步到地址2,就是把两个数相加,然后存储到A寄存器里。看下图1000查指令得知是相加,0100表示A寄存器:

经过计算之后,寄存器A的值已经改变了。如下图:
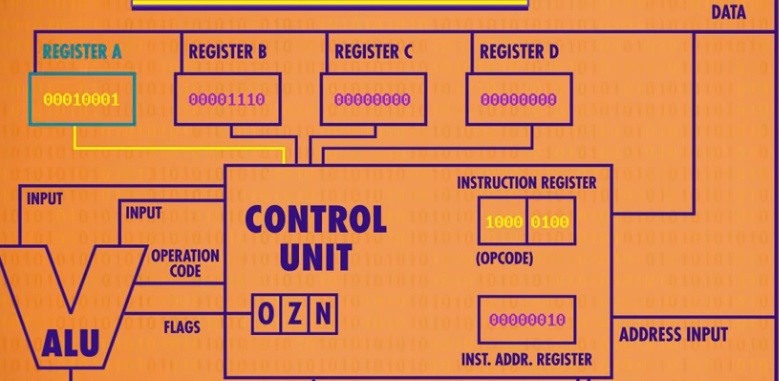
接下来进行第四步,到地址3:01001101,拆分之后就是0100和1101,前面操作码查表告知是存储,后面1101是13,也就是要把A寄存器的值存储到13位置里。
CPU的计算就完成了,所以结合上一个部分说的指令集来理解,一个指令集就代表CPU执行的一个操作。比如:5X3,Intel可能会使用5+5+5的方式,而ARM可能直接用硬件完成乘法,所以对于Intel需要3个周期完成,而ARM只要1个。
3、缓存作用
介绍了CPU工作原理之后,我们再返回来看现在主机的结构,除了CPU之外还有内存、显卡等等。那么我们的程序指令集首先要从硬盘里读取,加载到内存,然后通过总线传给CPU执行,CPU的工作频率都是2.xG、3.xG,而一个机械硬盘的速度是7200转/分钟。
所以我们需要内存来帮助加快指令读取和传递。即使内存速度高出硬盘N多(CPU是GHZ为单位,内存是MHZ为单位),但和现在CPU的频率相比仍然远远不够。从CPU的设计上也可以看到,CPU唯一的存储设备就是寄存器,一共就那么几个,不可能存储大量数据。所以每次计算完都需要找内存要东西,大量的时间就会在等待内存数据的传递中。想像一下马斯克用火箭运载货物,结果每次运完都要等一个小孩给他搬货。
那么改善的方法呢?当然是提高运货效率,这个方式就叫缓存。
越小的缓存离CPU的距离越近,设计上速度也越快,相对来说容量也越小。但是缓存级数也不是越多越好,因为CPU查找指令的时候是逐级查找,如果找到了倒也罢了,如果找不到就浪费了多次检索过程。
CPU在执行某个程序片段的时候,它会安排缓存帮它预测下次要查找的数据,然后逐级上报,如果下次查找的数据正好在缓存里,就叫缓存命中,如果不在,就叫Miss。如果Miss了,CPU就不得不亲自去内存里找,速度可想而知。
