
大地形的一种简化RVT
- 作者:admin
- /
- 时间:2024年03月06日
- /
- 浏览:4023 次
- /
- 分类:厚积薄发
【USparkle专栏】如果你深怀绝技,爱“搞点研究”,乐于分享也博采众长,我们期待你的加入,让智慧的火花碰撞交织,让知识的传递生生不息!
一、开发需求
这是工程开发的细节,不是理论篇,不了解RVT理论概念的,请先搜索。
RVT的理论普及度比较高,FARCRY5和Unreal Engine里都有大量的分享,这种方案工作量和难度主要是在工程细节上。也就是一个资深技术完整按方案写完落地功能大概要1个月。所以我很想造一个既有差不多性能收益,又简单很多的实现方案,差不多开发3天可落地项目。
为什么要对地形做RVT?因为地形的采样除了抖动混合,其他都需要非常多次的采样Albedo和Normal然后混合。这已经成为多数项目在GPU方面的最大开销,所以有必要缓存他。其次,地形的Mesh结构单一性、材质统一性、贴图共用性都导致仅对地形实现RVT是比较方便的。
以下是我参与的项目4年多来地形渲染的技术迭代过程,本来计划仅1次采样的抖动混合作为终极方案,实际上产品和美术对于噪点难以接受。这样就反而简单了,必须开发RVT的想法就在我脑中种下了。
真实项目落地补充
普通视角:提升2ms,70fps->82fps。截图为最大收益处空气背包与跳伞时:
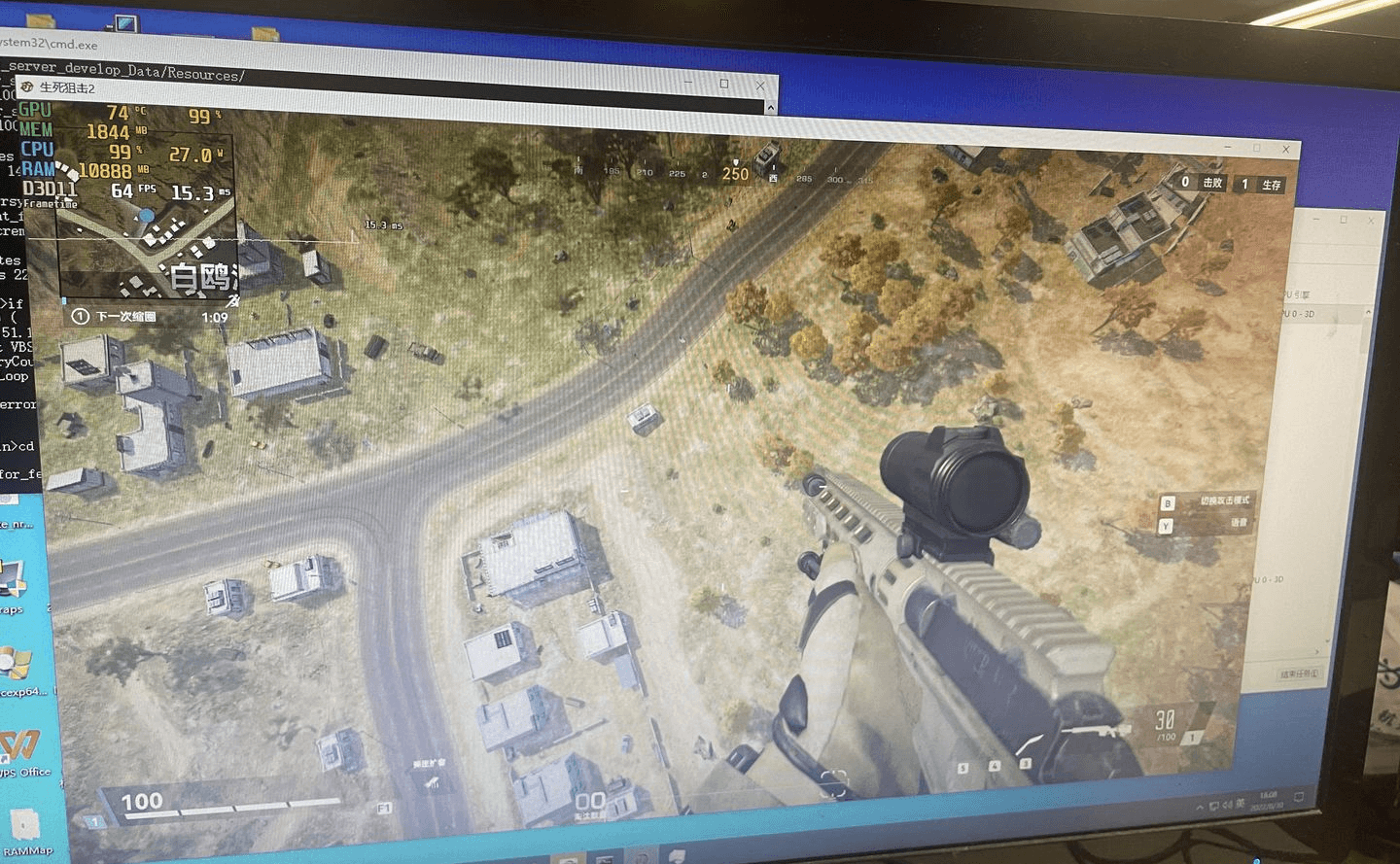
1050 中画质 线上游戏地形(优化前)
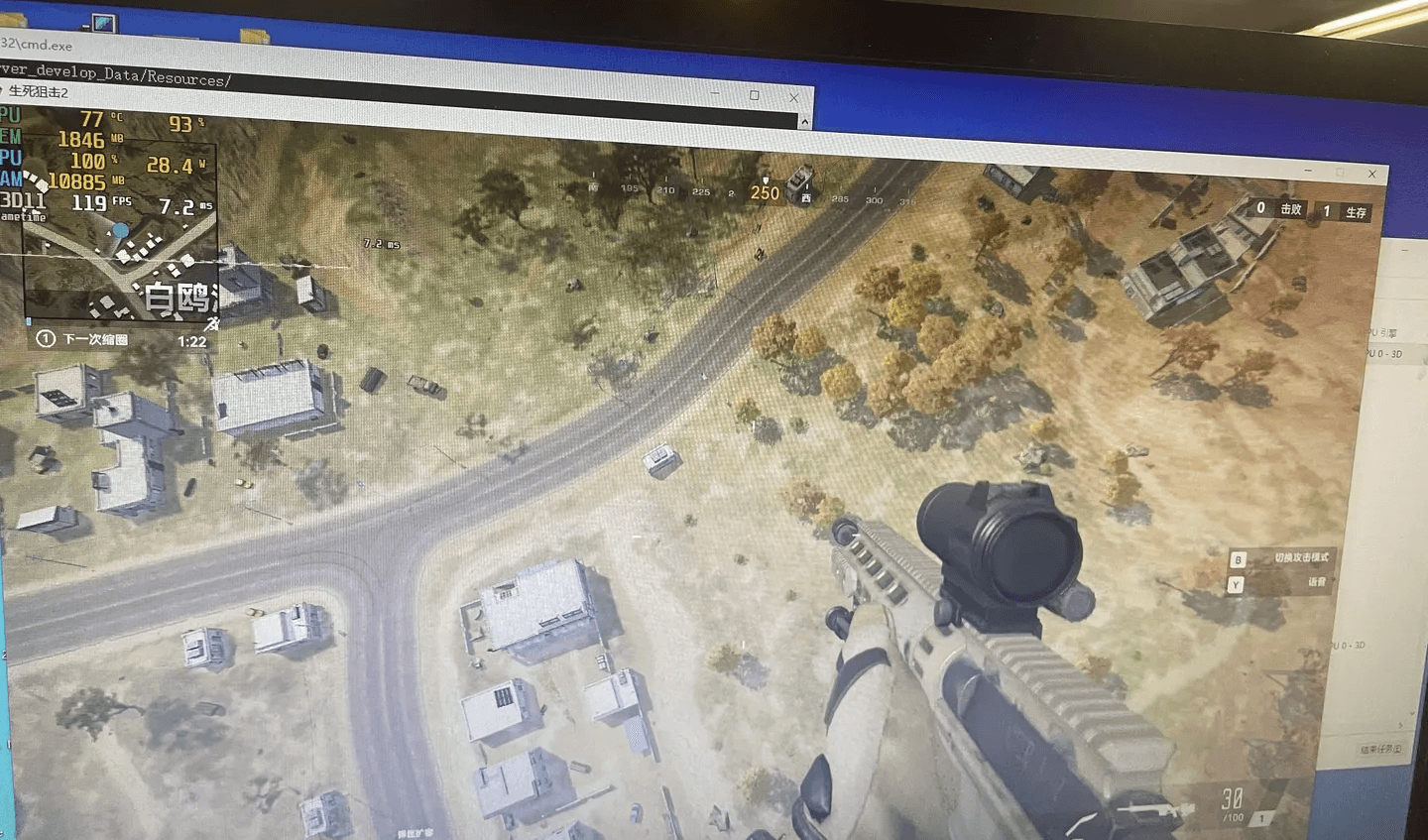
1050 中画质 线上游戏地形(优化后)
二、性能对比
采用i5-9600KF+AMD、RX590、Unity 5.6测试,总共16层地表。
静帧对比
Unity自带地形:231 FPS
本方案地形:546 FPS
移动时对比
看视频里帧数
先放效果图看下收益幅度,或许才有耐心能看完细节。后面与GPUDriven地形结合,性能会更好,因为这已经是地形地块CPU瓶颈了。

