
从DX角度看SRP Batcher
- 作者:admin
- /
- 时间:2022年06月01日
- /
- 浏览:3056 次
- /
- 分类:厚积薄发
最近研究了Unity的SRP Batcher,根据官方文档说法能极大降低DrawCall代价,从而达到提升性能的目的,而且这个行为大多数情况下对于使用者是透明的。正好对这块比较感兴趣,就抓了帧稍微研究了下他的原理。
官方解释原理及应用
SRP Batcher: Speed up your rendering!里的解释原理比较清楚:早期Unity每次Draw之前需要大量准备工作:
Unity historically was made for non-constant buffers, supporting Graphics APIs such as DirectX9. However, such nice features have some drawbacks. For example, there is a lot of work to do when a DrawCall is using a new Material. So basically, the more Materials you have in a Scene, the more CPU will be required to setup GPU data.
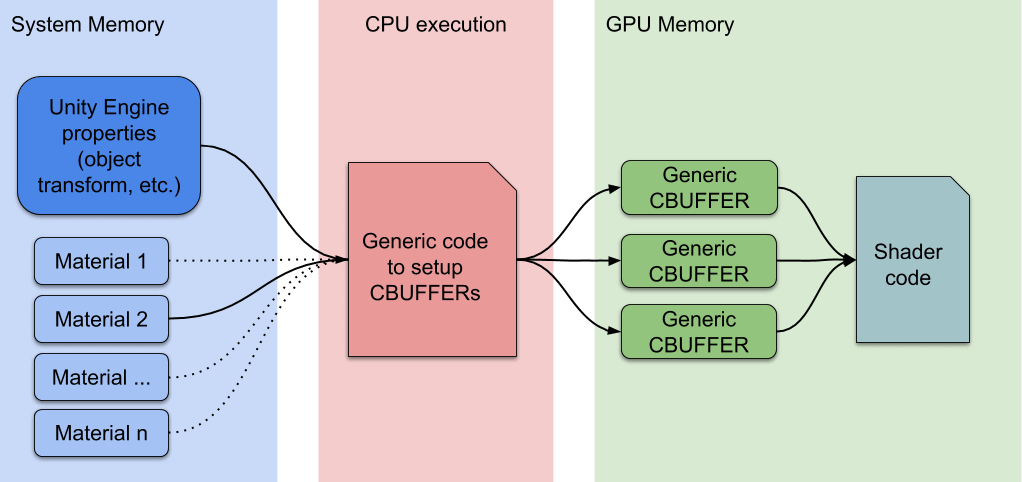
而使用SRP Batcher之后能尽可能地减少这些准备工作(不变的数据是不用每次从CPU刷到GPU的):
Now, low-level render loops can make material data persistent in the GPU memory. If the Material content does not change, there is no need to set up and upload the buffer to the GPU. Plus, we use a dedicated code path to quickly update Built-in engine properties in a large GPU buffer. Now the new flow chart looks like:
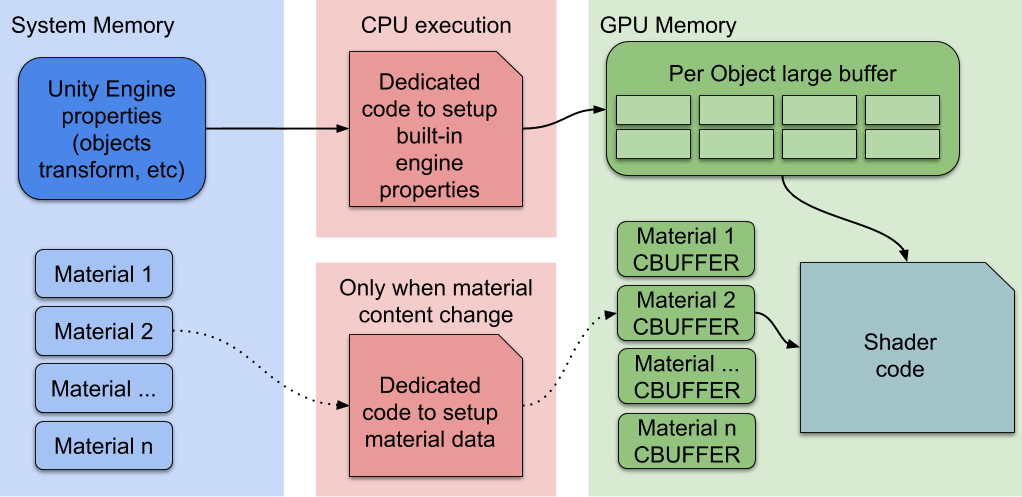
从SRP Batcher实现原理来说,其实就会比原来的方案多出一些限制(这个在后面抓帧的时候其实可以反向验证):
- 不支持粒子,必须有Mesh或者Skinned Mesh