所以现在知道ECS面对数据编程,对于缓存命中的重要性有多高了。因为硬遍历就是指不做任何优化措施,直接做循环,但这种方式其实是比较符合CPU缓存设计的,所以本身天然的性能就会高一些;相反,如果做了四叉树的场景,则会打乱了CPU缓存,所以看起来算法上提高了,但是在CPU执行的时候性能并没有提升太多。(光线追踪的管线里有两次重要的排序,都是为了排列数据提高效率。)
4、缓存类型
先说一个概念:局部性,也就是程序在执行的过程中,无论是存取数据,还是读取指令集往往会呈现一定程度的局部性。
时间局部性(temporal locality):当前用到的一个存储器位置,在不久的将来还会被用到。
空间局部性(spatial locality):当前用到的一个存储器位置,它临近的几个位置也会被用到。
那么在CPU的层面,这两个局部性的特性就会被Cache执行,即将对拥有良好局部性的位置和指令进行缓存。来看一个具有时间局部性的例子:

这是一个简单的求数组和的函数,这里的sum和i都具有时间局部性。那么它们就会被Cache管理,被CPU取值命中。
再看一个空间局部性的例子,我们将这个一维数组改为二维。
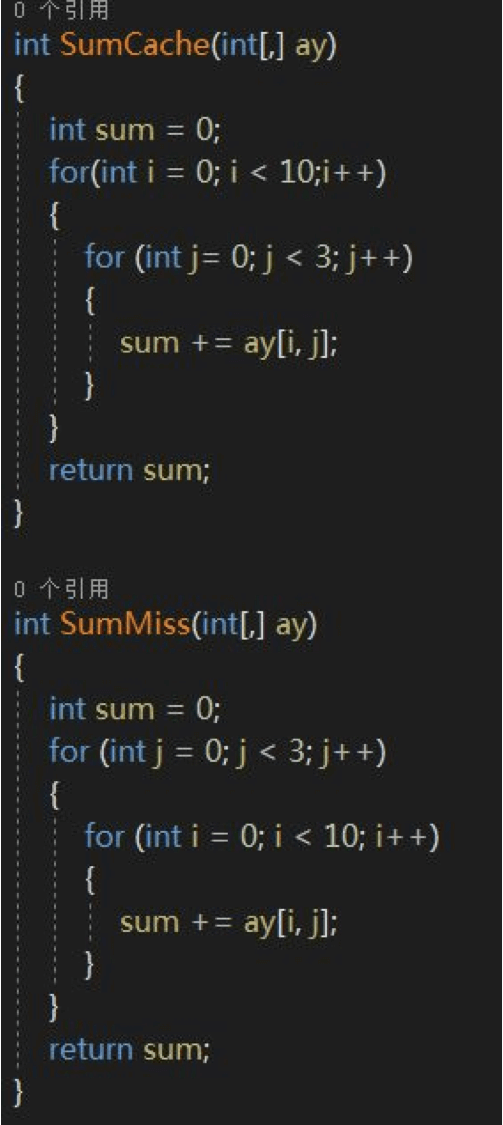
我们知道一个二维数组在内存里的排列是按行顺序排列的,大概是这样:
ay[0,0], ay[0,1], ay[0,2],ay[1,0], ay[1,1], ay[1,2]……
SumCache的写法会完全命中ay在内存里的排布,而SumMiss的写法则会Miss,二者的函数执行效率差距几十倍。
所以ECS的架构,就是对缓存命中最大的提升,也是ECS性能倍增的原因。下一节稍微讲一下Unity日后主推的面对数据栈技术编程即DOTS。
六、Unity面向数据技术栈(DOTS)
上一节,我们简单提及了一些CPU的架构,大体是根据指令集来区分的。在这篇文章里面还会对这部分内容做一些关联性讲述,会放在文章的后半段。
1、什么是DOTS?
DOTS是Unity一个阶段性的转变,也是Unity蓝图上一个非常重要的里程碑节点。Unity的官网为它建立了主题链接,甚至搭出了阶段性的口号:“重建Unity的核心!”,可见Unity对DOTS的重视程度。
那么DOTS的含义是什么呢?看下官网的截图:

高性能多线程式数据导向性技术堆栈 。可以看到DOTS的几个关键词:高性能、多线程、数据导向、堆栈 。
那么它用什么去保障这些关键词呢?