三、主要思路
原文的思路有很多种,也很复杂。首先要多渲染一份数据,然后Feedback,延迟一帧获得,然后各种VT的不同尺寸,覆盖不同PageTable的数量,对应物理贴图图集里的不同大小,这些不同大小的覆盖或对应关系有些是在1个Mipmap里做,有些是放到不同的Mipmap上实现,以及物理贴图图集里,不同尺寸可用空间的申请、回收、占用维护等。还有异步加载时处于为准备好的区域如何寻找代替的更低精度的Mipmap地址等等。看的我非常晕,所以这一刻忘记这一切概念。重新想一个最最简单直观的。先用四叉树划分地块,这一点之前做四叉树静态阴影和四叉树GPUDriven的地形都用到过。所以比较简单了。
根据相机距离如下图这样划分世界空间,并给每个空间分配一个独立的编号,叫他物理地址索引。我们只要让每一块都用一张相同大小的贴图去显示,那么自然就是比较合理的使用显存了,也等于是近处用了mipmap0,远处用了mipmap1,2,3....了,用这种思想来实现就直观且方便很多,因为所有贴图尺寸一样可以用一个Texture2DArray来存放,而编号就是这个数组的Index。当某一块的尺寸需要变化时,才重新加载变化后对应的图。

用四叉树把世界空间按xz平面投影(根据相机距离)划分方式
四、四叉树的实现
四叉树是这个方案的主要功能所以会写得比较多。四叉树虽然反复使用,但常常长的不同,这是因为有时候需要用来遍历,有时候需要用来查找,有时候是为了内容相近而压缩数据,有时候是做LOD划分。所以这里详细讲下这次四叉树的实现细节。
因为上图每个要显示的节点都是叶节点,不是枝节点。所以常见有2种方式遍历。
- 每帧从根节点开始遍历,递归查询自己的4个子节点,做LOD是否发生变化的判断
- 把叶节点,记录到一个队列里,每帧只对这些叶节点做LOD是否发生变化的判断