- 不支持MaterialPropertyBlocks
- Shader必须保证所有的参数被包含在UnityPerDraw或者UnityPerMaterial里
本地抓帧测试
官方提供了一个测试工程SRPBatcherBenchmark,就不用自己构造测试场景了;在PC上简单测试了下,开SRP Batcher时3.6ms左右,关SRP Batcher 17.9ms左右(仅考虑CPU Rendering time),确实效果明显。
抓了两帧先简单对比一下:从EID个数来看少了接近一半的DX API调用,而且比较有意思的是SRP Batcher里就算单个物体也是走的Instance Draw。
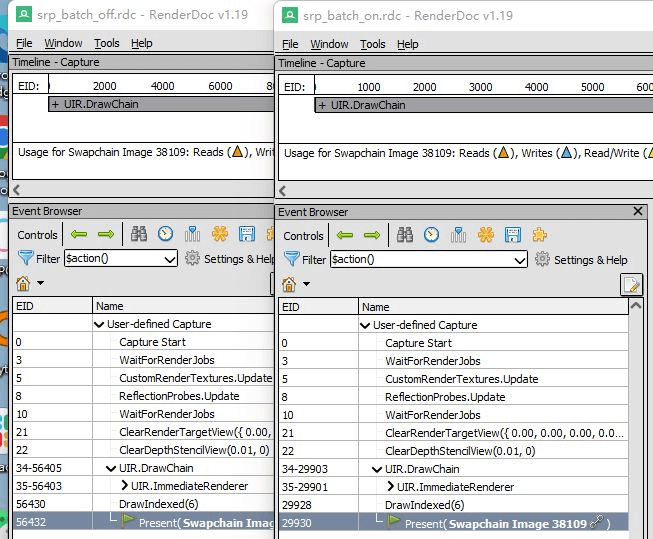
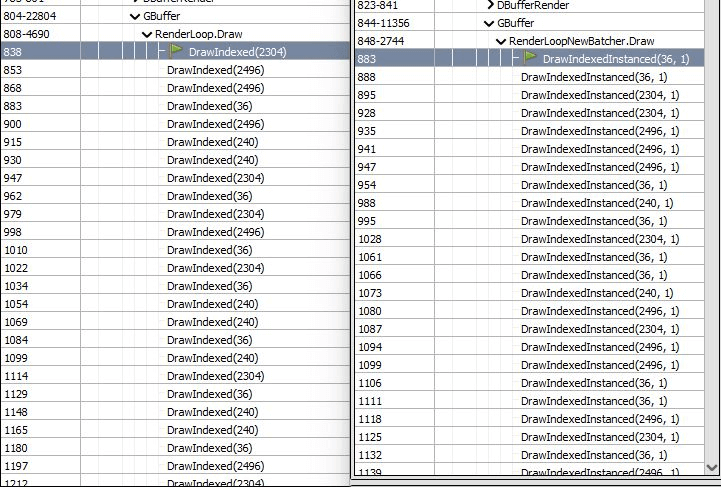
具体看下关闭和打开SRP Batcher情况下同一个物体绘制的对比(主要看左下角的API Inspector):
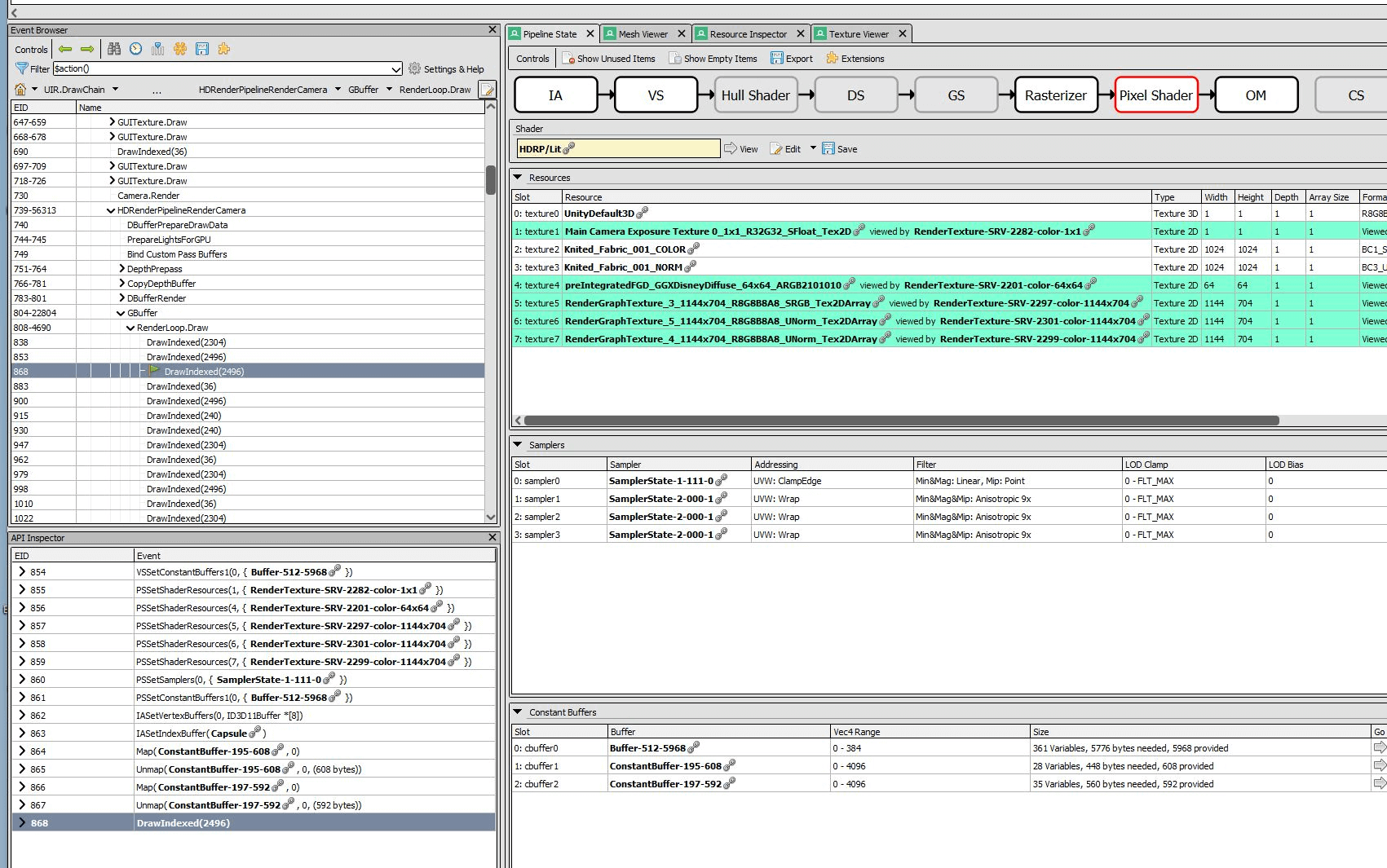
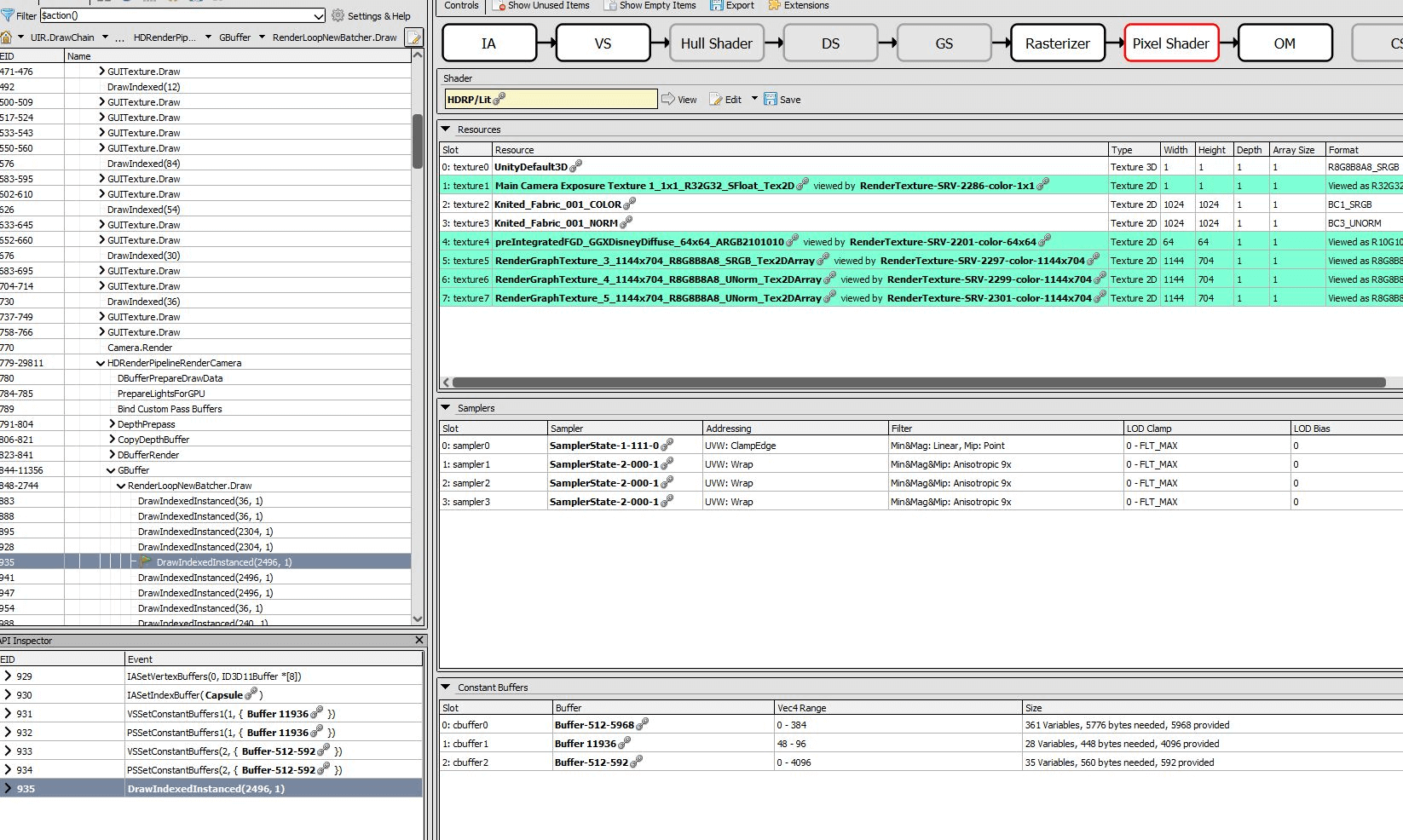
可以得到一些进一步的结论:
- 对于不变的Texture/Sampler,在关闭SRP Batcher下是每个Draw都暴力设置的(相当于大量的重复调用),在打开SRP Batacher时就不需要。