2、C# Jobs System
Jobs System命中了DOTS里的高性能、多线程和堆栈关键字。上一篇我们讲过CPU执行代码片段的大体流程,那么CPU执行程序的流程也基本和上一篇展示的一样,把代码编译成EXE,然后加载进内存、送进CPU中执行。
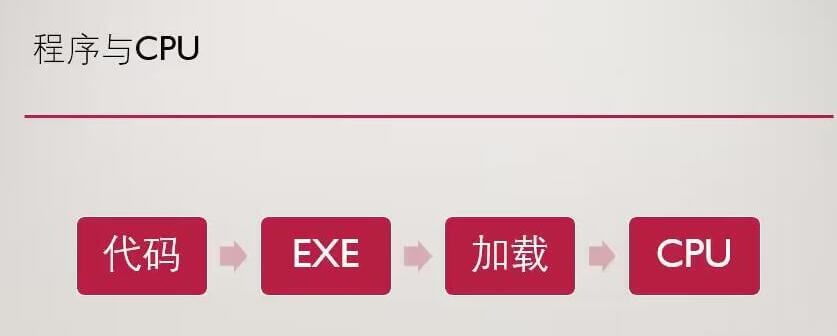
更详细的过程可以查看这里:https://www.cnblogs.com/fengliu-/p/9269387.html
(1)进程、线程和协程
现在的计算机结构大都是面向线程设计的了,但在计算机诞生早期的时候,计算机经历过从单一的程序处理逐步演变为多任务处理的过程。但不管是单一任务还是多任务,计算机执行的基础单位都是进程(如果这部分的基础确实不强,你可以粗略认为一个EXE就是一个进程)。每一个进程之间是有独立的资源分配的,包括但不限于文本区域、数据区域和堆栈区域。
文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。那么计算机又是怎么执行多个程序的呢?答案就是操作系统。
操作系统统一管控计算机的各个硬件资源,然后按照调度需求分别给不同的进程执行指定的时间片段,因为计算机的处理速度非常快,所以会让用户感觉在同时运行多个程序(进程)。但是这种模式也不是没有成本的,当并行的进程数量过多的时候,切换进程的代价就会非常大,因为它必须要先把当前的上下文存储,然后加载新的上下文,然后执行片段时间,备份存储,再执行下一个进程片段。切换上下文的代价有时候比执行本身的代价还要大。
线程是CPU执行的最小单位了,现在我们说多线程都是指这个。线程是进程中的实体表现,一个进程可以拥有很多个线程,每个线程受CPU独立调度和分派,可以想象Unity移动游戏开发中,Unity的主线程和网络的socket线程就是一个多线程的表现。
现在的计算机因为多核的并行计算,所以程序设计也更多的基于多线程的方式去设计。(这里要理解一个概念,并发和并行。并发就是进程的执行模式,指多个任务在同一时间段内交替执行;并行是线程的执行模式,不同的线程在同一时间段同时执行。)
线程的另一个表现就是资源共享,同一个进程里的不同线程共享内存地址和资源。它自己本身不会申请系统资源(除了运行时必须的那一小点儿),所有的资源都来自于包含它的进程空间,这让程序处理资源更加的快捷和便利,利用多线程的优势来提高计算效率,当然这也正是多线程编程的难点所在。即使在多核CPU和面向线程设计的计算机结构面世这么多年,仍然不能普及多线程编程。