为什么要判断LOD是否发生变化呢?因为如果LOD没变,那么原来显示图不需要替换,就不需要做任何处理。如果发现远离了相机并且LOD需要更大,那么说明不需要这么高清了,他可以尝试合并,用他父节点来加载一张覆盖更大面积的图来显示(图是一样尺寸的所以覆盖更大面积等于更低精度),反之相机靠近了,LOD就需要小,他就需要细分出4个节点,每个节点都去加载对应的图,这样他就精度翻倍了。
我把这2种都实现了一遍,发现第2种的代码逻辑更直观,第1种需要做一个状态维护,所以这里讲第2种的方式。
四叉树数据结构

四叉树数据结构
static变量:
currentAllLeaves:当前帧所有叶节点
nextAllLeaves:下一帧所有叶节点
physicEmptyIndexQueue:可用的物理地址队列
onLoadData:某节点需要加载贴图资源时回调,因为这种加载一般不做在树结构内
splitCount:当前帧已经细分的次数
eventFrameSplitCountMax:每帧可细分的最大次数,与splitCount一起,避免在同一帧加载太多导致卡顿,实际是一种简单又高性能的分帧机制。分帧加载机制,我用分帧细分四叉树代替,极大简化了维护。否则异步的加载,相邻部分加载完成替换索引会出现脏数据等问题。
成员变量:
x,z,size:四叉树最最基础的数据,记录这个格子坐标和尺寸
children,parent:描述四叉树树结构关系的引用,类似Transform
isLeaf:判断是否是叶节点
parentMerged:当前帧Parent是否被合并过了,因为遍历某节点的4个子节点顺序是不可控的,避免出现一个子节点判断应该合并,但其他子节点却判断为细分出现矛盾。
physicTexIndex:当前节点的物理贴图(Texture2DArray)索引,用他来渲染自己覆盖的区域
创建根节点
一个树一般手动创建根节点,然后通过规则让他自己内部去细分或合并。也常在这里做些初始化或静态数据创建。这里主要是创建一个Node节点size获得一个物理地址,并放入叶节点。因为这个时候,根节点就是叶节点,他还没子节点。这里没设置xz,是因为不论真实场景如何,四叉树内部都是从(0,0)点开始往x+,z+方向去计算的。外部的实际情况可根据Offset调整,不在内部考虑外界的特殊性。
