
Unity移动端游戏性能优化简谱之 以模块思维划分的CPU耗时调优(下)
- 作者:admin
- /
- 时间:3月24日
- /
- 浏览:1098 次
- /
- 分类:厚积薄发
《Unity移动端游戏性能优化简谱》从Unity移动端游戏优化的一些基础讨论出发,例举和分析了近几年基于Unity开发的移动端游戏项目中最为常见的部分性能问题,并展示了如何使用UWA的性能检测工具确定和解决这些问题。内容包括了性能优化的基本逻辑、UWA性能检测工具和常见性能问题,希望能提供给Unity开发者更多高效的研发方法和实战经验。
今天向大家介绍文章第三部分:以引擎模块为划分的CPU耗时调优,共10小节,包含了渲染模块、UI模块、物理模块、动画模块、粒子系统、加载模块、逻辑代码、Lua等多个模块等常见的游戏CPU耗时调优讲解。
本章包含6-10小节,1-5小节请点击《Unity移动端游戏性能优化简谱之 以模块思维划分的CPU耗时调优(上)》。
(全文长约14115字,预计阅读时间约30分钟)
文章第一部分《Unity移动端游戏性能优化简谱之 前言》、第二部分《Unity移动端游戏性能优化简谱之 分门别类地控制运行时内存(上)》、《Unity移动端游戏性能优化简谱之 分门别类地控制运行时内存(下)》可戳此回顾,完整内容可前往UWA学堂查看。
6. 粒子系统
围绕粒子系统相关优化更全面的内容可以参考《粒子系统优化——如何优化你的技能特效》。
6.1 Playing粒子系统数量
UWA统计了粒子系统数量和Playing状态的粒子系统数量。前者是指内存中所有的ParticleSystem的总数量,包含正在播放的和处于缓存池中的;后者指的是正在播放的ParticleSystem组件的数量,这个包含了屏幕内和屏幕外的,我们建议在一帧中出现的数量峰值不超过50(1GB机型)。
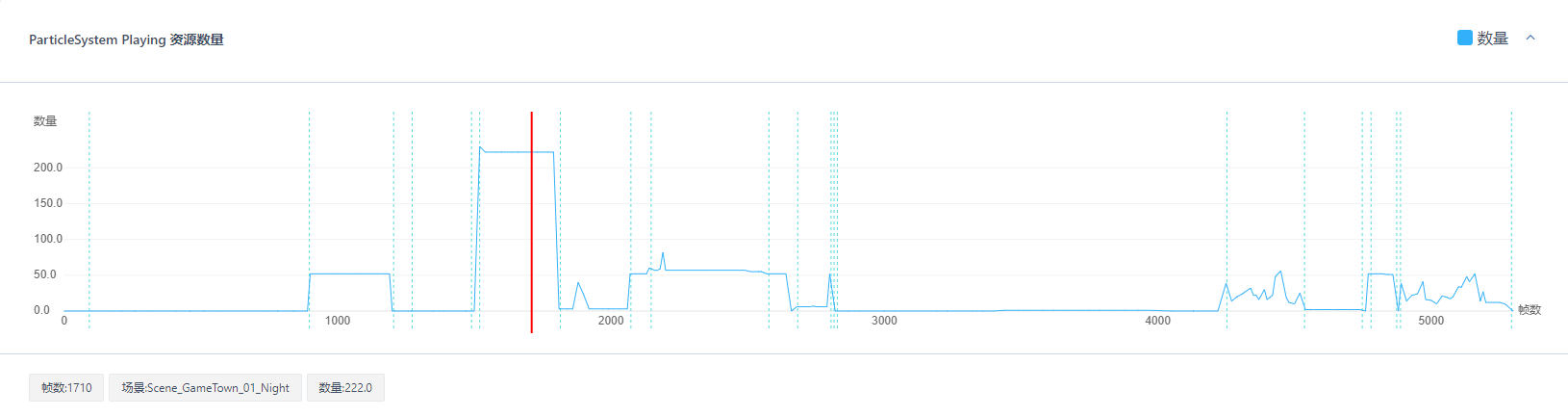
针对这两个数值,我们一方面关注粒子系统数量峰值是否偏高,可选中某一峰值帧查看到底是哪些粒子系统缓存着、是否都合理、是否有过度缓存的现象;另一方面关注Playing数量峰值是否偏高,可选中某一峰值帧查看到底是哪些粒子系统在播放、是否都合理。
前文提到的控制同种粒子数量上限也是常见方案。
分级策略也是粒子系统优化过程中必不可少的手段。比如对于一个有12345,五种子粒子的火焰特效Prefab,其中345可能是美术同学用来做火焰燃烧时飞溅的火星、飘散的烟尘、空气的波动的,只有12是火焰本体。则低端机上应该考虑只保留12。
虽然我们在讨论粒子系统对耗时的影响时,多数时候还是在讨论粒子系统的渲染开销,无论是CPU端还是GPU端的。但对于粒子系统使用非常重度、数量非常多的项目来说,Playing的粒子过多也会对其本身在CPU端进行更新计算的ParticleSystem.Update()耗时有所影响。