协程可以简单地理解为用户自定义线程。对于进程和线程,你一旦创建了,就失去了对它的控制权,只能交由内核去分配时间片和执行。但是协程是用户自己创建的一个“线程”,所以从操作系统的层面来说,它不受内核调度,你可以在一个线程里创建无数个协程(硬件允许)来辅助你的代码逻辑,你可以自己控制它的执行时间和状态,也可以通过一个协程拉起另外的协程,而只需要牺牲很小一部分的切换代价。
总结来说,一个进程可以拥有很多个线程,每个线程又可以创建很多个协程。进程负责独立的地址空间和资源管理,线程共享进程的这些资源。线程提高了CPU的并行能力,但是进程方便跨平台移植,但这两个都需要消耗计算机的切换上下文的调度时间。协程在线程内执行,避免了无意义的调度,调度责任转移给了开发者,同样因为寄生在线程内部,不能由内核调配,也无法充分利用硬件资源。
(2)多线程编程
前面说了一个线程是内核调度的最小单元。那么根据运行环境和调度组的身份,又可以分为内核线程和用户线程。顾名思义,一个内核线程就是运行在内核环境,由内核分配和调度的线程。用户线程是运行在用户空间,由线程库来调度的。
当一个进程的内核线程获得了CPU的使用权限之后,它就会加载一个用户线程来执行,所以这么看来,内核线程其实就是用户线程的容器。
由于线程之间是共用同一个进程的资源的,所以线程的安全也是多线程编程最需要注意的问题。简单的来说就是如何管理多线程对于同一个资源的访问和修改,确保它们能按照正常的逻辑执行不出问题。
比如:线程1需要改写a的值,而线程2需要读取a的值,因为线程的调度由内核控制,所以如果执行的顺序错了,结果就会完全偏离(行业术语叫做“竞态条件”)。
解决的方法大概罗列一下(不详细叙述):
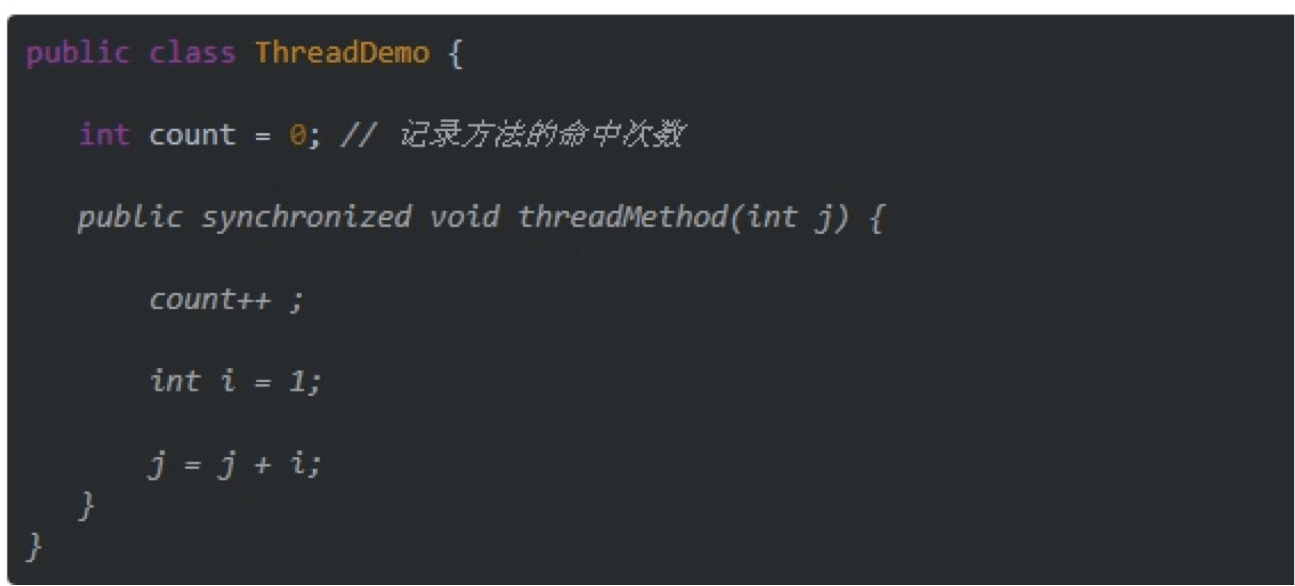
- 在关键的方法前面标识synchronized,这会让后面需求的线程等待,直到前面持有的线程完成调用。缺点是如果锁住的方法不是静态,那么就会锁住对象本身,所有对这个对象的访问都要等待。如果代码中存在多个synchronized方法则会严重影响性能。
图片来自网络
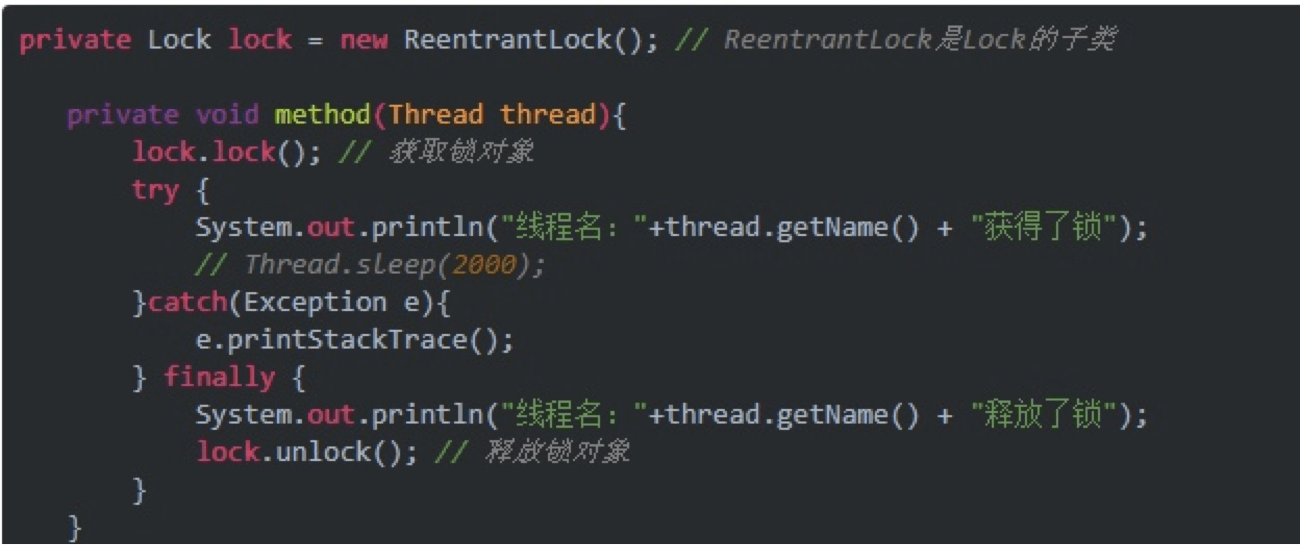