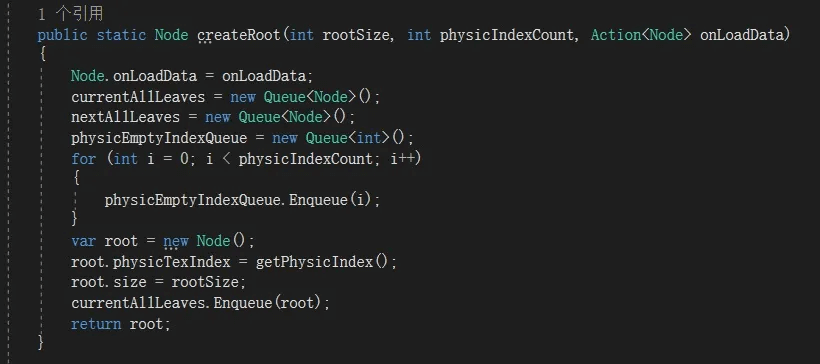
创建根节点函数
每帧更新所有叶节点状态
遍历所有当前叶节点,检查LOD是否发生变化,如果没变化就放入下一帧叶节点队列。如果变化,根据变大还是变小来做合并还是细分的处理,最后是常见的交换2个列表,下一帧的数据作为下一帧的“当前”数据反复遍历。不用简单赋值而用交换,是因为不想每帧New一个空队列产生GC。
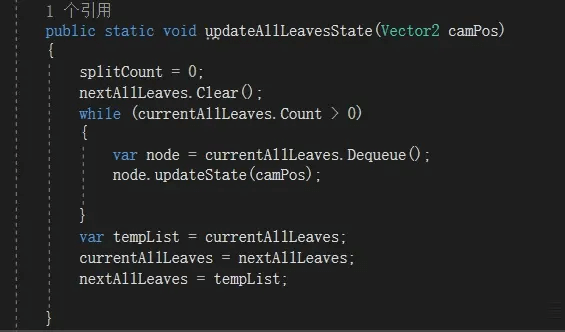
每帧主循环
对于每个节点,首先判断他父节点是否需要合并,如果自己和其他3兄弟节点都没子节点且 父节点计算后LOD发现应该合并,那么才执行合并,并且设置每个子节点的parentMerged为true,如果不能合并再判断自己是维持到下一帧还是细分,细分也有很多约束,这些细节的考量是我花的主要时间。

节点LOD计算判断是维持还是合并还是细分
合并与细分
合并函数比较简单,把自己放入叶节点,把4个子对象标记合并后,回收子对象物理索引,分配自己一个地址索引然后加载这个索引对应的资源。
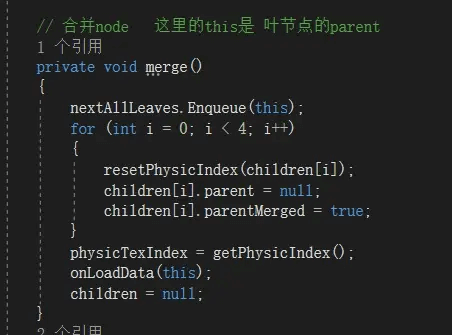
节点合并
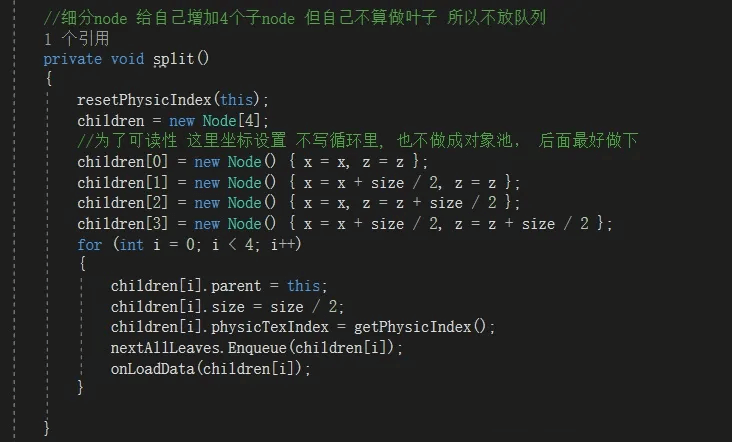
节点细分
不论合并还是细分,每帧都只执行一次,这样很好地实现了分帧处理,如果要更好的效果还需要设置权重决定处理的顺序,比如近的优先,或LOD变化大的优先。还有一个小技巧就是先回收索引资源,然后再分配,这样减少一点点资源不足的情况。
每帧只对一个叶节点处理一次 实现自然的分帧效果
实时移动相机的四叉树分帧细分与合并效果
创建贴图内容