6.2 Culling Mode
为粒子系统设置合理的Culling Mode也是一种有效降低粒子系统CPU端更新耗时的方式。
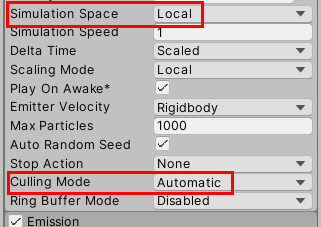
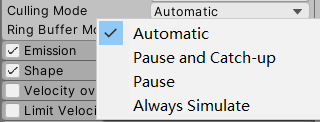
相关的关键设置为如上图的Simulation Space和Culling Mode。
其中,Simulation Space可选项有Local,World,Custom;CullingMode可选项为Automatic,Pause And Catch-up,Pause,Always Simulate。通常创建的粒子系统的默认选项是Local和Automatic。
我们显然希望当粒子在屏幕外看不到时停止相关运算、减少其耗时开销。因此我们测试在不同设置组合下粒子系统在屏幕外时的ParticleSystem.Update()函数耗时,结果如下:
- 在Local模式下,只有Culling Mode为Always Simulate有例子更新耗时(没有开启额外的Module)。
- 在Local模式下,如果粒子系统开启了Collision等Module,那么Culling Mode为Automatic时也会产生耗时。
- 在Local模式下,如果是Culling Mode为Pause或者Pause and Catch-up,就算有Collision Module也没有耗时。
- 在World模式下,Culling Mode为Automatic也会有耗时(没有开启额外的Module)。
- 在World模式下,Culling Mode为Pause,就算有Collision,也没有耗时。
综上,我们可以看到Culling Mode的设置对不同设置的粒子系统开销的限制能力是合理递进的,这说明我们在设置粒子系统时应尽量至少设为Automatic;应慎用Simulation Space为World的粒子;应慎用Collision、Trigger、Noise、Trails这些颇为常见的Module;对于确实要使用Module的粒子,也应考虑进一步调整设置为Pause等以节省耗时。
6.3 Prewarm
ParticleSystem.Prewarm作为粒子系统的核心初始化选项,其设计初衷是为了让粒子系统在实例化或从Deactive状态激活时,立即完成一次完整的生命周期模拟,使粒子效果从激活瞬间就呈现出“已运行一段时间”的成熟状态(例如持续燃烧的火焰、循环播放的光晕等),避免出现“从无到有”的突兀感。但该机制在带来表现优势的同时,也隐藏着显著的性能风险——尤其在粒子系统数量较多、效果复杂的场景中,Prewarm触发的瞬时计算开销可能成为CPU耗时峰值的主要诱因,甚至引发卡顿。
主要优化手段如下:
- 优化粒子系统本身的复杂度,通过降低Prewarm触发时的计算量,从源头减少耗时:
- 规避集中触发Prewarm的场景,当多个带Prewarm的粒子系统需要激活时,通过分帧激活、延迟激活、或缓存复用的方式分散计算压力。
7. 加载模块
围绕加载模块相关优化更全面的内容可以参考《Unity性能优化系列—加载与资源管理》。
7.1 Shader加载
(1)Shader.Parse
Shader.Parse是指Shader加载进行解析的操作,如果此操作较为频繁,通常是由于Shader的重复加载导致的,这里的重复可以理解为2层意思。
第一层是由于Shader的冗余导致的,通常是因为打包AssetBundle的时候,Shader被被动打进了多个不同的AssetBundle中而没有进行依赖打包,这样当这些AssetBundle中的资源进行加载的时候,会被动加载这些Shader,就进行了多次“重复的”Shader.Parse,所以同一种Shader就在内存中有多份了,这就是冗余了。
要去除这种冗余的方法也很简单,就是把这些会冗余的Shader依赖打包进一个公共的AssetBundle包。这样就会主动打包了,而不是被动进入某些使用了这个Shader的包体中。如果对这个Shader进行了主动打包,那么其它使用了这个Shader的AssetBundle中就只会对这个Shader打出来的公共AssetBundle进行引用,这样在内存中就只有一份Shader,其它用到这个Shader的时候就直接引用它,而不需要多次进行Shader.Parse了。
第二层意思是同一个Shader多次地加载卸载,没有缓存住导致的。假设AssetBundle进行了主动打包,生成了公共的AssetBundle,这样在内存中只有这一份Shader,但是因为这个Shader加载完后(也就是Shader.Parse)没有进行缓存,用完马上被卸载了。下次再用到这个Shader的时候,内存里没有这个Shader了,那就必须再重新加载进来,这样同样的一个Shader加载解析了多次,就造成了多次的Shader.Parse。一般而言,经过变体优化以后的开发者自己写的Shader内存占用都不高,可以统一在游戏开始时加载并缓存。
特别地,对于Unity内置的Shader,只要是变体数量不多的,可以放进Project Settings中的Always Included中去,从而避免这一类Shader的冗余和重复解析。
(2)Shader.CreateGPUProgram
该API也会在加载模块主函数甚至UI模块、逻辑代码的堆栈中出现。相关的讨论上文已经涉及,优化方法相同,不再赘述。
7.2 Resources.UnloadUnusedAssets
该API会在场景切换时被Unity自动调用,一般单次调用耗时较高,通常情况下不建议手动调用。