- Lock这个方法和synchronized不同之处在于:Lock是按需去锁,这种就需要自己对于变量有较强地把控。
(3)Jobs System的多线程
严格来说,Jobs System并不属于多线程编程的范畴,因为它不能直接对线程进行操作。相应的,它为了保障线程安全,独立封装了多线程的调度框架,用户只要继承一些类和接口,并且使用满足条件的指定数据类型就能完成高性能的计算,所以我个人认为jobs是一个多线程的调度框架而不是编程框架。
jobs为了避免和主线程的数据发生冲突,所以避免使用引用类型。另外,还定义了一套自定义的数据结构,使用专门的未托管内存进行管理,称之为原生容器(NativeContainer)。包括以下几种:

一个简单的使用jobs的示例代码:
(1)定义一个struct继承自Ijob。
(2)添加jobs 使用的数据类型,(Blittable types或者NativeContainer类型)Blittable types可以理解为C#的值类型,包括:

(3)重写Execute方法。

要非常小心的是,除了NativeContainer,其它都是数据的copy。所以要想从主线程访问计算的结果,唯一的方法就是放到NativeContainer里面。
jobs的使用其实并不是很方便,有很多需要注意的地方,可以参考官方手册查看常见的坑点:https://docs.unity3d.com/Manual/JobSystemTroubleshooting.html
3、Unity ECS
ECS命中了DOTS里的高性能、数据导向和堆栈关键字。
前面的一些章节,我们已经详细地讲过ECS的思想以及高性能的原因和一个基于Unity比较老的插件——Entitas。那么这一部分我们就不再拓展讲解ECS的原理部分,只看看它和我们之前的Entitas有哪些区别。
Unity的ECS组件叫做Entities,和Entitas名字很像。但是实现的架构其实完全不一样。
先来看下创建Entity和设置Component:


再看下System:
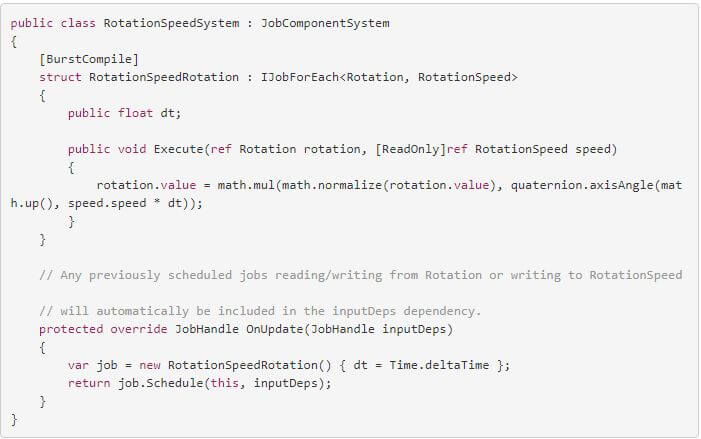
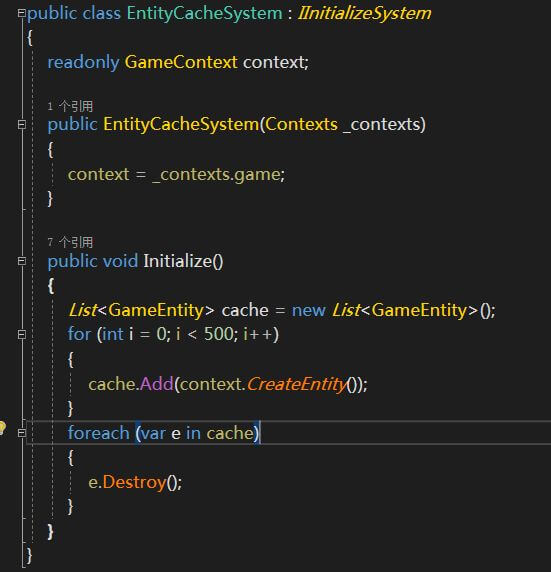
毕竟是亲儿子,Unity ECS里的System那是三管齐下了。[BurstCompile]标签、job已经全部用上了。需要详细了解的,请戳文档:https://docs.unity3d.com/Packages/com.unity.entities@0.0/manual/index.html