分配了索引之后,我们可以根据节点所在的位置和Size,去加载这块混合后的贴图。并拷贝到Texture2DArray对应的Index里。这里说的加载不是真的加载,如果是SVT那就是硬盘加载。我们做RVT,这里其实是实时创建。为了流程描述统一特意说成加载。这种实时创建有2种方式,第一种是放个相机去拍,这种简单也能对格子贴花、路面等自动支持,但是性能不好。因为渲染流程要走一遍。相机要对地形Mesh各种处理,这些都是我们不需要的。所以我这里采用性能更高的Blit方式,缺点是做路面与贴花时需要再开发功能支持。
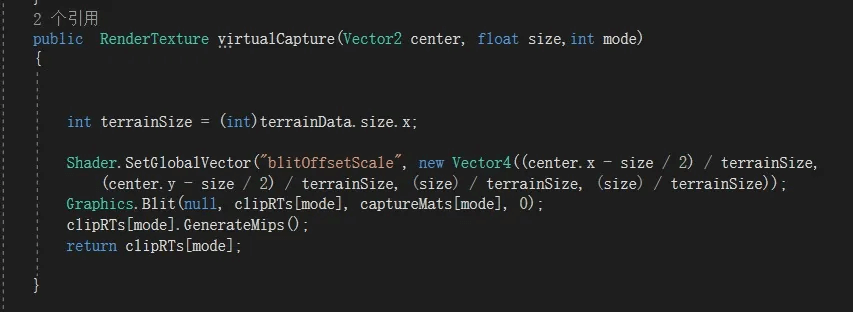
实时生成地块内容
本来直接用地形Shader改改就行,但是他是每4张一个Pass,需要Blit好多次,关键是还要对这些结果做混合,像素拷贝太多了,所以这里改了下,用Texture2DArray存放地形地表纹理比如16张。一次性采样完。因为要输出Albedo和Normal2份数据,所以这里给了开关,如果要一次获得可尝试MRT,但我这里不想再展开。利用Builtin自带地形Shader的Firstpass,一次性采样完所有图层。
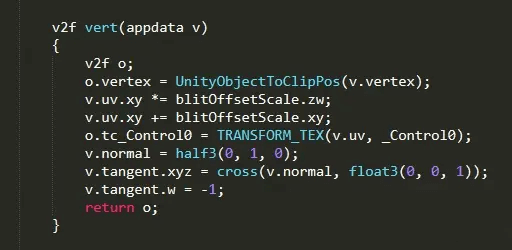
根据地块位置不同、尺寸不同,做偏移和缩放

制作节点对应贴图的Shader
索引贴图
四叉树节点上对应的贴图创建好了,但是渲染的时候,一个ShadingPoint怎么知道自己要采样第几张图的呢?根据自己的世界坐标或地形UV来查询四叉树?这肯定是不好的复杂又过度采样。所以都是给他制作一张索引图,和他UV一一对应,他根据地形UV就能访问到对应的纹素,比如Frag函数里一个ShadingPoint,他在地形上UV是(0.5,0.5),那么他去索引图的(0.5,0.5)采样就可以获得节点数据,包含了索引、尺寸和起始的xz4个值。然后就可以计算出在Texture2DArray里的UV坐标和Index。