但在部分不进行场景切换或用Additive加载场景的项目中,不会调用该API,从而使得项目整体资源数量和内存有上升趋势。对于这种情况则可以考虑每5-10min手动调用一次。
Resources.UnloadUnusedAssets的底层运作机理是,对于每个资源,遍历所有Hierarchy Tree中的GameObject结点,以及堆内存中的对象,检测该资源是否被某个GameObject或对象(组件)所使用,如果全部都没有使用,则引擎才会认定其为Unused资源,进而进行卸载操作。简单来讲,Resources.UnloadUnusedAssets的单次耗时大致随着((GameObject数量+Mono对象数量)*Asset数量)的乘积变大而变大。
因此,该过程极为耗时,并且场景中GameObject/Asset数量越高,堆内存中的对象数越高,其开销也就越大。对此,我们的建议如下:
(1)Resources.UnloadAsset/AssetBundle.Unload(True)
研发团队可尝试在游戏运行时,通过Resources.UnloadAsset/AssetBundle.Unload(True)来去除已经确定不再使用的某一资源,这两个API的效率很高,同时也可以降低Resources.UnloadUnusedAssets统一处理时的压力,进而减少切换场景时该API的耗时。
(2)严格控制场景中材质资源和粒子系统的使用数量
专门提到这两种资源,因为在大多数项目中,虽然它们的内存占用一般不是大头,但往往资源数量远高于其他类型的资源,很容易达到数千的数量级,从而对单次Resources.UnloadUnusedAssets耗时有较大贡献。
(3)降低驻留的堆内存
堆内存中的对象数量同样会显著影响Resources.UnloadUnusedAssets的耗时,这在上文也已经讨论过。
7.3 加载AssetBundle
使用AssetBundle加载资源是目前移动端项目中比较普遍的做法。
而其中,应尽量用LZ4压缩格式打包AssetBundle,并用LoadFromFile的方式加载。经测试,这种组合下即便是较大的AssetBundle包(包含10张1024*1024的纹理),其加载耗时也仅零点几毫秒。而使用其他加载方式,如LoadFromMemory,加载耗时则上升到了数十毫秒;而使用WebRequest加载则会造成AssetBundle包的驻留内存显著上升。
这是因为,LoadFromFile是一种高效的API,用于从本地存储(如硬盘或SD卡)加载未压缩或LZ4压缩格式的AssetBundle。
在桌面独立平台、控制台和移动平台上,API将只加载AssetBundle的头部,并将剩余的数据留在磁盘上。AssetBundle的Objects会按需加载,比如:加载方法(例如:AssetBundle.Load)被调用或其InstanceID被间接引用的时候。在这种情况下,不会消耗过多的内存。
