如何大幅优化NGUI的堆内存分配
- 作者:admin
- /
- 时间:2018年07月25日
- /
- 浏览:10897 次
- /
- 分类:厚积薄发
目前,在Unity游戏项目中,依然有很多团队使用NGUI作为UI解决方案。相比UGUI,其临时堆内存分配过多始终是NGUI的一个缺点。本文旨在修改NGUI的几处底层实现,从而规避堆内存的临时分配。
文末,我们通过复杂的实例来对此方法来进行测试,通过比较可以看出,该方法可以大幅优化UI界面在运行时的堆内存分配。文章中对于NGUI解决方法的优化主要包括以下几个方面:
- 对UIGeometry的顶点属性做了缓存池,并保证OnFill时进行按需选择;
- 通过unsafe的方法来修改IndexBuffer的长度;
- 填充数组前充分设置List
.capacity;
我们希望通过该篇文章,可以大幅降低您项目中NGUI的堆内存分配,以下则为具体的优化方法,大家通过具体的代码说明来进行逐一修改即可。
注意:所有本次优化相关的代码都用OPTIMISE_NGUI_GC_ALLOC宏区分开了,使用的NGUI版本是3.11.4。
UIGeometry的verts、uvs、cols、mRtpVerts缓冲池
UIGeometry记载了UIWidget的顶点信息,可以采用缓存池的策略,当UIWidget.OnFill的时候确定了需要顶点数量的情况下从缓存池申请,当UIWidget.OnDestroy的时候放回缓存池,回收的时候以顶点数量从小到大插入,申请的时候找到第一个满足需求顶点数量的。

缓冲池的实现

UIWidget.OnDestroy的时候放回缓存池
UISprite和UITexture我优化了三种类型:Simple、Sliced和Tiled。以下代码出现在UIBasicSprite.cs里,这里只贴了SimpleFill的完整实现,其他两个类型的顶点数计算部分有些区别:

以下是Sliced类型的顶点数计算部分:

以下是Tiled类型的顶点数计算部分:

因为上三个函数都可能在UIBasicSprite.Fill中给UIGeometry的几个List赋予新的实例,所以在UITexture 的OnFill中相关代码需要改成这样:
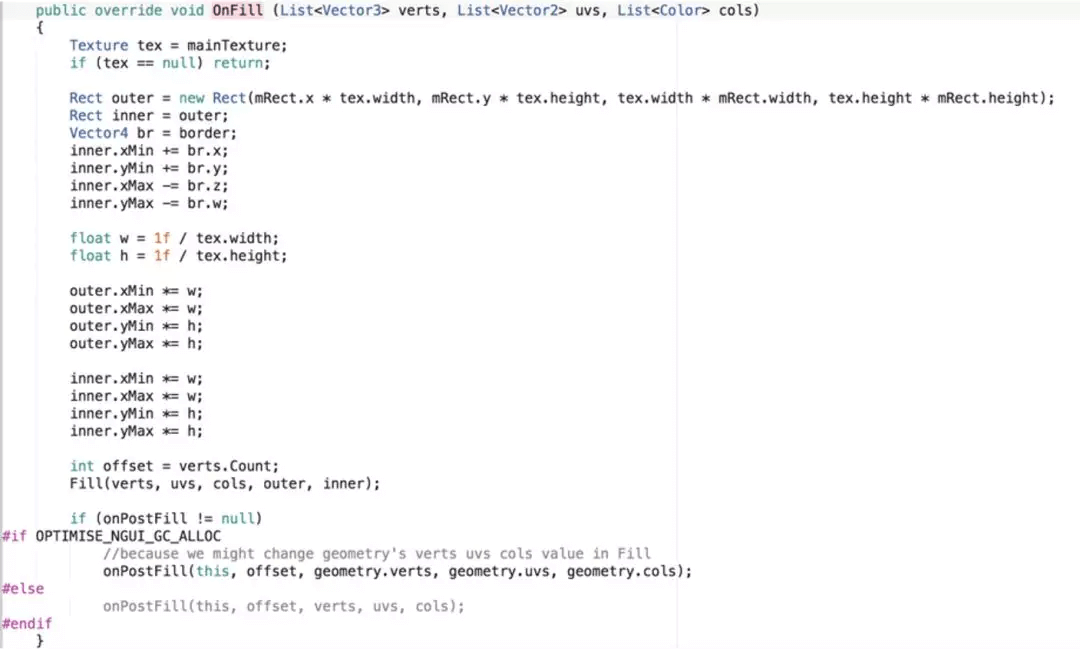
UILabel.OnFill里额外提供了一个缓冲供NGUIText.Print使用,里面也考虑了UILabel带有描边和阴影时的优化。