但是这个索引如果是均匀的,其单位是多少呢?比如这里我们四叉树最小一格Size是1(世界坐标先当1米用)。那么这个索引图就是1个纹素对应1米。四叉树节点加载好贴图放入Texture2DArray后 ,就要填充索引图对应纹素的内容,好让采样的Shader能查询正确。如果这个节点Size是1当然就填1x1纹素,如果是4x4的Size就覆盖了4x4米,当然索引图需要填充4x4纹素同样的值。这样看起来有点傻,第1,浪费空间;第2,写入数据也变多;第3,采样时候采样了不是同一位置的同一个值结果正确但缓存命中变差。所以有同事建议根据FARCRY5那套把2x2的写到Mipmap1的一个像素,把4x4写到Mipmap2的一个像素。看上去很美好实际上不行,因为我这方案省略了Feedback这一整个过程,所以CPU根据距离计算出的Mipmaps与渲染时Fragment里计算的会不一致,这样导致他去索引贴图某Mipmap取值时,内容是错误的,因为写入的是另一个Mipmap,而只有获取到正确内容后 才知道CPU计算这处的LOD是多少,也才知道他写入了哪个Mipmap。这里使用ComputeShader填充索引贴图内容。就一句代码:
Result[id.xy+ uint2(offsetX, offsetZ)] = value;
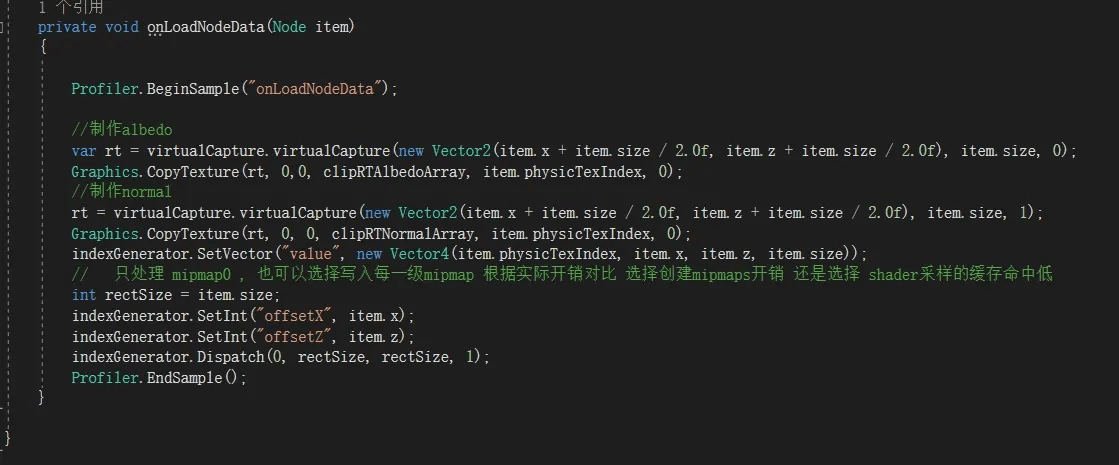
制作数据放入数组并填充索引贴图内容

斜面噪点

噪点对比
按这样实现出来,会发现斜面有噪点,这是必然的。因为我们是根据距离指定的LOD,也就相当于贴图的Mipmap。而实际渲染是根据ddx和ddy来计算Mipmap的。也就是说法线与视角方向接近垂直的面,他们即便离的近,也不能用mipmap0的,因为2个屏幕像素在贴图空间跨了好几个纹素。所以需要给他准备多份Mipmap数据,但是最清晰的那个就是我们现在给的,所以严格来说,如果我们要传给他mipmap4,但他最后一级到mipmap8,我们需要把4、5、6、7、8都传给他。但实际上不会这么极端。所以我经过实践发现给4个足够用了。所以我们这样修改代码和Shader,我们需要在Shader内手动计算Mipmap并与CPU计算的Mipmap(也就是节点的Size大小做差值,因为用一个同尺寸贴图渲染一个更大Size范围,等于已经做了Mipmap变化)这个算法我自己想的。