但在Editor环境下,API还是会把整个AssetBundle加载到内存中,就像读取磁盘上的字节和使用AssetBundle.LoadFromMemoryAsync一样。如果在Editor中对项目进行了分析,此API可能会导致在AssetBundle加载期间出现内存尖峰。但这不应影响设备上的性能,在做优化之前,这些尖峰应该在设备上重新再测试一遍。
要注意,这个API只针对未压缩或LZ4压缩格式,因为如果使用LZMA压缩,它是针对整个生成后的数据包进行压缩的,所以在未解压之前是无法拿到AssetBundle的头信息的。
由于LoadFromMemory的加载效率相较其他的接口而言,耗时明显增大,因此我们不建议大规模使用,而且堆内存会变大。如果确实有对AssetBundle文件加密的需求,可以考虑仅对重要的配置文件、代码等进行加密,对纹理、网格等资源文件则无需进行加密。因为目前市面上已经存在一些工具可以从更底层的方式来获取和导出渲染相关的资源,如纹理、网格等,因此,对于这部分的资源加密并不是十分的必要性。
在UWA GOT Online Resource模式下的资源管理页面中可以排查加载耗时较高的AssetBundle,从而排查和优化加载方式、压缩格式、包体过大等问题,或者对反复加载的AssetBundle考虑予以缓存。
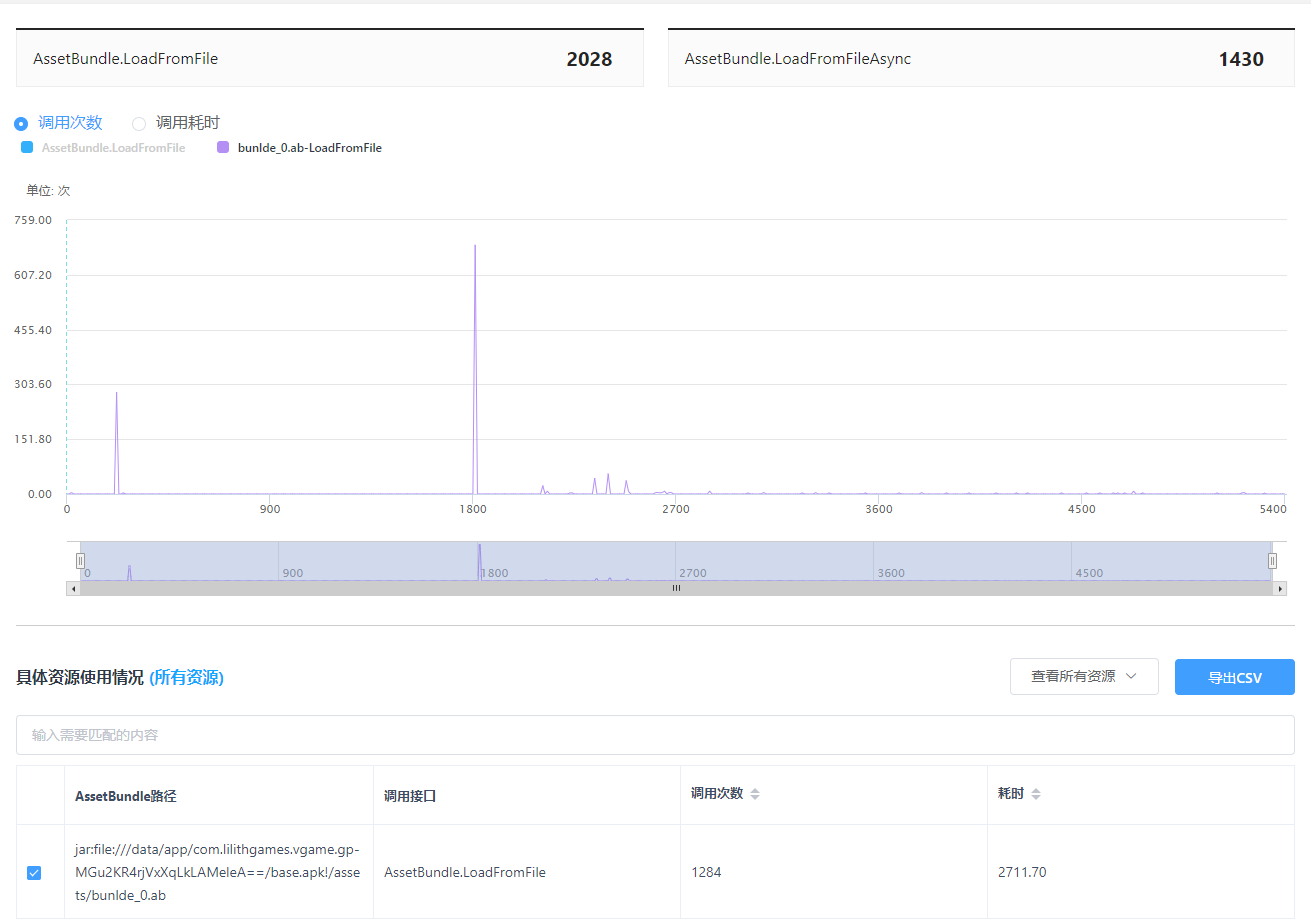
7.4 加载资源
有关加载资源所造成的耗时,若加载策略比较合理,则一般发生在游戏一开始和场景切换时,往往不会造成严重的性能瓶颈。但不排除一些情况需要予以关注,那么可以把资源加载耗时的排序作为依据进行排查。
对于单次加载耗时过高的资源,比如达到数百毫秒甚至几秒时,就应考察这类资源是否过于复杂,从制作上考虑予以精简。
对于反复频繁加载且耗时不低的资源,则应该在第一次加载后予以缓存,避免重复加载造成的开销。
值得一提的是,在Unity的异步加载中有时会出现每帧进行加载所能占用的最高耗时被限制,但主线程中却在空转的现象。尤其是在切场景的时候集中进行异步加载,有时会耗费几十甚至数十秒的时间,但其中大部分时间是被空转浪费的。这是因为控制异步加载每帧最高耗时的API Application.backgroundLoadingPriority默认值为BelowNormal,每帧最多只加载4ms。此时一般建议把该值调为High,即最多50ms每帧。
在UWA GOT Online Resource模式下的资源管理页面中可以排查加载耗时较高的资源,从而排查和优化加载方式、资源过于复杂等问题,或者对反复加载的资源考虑予以缓存。
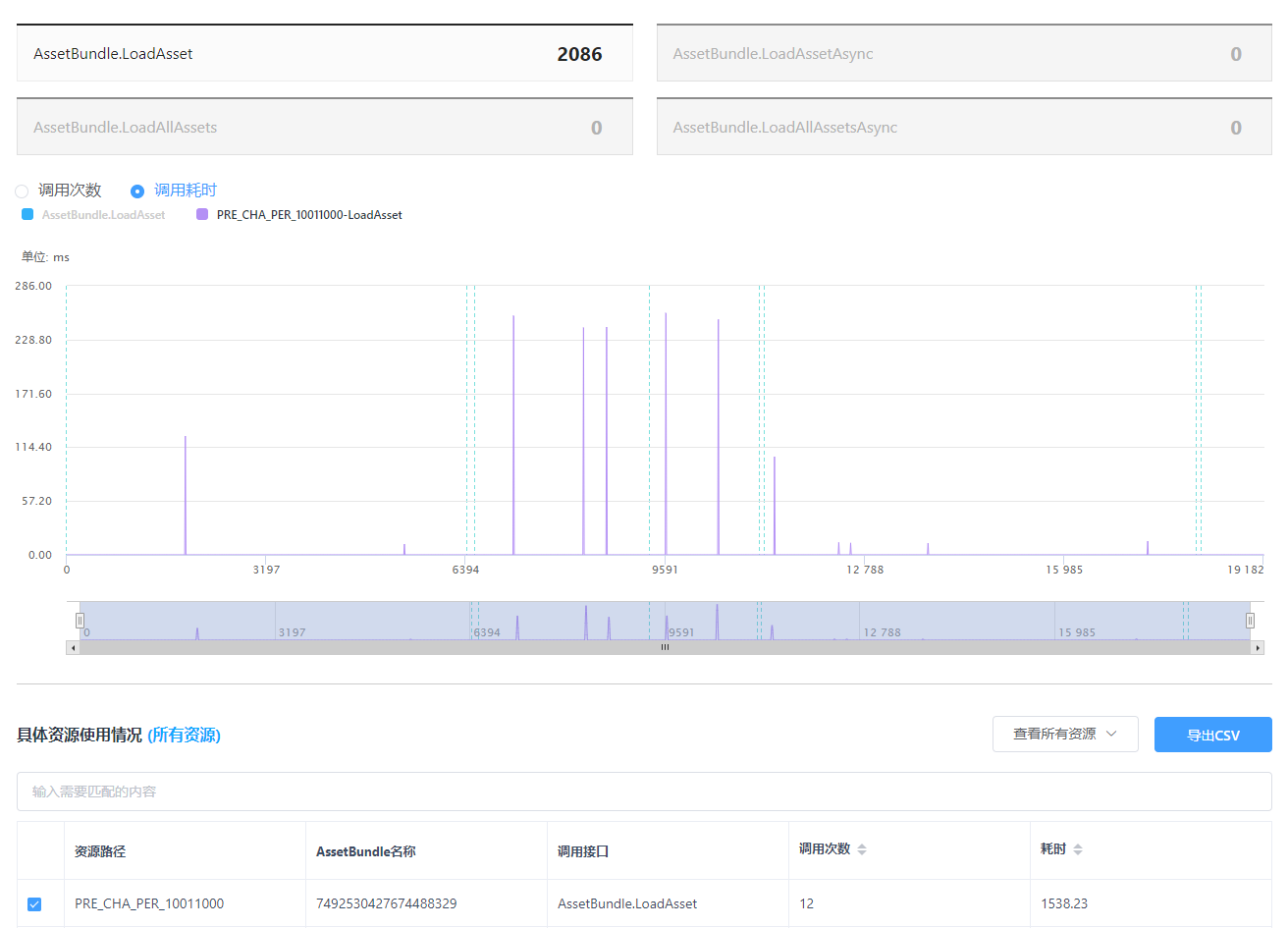
7.5 实例化和销毁