4、Burst
Unity目前主推的编译器,号称是比C++编译器还要快的存在。这里直接放官网的描述来看:

这部分的结构主要还是命中高性能的关键字。
我们在讲LLVM之前,先简单讲讲Unity一直在使用的技术方案。
打开新版本的Unity(2018.4),在player Setting选项里可以看到这个:
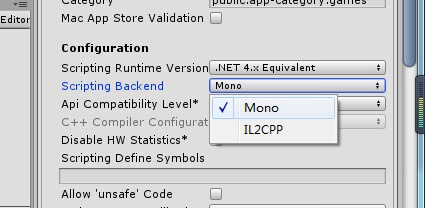
目前默认的是Mono和IL2CPP两个编译选项。
(1)Mono
Mono就不用说了,是Unity跨平台的基础,也是赖以起家的手段。为Unity服务了这么多年,目前已经到了退役的阶段。
作为IL中间件的执行载体,为不同的平台提供了ILR。
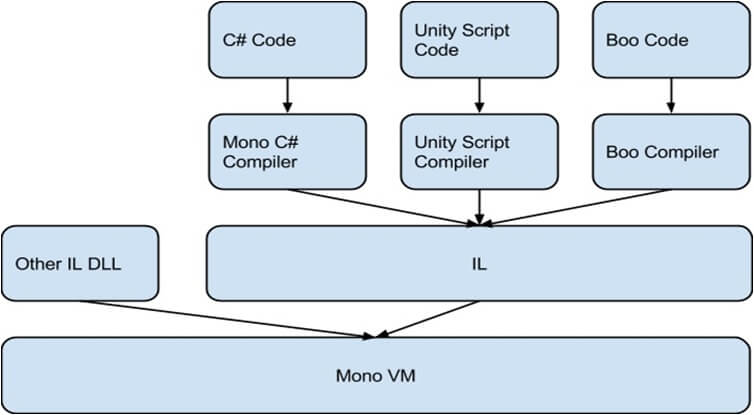
看下Mono的执行过程。
虽然为Unity实现了跨平台,但是越来越多的问题累计,导致Unity不得不抛弃它,另寻出路,主要有几点原因:
- Mono的版权受限,导致Unity往往不能在最新版中使用C#的最新特性。
- 性能存在较大问题,毕竟是虚拟机。
- 维护非常困难,虽然IL是统一标准,但是VM不是!每个新增平台,Unity都需要自己为它们准备VM,Mono是一个开源的项目,但它并不会及时跟进每一个新硬件平台的VM编写,所以Unity得自己移植或者编写,而一些基于Web的平台,几乎要完全重写,比如:WebGL。
- Mono无法完成64位版本要求。尤其是今年8月,谷歌已经强制要求谷歌商店的APP必须同时提供64位版本。IL2CPP是目前满足条件的唯一选择。
(2)IL2CPP
IL2CPP看名字就看出来,这是一个将IL语言转换为CPP语言的工具,看下它的执行方式:
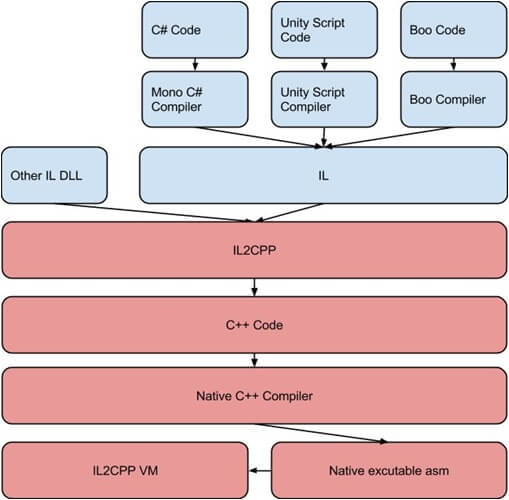
可以看到下面红色的部分,IL2CPP会将编译好的IL代码重写成CPP的代码,这样在使用每个平台的原生编译器,编译为原生平台的可执行文件,由于抛弃了虚拟机,并被原生编译器优化过,所以极大地提升了程序性能。
看下官方给的数据,平均性能提升1.5-2.0倍。