NGUI创建Mesh时顶点索引缓冲的优化
从原来的顶点索引的生成算法来看,假设有一个顶点索引缓冲长度为9000,另一个有1w,那么这两个缓冲的前9000个索引的值是一样的,而且Mesh.triangles需要顶点索引缓冲的数量为顶点缓冲数量的三倍,所以最好是有个能够能动态调整Array.Length但Array的元素可以不发生变化的办法。
Nordeus在Unite2015上分享了一个VaryingList可以做到:
https://github.com/Nordeus/Unite2015/tree/master/VaryingList
把BufferedList.cs和VaryingList.cs下载到工程,开启Unsafe就行了,它主要是通过Unsafe的方法来实现我们要的功能。这样,我们只需要一个顶点索引缓冲,而不是原来的10个,而且我们只在缓冲不够大的时候从新分配内存并只填充增加了的顶点索引缓冲,而当需要的顶点索引缓冲比当前的小的时候只需要通过Unsafe方法设置下长度就行了。涉及到的代码在UIDrawCall.cs中。
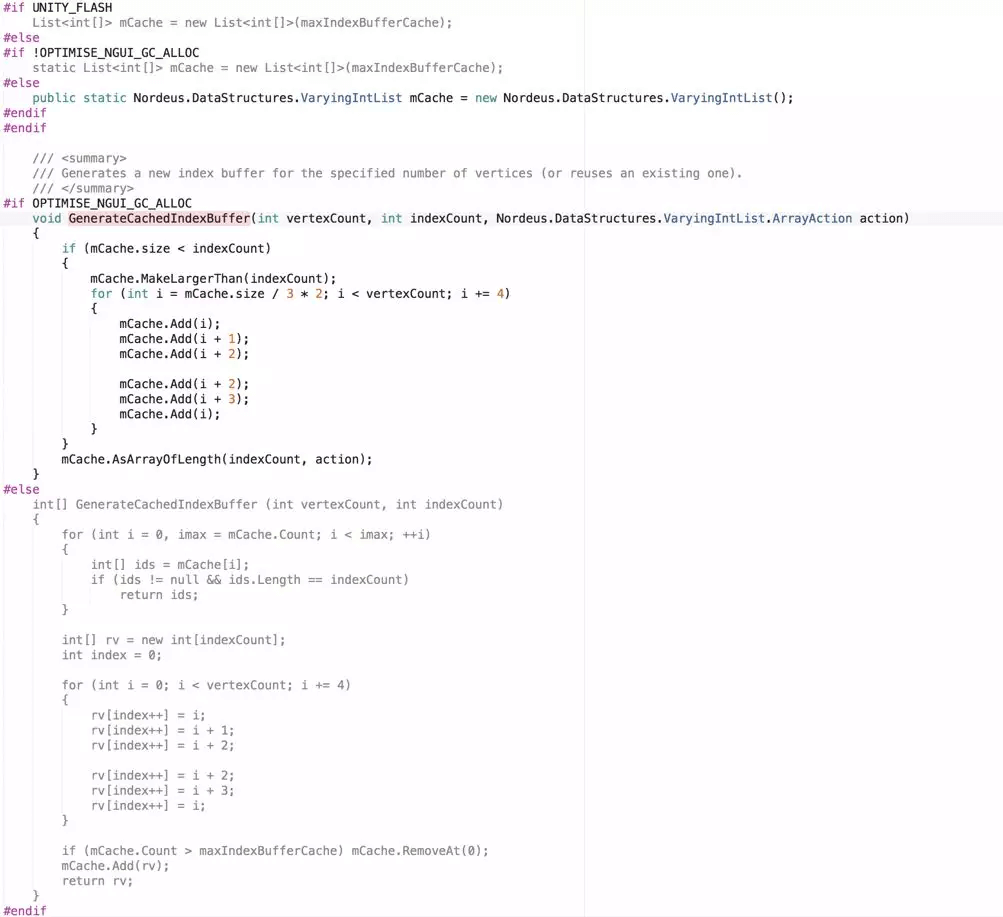
GenerateCachedIndexBuffer的修改