实例化同样主要存在单个资源实例化耗时过高或某个资源反复频繁实例化的现象。根据耗时多少排列后,针对疑似有问题的资源,前者考虑简化,或者可以考虑分帧操作,比如对于一个较为复杂的UI Prefab,可以考虑改为先实例化显眼的、重要的界面和按钮,而翻页后的内容、装饰图标等再进行实例化;后者则建立缓存池,使用显隐操作来代替频繁的实例化。
在UWA GOT Online Resource模式下的资源管理页面中可以排查实例化耗时较高的资源,从而排查和优化资源过于复杂的问题,或者对反复实例化的资源考虑予以缓存。
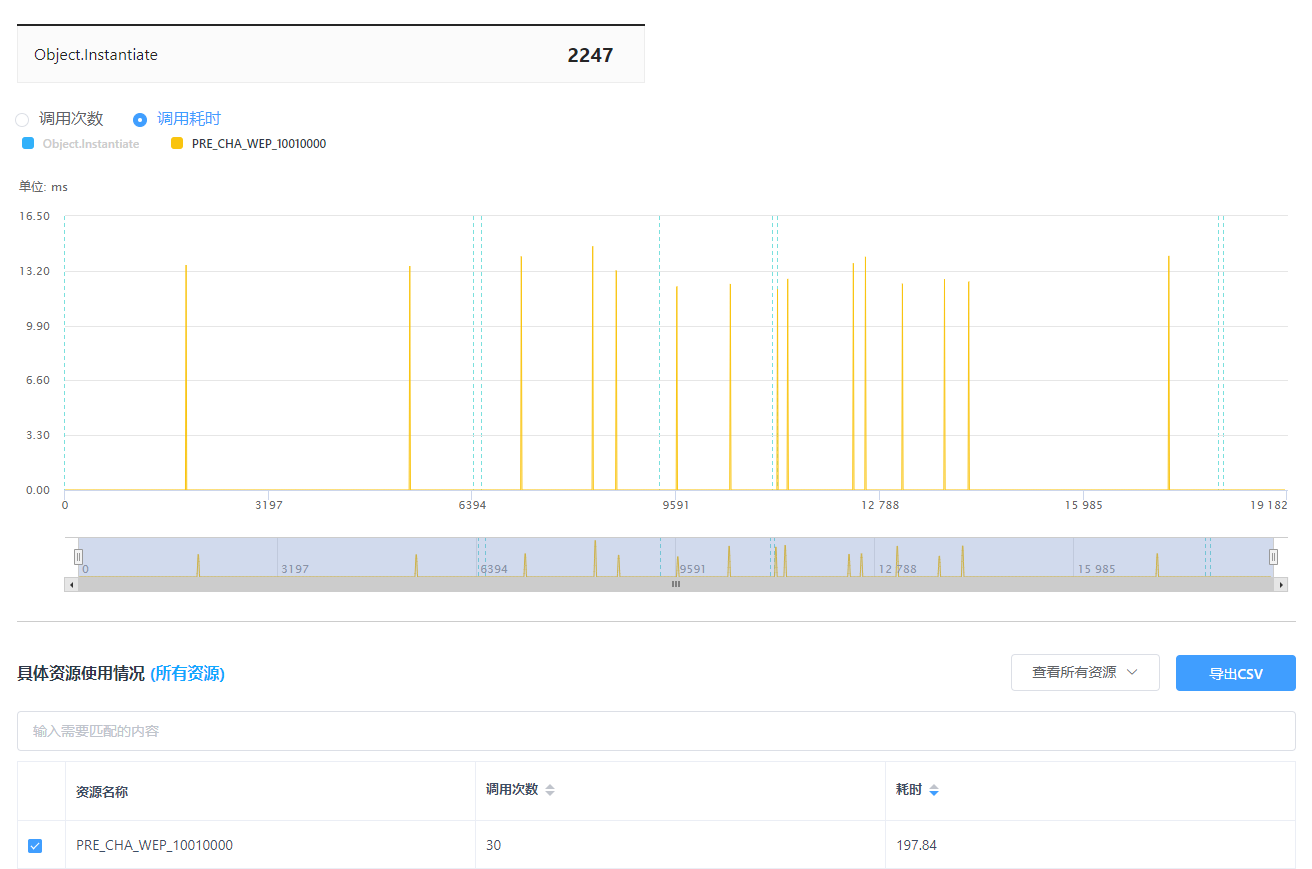
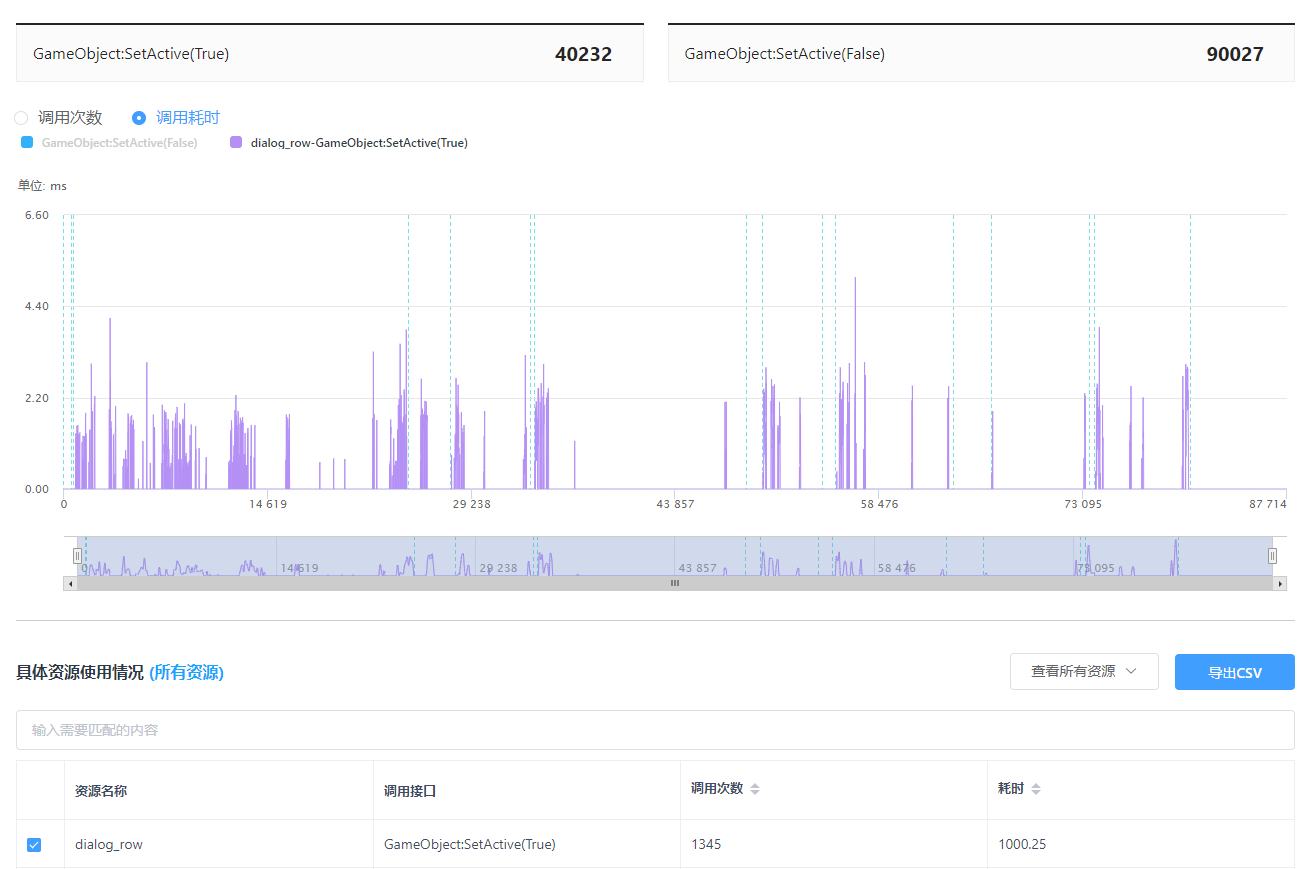
7.6 激活和隐藏
激活和隐藏的耗时本身不高,但如果单帧的操作次数过多就需要予以关注。可能出于游戏逻辑中的一些判断和条件不够合理,很多项目中往往会出现某一种资源的显隐操作次数过多,且其中SetActive(True)远比SetActive(False)次数多得多、或者反之的现象,亦即存在大量不必要的SetActive调用。由于SetActive API会产生C#和Native的跨层调用,所以一旦数量一多,其耗时仍然是很可观的。针对这种情况,除了应该检查逻辑上是否可以优化外,还可以考虑在逻辑中建立状态缓存,在调用该API之前先判断资源当前的激活状态。相当于使用逻辑的开销代替该API的开销,相对耗时更低一些。
在UWA GOT Online Resource模式下的资源管理页面中可以排查激活隐藏操作较频繁的资源,从而排查和优化相关逻辑和调用。
8. 逻辑代码
逻辑代码的CPU耗时优化更多是结合项目实际需求、考验程序员本人的过程,很难定量定性进行讨论。不过UWA SDK中提供了方便开发者在逻辑代码中进行打点的API&UWA GOT Online,从而将复杂的函数拆解开,在报告中排查堆栈耗时、更快速地验证优化效果。
我们发现有越来越的团队在使用JobSystem将主线程中的部分逻辑代码放入子线程中来进行处理,对于可以并行运算的逻辑,非常推荐将其放入到子线程中来处理,这样可以有效降低主线程CPU处理逻辑运算的压力。
9. Lua
GOT Online Lua模式提供的分析Lua造成的CPU耗时工具可视化程度高,堆栈清晰明了,还提供了实用且特色的倒序调用分析功能。以下结合一个Lua报告Demo简单介绍使用该工具分析Lua耗时的方法。
重申:Lua报告中出现的函数名称格式为:函数名称@文件名:行号。
可以通过报告提供的Lua文件名/行号/函数名来定位CPU耗时的瓶颈函数和CPU耗时峰值的具体原因。Lua函数的命名格式为X@Y:Z,其中X是其函数名,在无法获取时,X会变为默认的unknown;Y是该函数定义的文件位置;Z则是该函数被定义的行号。需要注意的是,当Lua脚本以字节码运行时,该值将始终为0,因此建议在测试时尽可能使用Lua源码来运行。