传4个Mipmap用于不同角度的不同需求
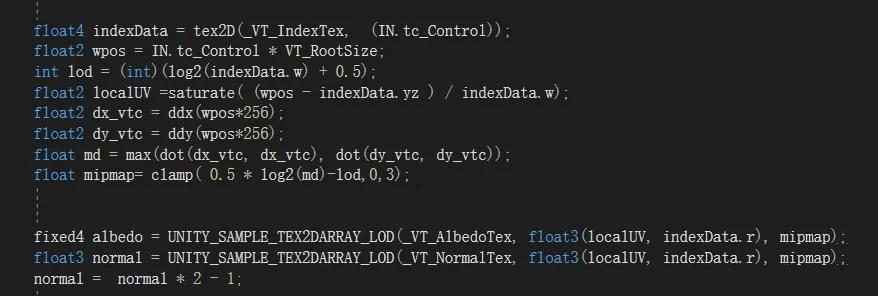
修正Mipmap问题的Shader采样

修正Mipmap计算后不会特别锐化
这样看起来效果就好多了,但是ddx和ddy一定要用均匀的地形UV来做,如果用数组内UV会有接缝,这是因为相邻节点衔接处textureArray内UV一个是0一个是1,ddx/ddy就会误认为是不连续的变化。
MRT升级
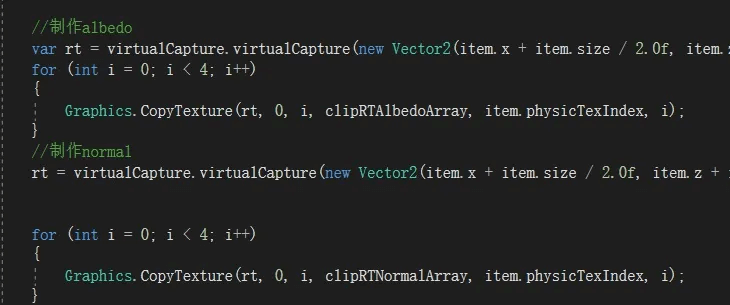
为了做贴花和道理渲染准备,已经升级到MRT渲染方式,从0.2(2次0.1)ms优化到0.14ms。其中ComputeShader开销较大是测试问题,反复加载最远处图来测试,实际上远处图变化频率很低。

原来2次DrawQuad
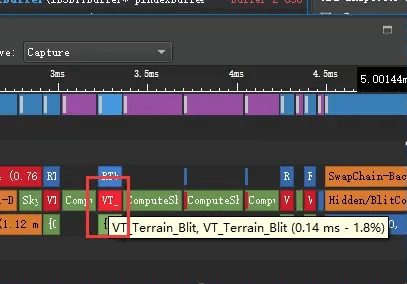
MRT1次DrawQuad
Git库地址:
GitHub - jackie2009/unityRVTTerrain: a runtime virtural texture terrain for unity 5.6
这是侑虎科技第1551篇文章,感谢作者jackie 偶尔不帅供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)
作者主页:https://www.zhihu.com/people/jackie-93-85-85
再次感谢jackie 偶尔不帅的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:465082844)