注意,我刚才其实有说IL2CPP抛弃了虚拟机,但是在上面的执行过程图里仍然有IL2CPP VM的过程,这是因为C#本身是基于托管代码设计的语言,IL本身也是托管代码执行的,所以IL2CPP即使将IL转为了CPP语言,这部分的设计框架是没法转换的。所以IL2CPP要起一个VM来管理内存,以及分配线程等管理工作。与其说是一个VM,其实描述为一个管理器更加贴合。
这里要注意VM和管理器的区别,一个是完全承载代码的解释和执行工作,一个只是负责管理一些内存和特性,所以从大小和复杂程度来看,后者都远远小于前者。另外由于IL2CPP的内存更像是一个管理器,所以它申请的内存会还给系统,和MONO相比起来,IL2CPP的堆内存峰值是会下降的。
(3)LLVM
从Unity的专题页面描述可以看到,Burst是基于LLVM来编译的,所以先看下维基百科对LLVM的定义:
LLVM是一个自由软件项目,它是一种编译器基础设施,以C++写成,包含一系列模块化的编译器组件和工具链,用来开发编译器前端和后端。它是为了任意一种编程语言而写成的程序,利用虚拟技术创造出编译时期、链接时期、运行时期以及“闲置时期”的最优化。它最早以C/C++为实现对象,而当前它已支持包括ActionScript、Ada、D语言、Fortran、GLSL、Haskell、Java字节码、Objective-C、Swift、Python、Ruby、Rust、Scala以及C#等语言。
链接:https://zh.wikipedia.org/wiki/LLVM
LLVM提供了完整编译系统的中间层,它会将中间语言(Intermediate Representation,IR)从编译器中取出并进行优化,优化后的IR接着被转换及链接到目标平台的汇编语言。LLVM可以接受来自GCC工具链所编译的IR,包含它底下现存的编译器。LLVM也可以在编译时期、链接时期,甚至是运行时期产生可重新定位的代码(Relocatable Code)。
大概来看下过程:
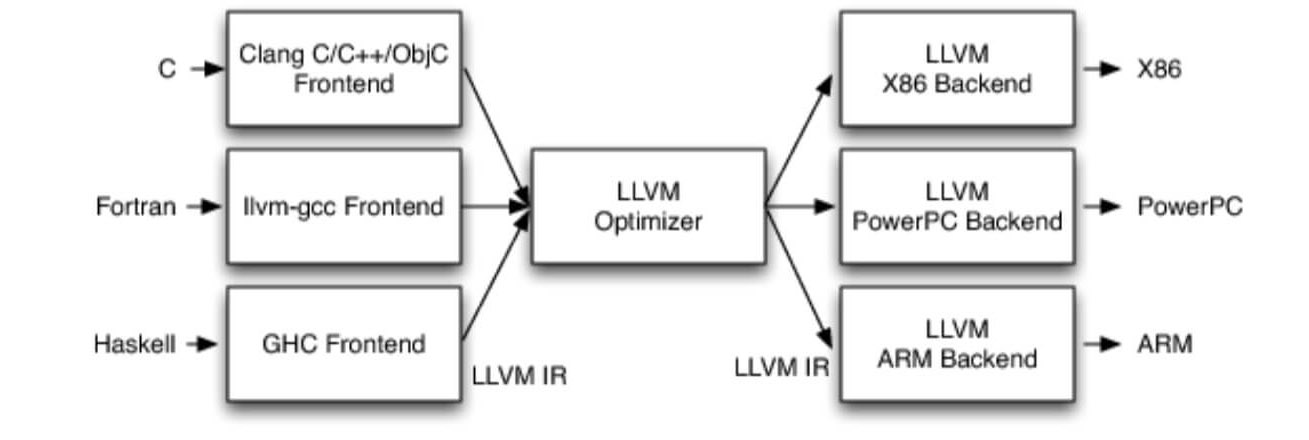
LLVM分为前端、中间件、后端三个部分。
前端:简单来说就是通过对不同语言的词法、语法和语义分析,产生中间件代码。
中间件:LLVM的核心是中间件表达式(Intermediate Representation,IR),一种类似汇编的底层语言。IR是一种强类型的精简指令集(Reduced Instruction Set Computing,RISC),并对目标指令集进行了抽象。