(1)正序调用分析——总表(曲线图+列表)
曲线图:
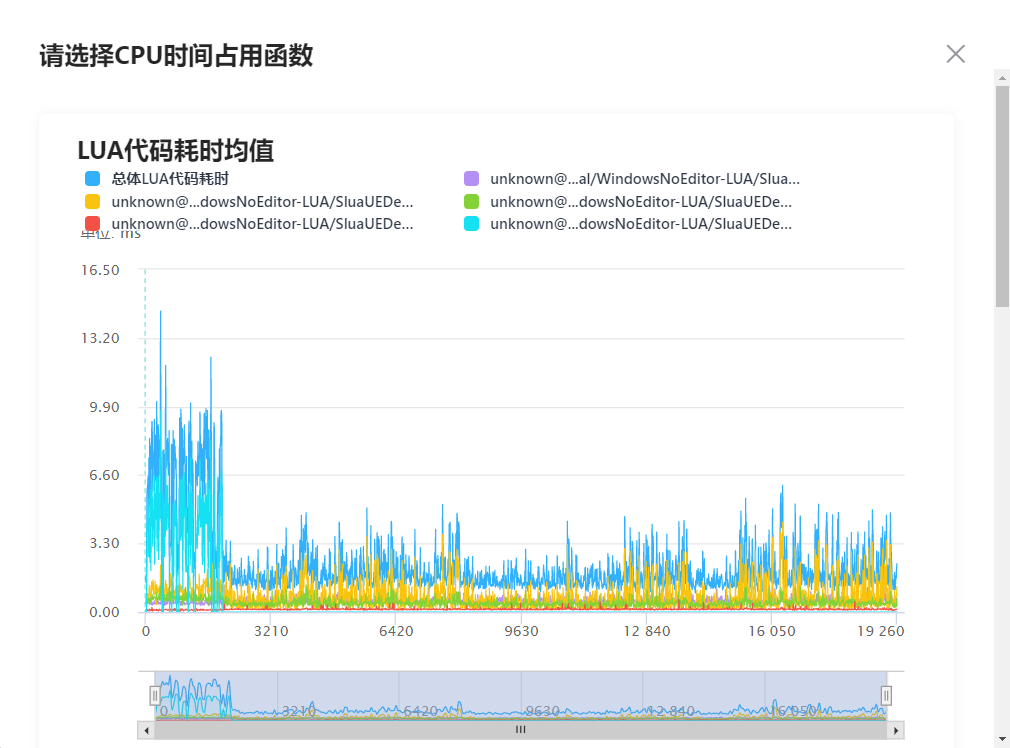
曲线选取了选取总体Lua代码耗时和按照耗时均值正向排序的前五个函数耗时组成耗时曲线图,每一个数据点代表了该函数在当前帧(横坐标)的耗时(纵坐标),有助于定位耗时瓶颈函数。
列表:
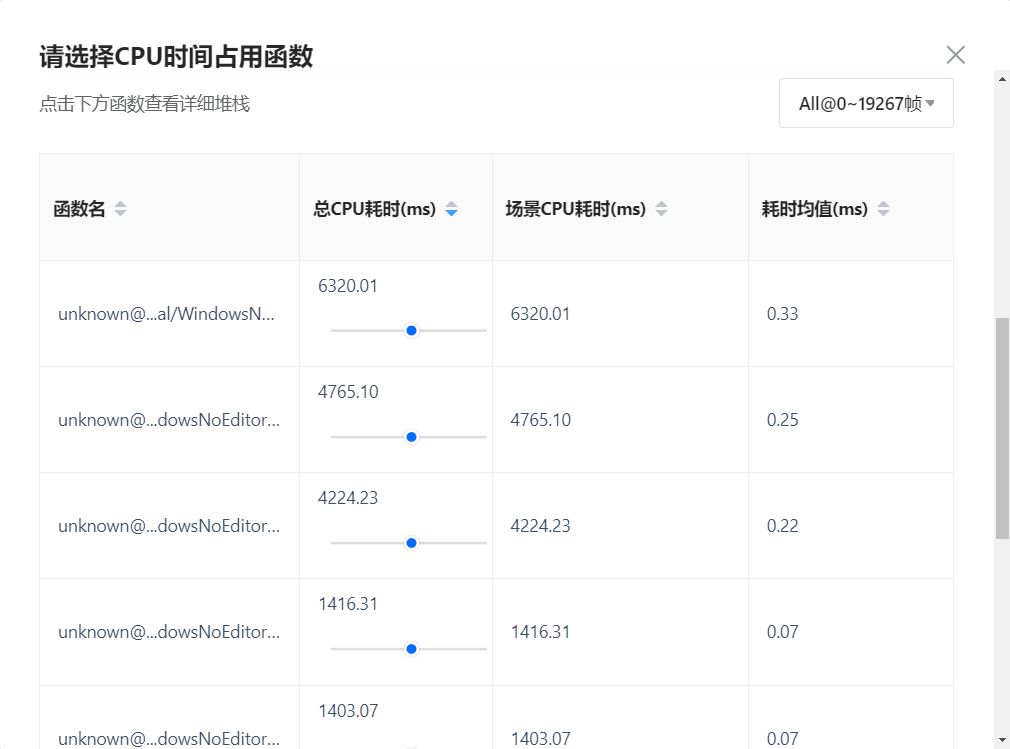
列表默认按照耗时均值从高到低对Lua函数进行了排序,粗略展示了函数名、总CPU耗时、场景CPU耗时、耗时均值等数据。通过点击函数,可以进入对应的单个函数分析页面。
(2)正序调用分析——单个函数页(截图+曲线图+堆栈信息)
截图:

项目运行时截图与使用者选中的帧大致对应,有助于定位问题。
曲线图:
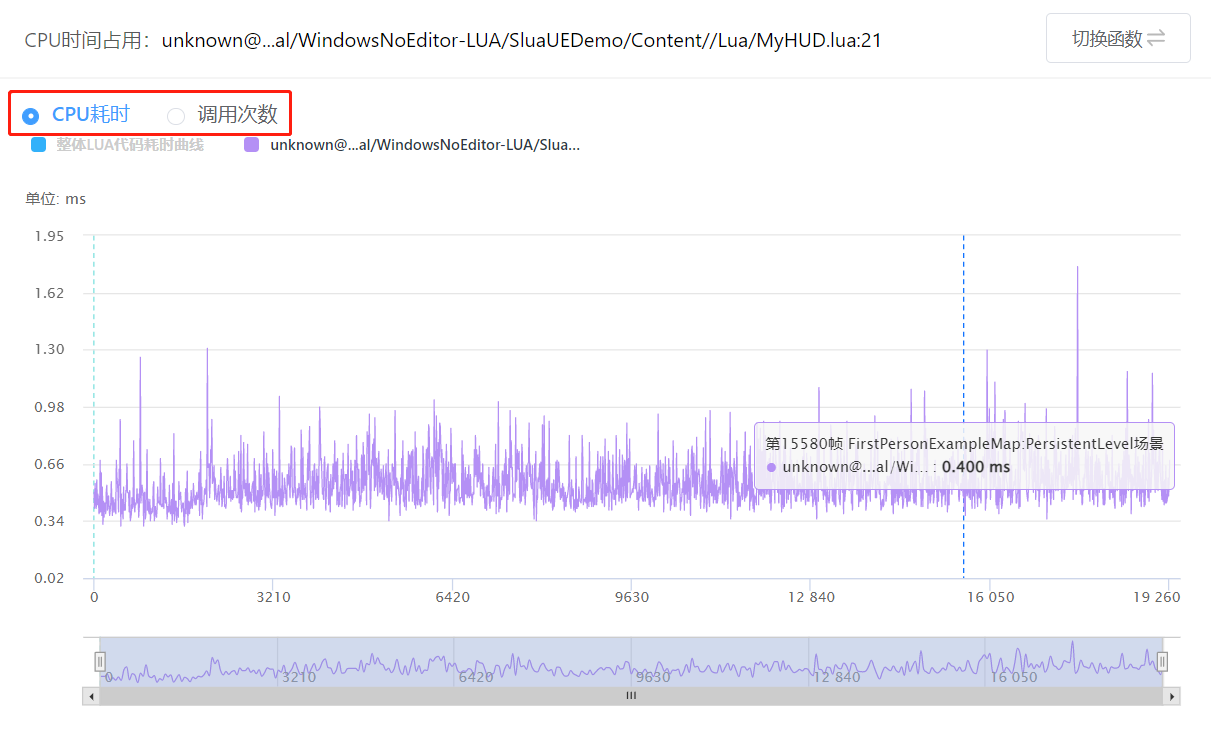
曲线图包括了CPU耗时曲线图和调用次数曲线图;也可以使用下方条缩放曲线观察局部耗时情况。
从曲线图中可以观察到:函数是否存在持续性高耗时;函数是否存在短暂的大量耗时,导致卡顿;某些函数单次耗时并不高,但因为被大量的调用,导致函数总耗时较高。
函数XXXX堆栈信息 (列表):
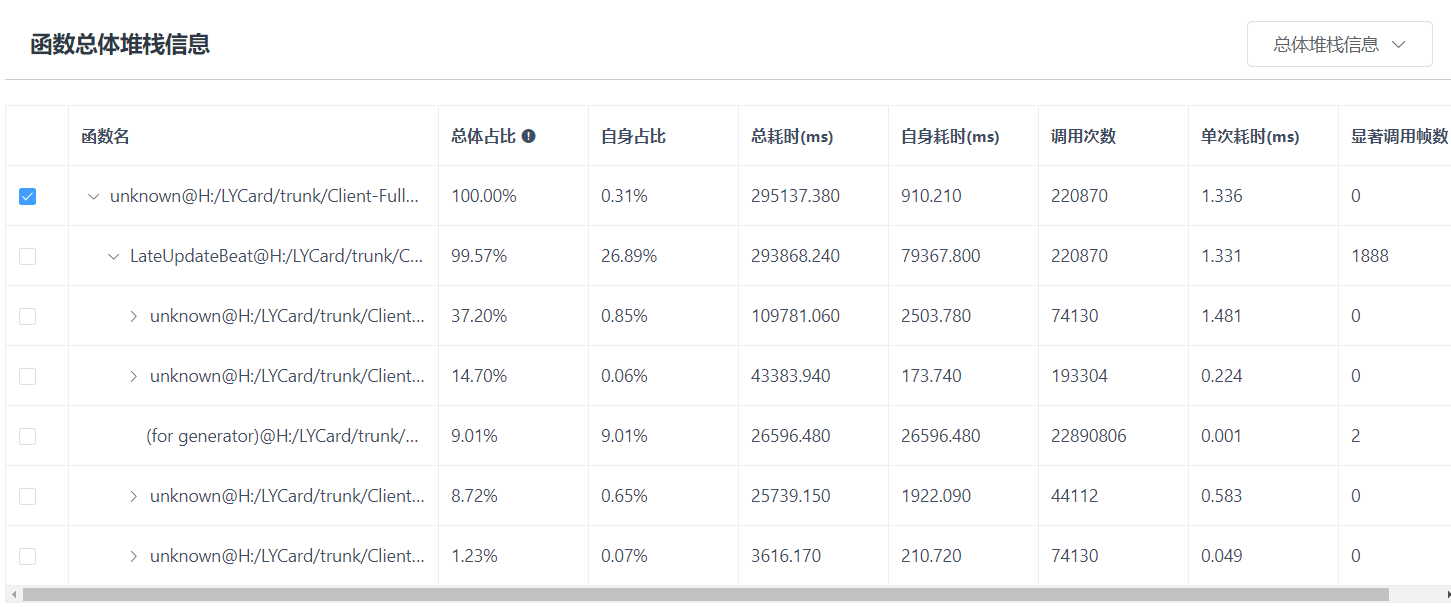
其中,可以在右上角选定列表数据的时间范围:总体堆栈信息时,时间范围为全部测试时间;指定场景堆栈信息时,时间范围为指定场景的开启时间;指定帧堆栈信息时,时间范围为当前在曲线图中选中的指定帧。
列表中各项指标含义是:总体占比,以根节点函数的总耗时为100%,当前节点函数总耗时相对根节点函数的总耗时占比;自身占比,以根节点函数的总耗时为100%,当前节点函数自身耗时相对根节点函数的总耗时占比;总耗时,时间范围内执行该函数的耗时;自身耗时,时间范围内去除子节点函数(该函数调用的函数)耗时剩余的耗时;调用次数,时间范围内该函数被调用的次数;单次耗时,总耗时/调用次数,表示每次执行该函数的平均耗时;显著调用帧数,该函数自身耗时大于3ms的帧数。
(3)倒序调用分析——总表(曲线图+列表)
曲线图:与正序调用分析不同的是,选取了自身耗时正向排序的前五个函数,每一个数据点代表了该函数在当前帧(横坐标)的自身耗时(纵坐标)。
列表:与上同理。
(4)倒序调用分析——单个函数页(截图+曲线图+堆栈信息)
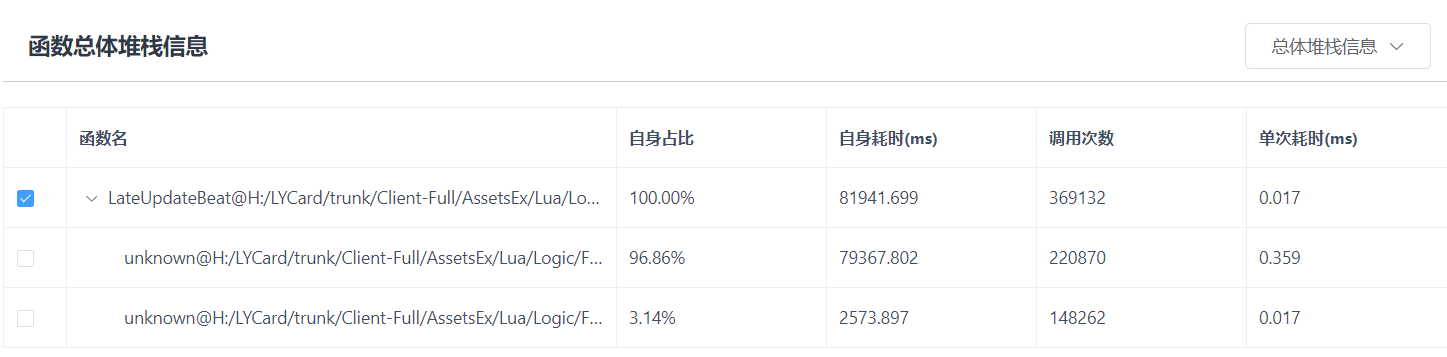
函数XXXX堆栈信息 (列表):
各项指标含义(与正序相比有所不同)变为了:自身占比,以选定函数的自身耗时总和为100%,这条调用路径下选定函数的自身耗时相对选定节点函数总自身耗时的占比;自身耗时,时间范围内,这条调用路径下,选定函数自身耗时的总和;调用次数,这条调用路径的调用次数;单次耗时,代表这条路调用路径下,选定函数的平均耗时。