函数的替换
插入前充分设置List.capacity来减少GC Alloc
首先需要包装一下这个操作,List
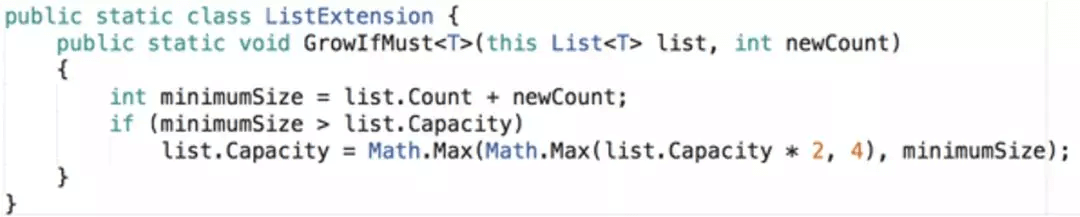
在UIPanel中,需要对FillAllDrawCalls和FillDrawCall进行优化,收集每个UIDrawCall对应的UIWidget和总的顶点数,然后一次性对UIDrawCall里的几个List


UWA实测总结
针对优化的特点,UWA进行了以下测试,对比其在堆内存优化上的效果:首先依次隔帧创建以下面板,然后每隔100帧依次隔帧进行界面切换(从禁用变为激活,或者从激活变为禁用)
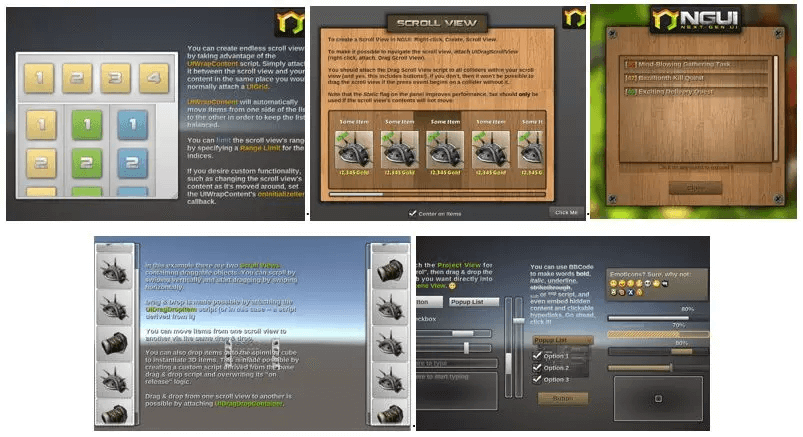
经过1000帧的测试,原始的NGUI累积分配了23.5MB的堆内存(左侧数据),而优化后的NGUI累积分配了9.7MB的堆内存(右侧数据)。
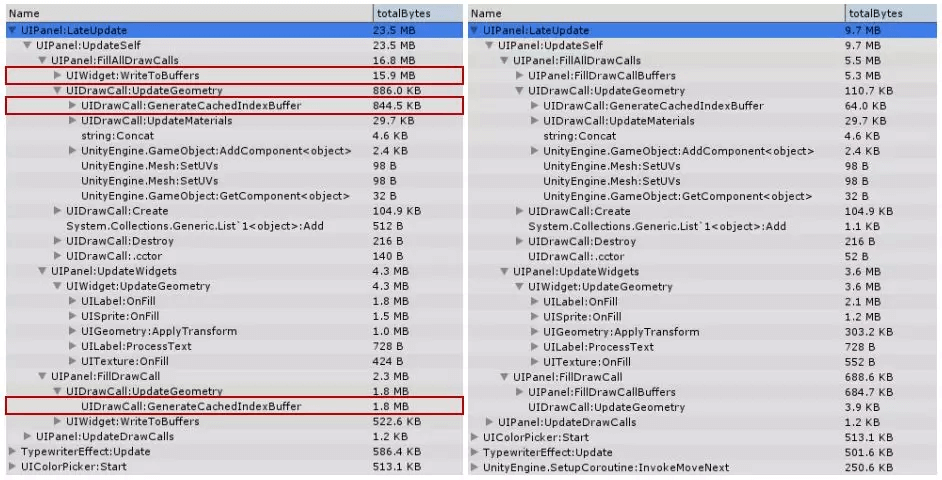
从数据中可见,把WriteToBuffers替换为FillDrawCallBuffers的优化是最为明显的,降低了约10.6MB,是原来的1/3;其次就是UIDrawCall:GenerateCacheIndexBuffer的优化,也下降了约2.5MB。
以上,则为作者对于NGUI底层代码的详细完善和优化,希望它可以切实有效地帮到你。另作者已将修改的代码放在GitHub主页,大家可以前往摘取:https://github.com/sophiepeithos/optimise-ngui-gc-alloc
这是侑虎科技第421篇文章,感谢作者邓晖供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。QQ群:793972859(原群已满员)
作者主页:https://github.com/sophiepeithos/optimise-ngui-gc-alloc,作者也是U Sparkle活动参与者,UWA欢迎更多开发朋友加入U Sparkle开发者计划,这个舞台有你更精彩!