一个简单的Hello World程序可以表达为如下的汇编形式:

后端:最关键的就是它支持与语言无关的指令集架构和类型系统。(还记得我们上一篇讲过简单指令集(ARM)和复杂指令集(X86)的区别吗?)
到目前为止,LLVM已经支持多种后端指令集,比如:ARM、Qualcomm Hexagon、MIPS、Nvidia并行指令集(PTX;在LLVM文档中被称为NVPTX),PowerPC、AMD TeraScale、AMD Graphics Core Next(GCN)、SPARC、z/Architecture(在LLVM文档中被称为SystemZ)、X86、X86-64和XCore。有部分平台功能并没有完全实现,但X86、X86-64、z/Architecture、ARM和PowerPC的基本所有功能都有实现了。
链接器:LLD链接器子项目旨在为LLVM开发一个内置的,平台独立的链接器,去除对所有第三方链接器的依赖。在2017年5月,LLD已经支持ELF、PE/COFF和Mach-O。在LLD支持不完全的情况下,用户可以使用其它项目,如:GNU ID链接器。LLD支持链接时优化,当LLVM链接时优化被启用时,LLVM可以输出Bitcode而不是本机代码,本机代码生成由链接器优化处理。
看完LLVM的原理,是不是觉得很熟悉?和Mono很像?都是先把第三方语言转化为中间件,然后再对中间件做兼容处理?但是要注意的是,Mono针对的是运行期,而LLVM针对的是编译期。并且前面说了Mono是针对硬件平台的虚拟机,而LLVM是针对指令集的架构。所以无论是从性能还是数量以及扩展性上来说,LLVM都是远远高于Mono的。(据说Burst编译器最好的时候比C++的快30%)
针对Unity的DOTS就是这个全家桶,有很多相关技术视频在官方主题网页里,想要了解更多可以去听一听。目前ECS战斗相关的文章共写了六章,已经全部完成。
Unity官方主题:https://unity.com/cn/dots
封面图来源于网络
这是侑虎科技第614篇文章,感谢作者放牛的星星供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/niuxingxing,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!