- 在关闭SRP Batcher的情况下,cbuffer0/1/2每次都设置,同时cbuffer1/2每次都Map/Unmap更新数据;在打开SRP Batcher的情况下,cbuffer0始终不变,cbuffer2一般不变,cbuffer1只变Range。
- 后来打开Shader Debug信息看了下,cbuffer0对应ShaderVariablesGlobal,cbuffer1对应UnityPerDraw,cbuffer2对应UnityPerMaterial。
以之前的经验来说,优化Redundant Call的效果一般来说看不太出来(像XCode的Frame Capture里Insights专门会提示这些Issue,我之前改了一波发现FPS毫无变化); 但是对于buffer的优化确实效果很好。这里其实也反过来验证了几个前面提到的点:
- 如果Shader里的参数有不出现在UnityPerDraw或UnityPerMaterial的,就没法走SRPBatcher。
- ShaderVariablesGlobal一帧刷一次即可,UnityPerMaterial对于相同材质是完全不需要变的,UnityPerDraw其实就是一个4096大小的Transient Buffer反复使用(初始概念还是来自龚大的《高效GPU Buffer管理之Transient Buffer》)。
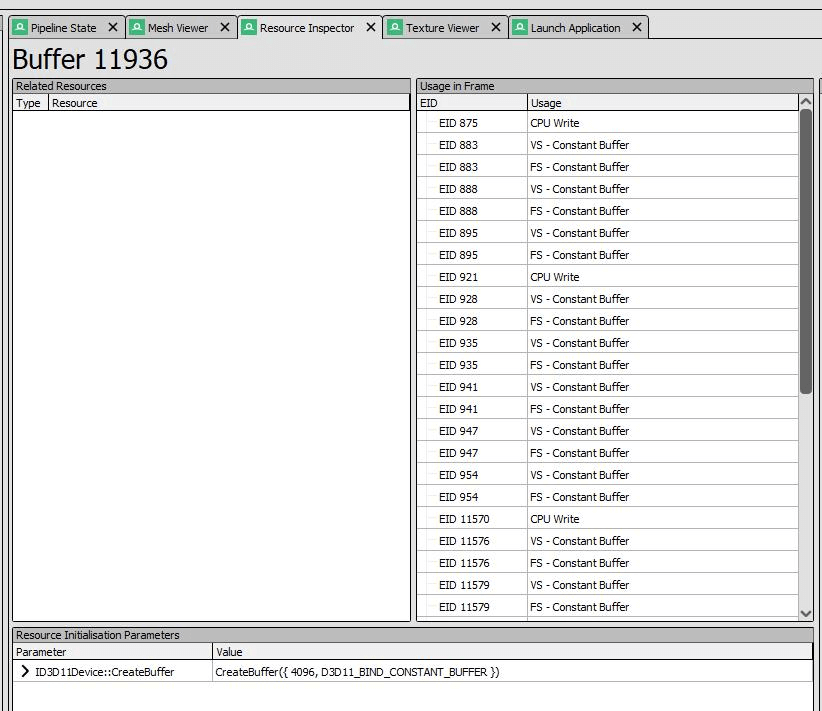
当然文档也说了收集引擎属性的Code Path也做了特化提升,不过由于没有代码就不知道到底影响有多大了,略过不谈。
延展思考
重新反思下问题,降低CPU提交代价的常见套路不外乎几个:
尽量降低DrawCall数量,如LOD、Frustrum Culling、GPU Culling和PVS等手段。
合并DrawCall,常见的就是Draw Instanced,但是限制点在于相同的Mesh及Material 2.1 更进一步Indirect Draw,可以解开相同Mesh的限制,但是相同Material无法规避。
如果DrawCall无法降低,那么就尽量降低其代价,这也是很多现代API演进的思路。
SRP Batcher其实就是属于第三个范畴里的工作。
这是侑虎科技第1152篇文章,感谢作者钱康来供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
再次感谢钱康来的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