在通过以上界面定位到自身耗时较高的函数后,常见的优化手段有:优化该函数的函数体,减少该函数自身的耗时;定位调用次数较多的调用路径,减少调用次数。
(5)优化建议
- 优化单次调用耗时过高的函数的函数体,减少该函数自身的耗时;
- 定位调用次数较多的调用路径,减少调用次数;
- 在高调用次数的函数中,尤其关注其中是否同时存在大量Lua和C#之间的穿梭调用,效率较低的同时可能对CPU端的能耗和发热产生大幅度贡献;
- UWA报告中的Lua函数耗时相当于在进出函数时打点,统计耗时。所以如果Lua脚本运行时调用了C#函数,这部分C#函数是会被统计进去的。
因此,需要关注和C#穿插调用的情况。对于一些反复调用同一个C#函数,或者调用多个C#函数但流程比较固定的情况,应考虑将相关逻辑移入C#层,把需要改动的参数开放。即可能需要多传几个参数,但跨语言穿梭调用的次数能够大幅降低,从而节省开销。
10. ILRuntime
ILRuntime的使用率相对低一些,但有些团队延续着之前项目的开发习惯,仍在移动端项目中大规模使用ILRuntime。但根据UWA经验,使用ILRuntime的项目无论是逻辑耗时还是堆内存相关的性能表现都较为糟糕,因此建议尽量不用或少用。在热更方案的选择上,更多项目团队都在使用的Lua,或最近使用率飙升的HybridCLR(huatuo),仅从性能层面来看也都是更好的替代方案。
以下针对已经遇到ILRuntime导致的性能问题,但短时间内无法调换方案的情况,提出一些相对有效的优化手段。
CPU层面:
- 尤其是战斗部分的逻辑尽量少用,考虑写成固定的C#代码。在ILRuntime代码中如果有大量的密集型的计算或者循环,会导致性能急速的下降。所以在ILRuntime的使用上,可以用来做一些UI的更新,在核心战斗逻辑中避免使用,需要控制力度;
- 打DLL的时候选择Release的方式;
- 对于Android平台,可以选择使用Mono的模式打包,然后使用反射的方式进行加载,这样可以做到和原生C#效率相当。
堆内存层面:
- 尽量少用,尤其是核心战斗模块,因为其对于数值类型的变量也存在装箱的问题;
- 关闭Debug的宏,可以降低堆内存的分配,在PlayerSettings中定义DISABLE_ILRUNTIME_DEBUG宏。
官方文档提供的一些优化建议可以作为进一步节省ILRuntime开销的思路:https://ourpalm.github.io/ILRuntime/public/v1/guide/FastQA.html
本文内容就介绍到这里啦,更多内容可以前往UWA学堂进行阅读。课程将从内存、CPU、GPU三个维度讨论当前游戏项目中经常出现的一些性能问题。




