
为什么GPU处理了36万,但显示只有4万
- 作者:admin
- /
- 时间:5月19日
- /
- 浏览:670 次
- /
- 分类:厚积薄发
1)为什么Mesh合得越大,GPU压力反而更大
2)Bloom和DOF,到底有多吃GPU
这是第476篇UWA技术知识分享的推送,精选了UWA社区的热门话题,涵盖了UWA问答、社区帖子等技术知识点,助力大家更全面地掌握和学习。
UWA社区主页:community.uwa4d.com
UWA QQ群:793972859
本次推送的实战案例来自于使用UWA服务的项目的真实且典型的问题。UWA将关键线索、定位路径与处理建议整理成了可复用的案例笔记,便于大家快速对照、排查自身项目中的同类问题。
实战案例
Q:我们发现GPU端顶点处理开销很高,想咨询下是什么原因导致的,以及有什么解决方案?从UWA GOT Online报告中可以看到,大地图场景总三角面约36万个,而当前帧有效显示区域对应的三角面规模仅约4万个。
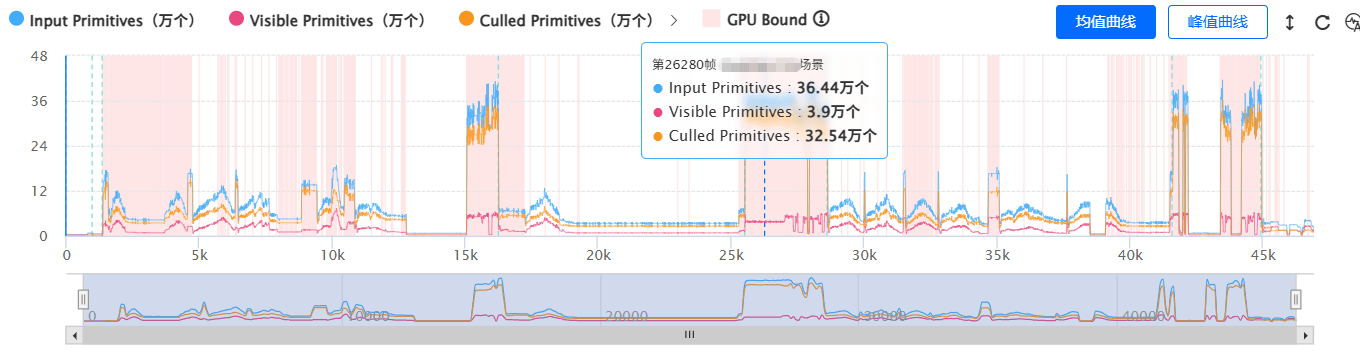
A:这是典型的大范围Mesh合并导致CPU侧裁剪粒度下降的问题。
将大量空间跨度较大的小网格合并为单个超大Mesh后,Unity在CPU侧进行可见性裁剪时,会以整个Renderer的包围盒作为判断单位。只要该包围盒与摄像机视野发生相交,整份Mesh数据就可能继续进入GPU处理流程。
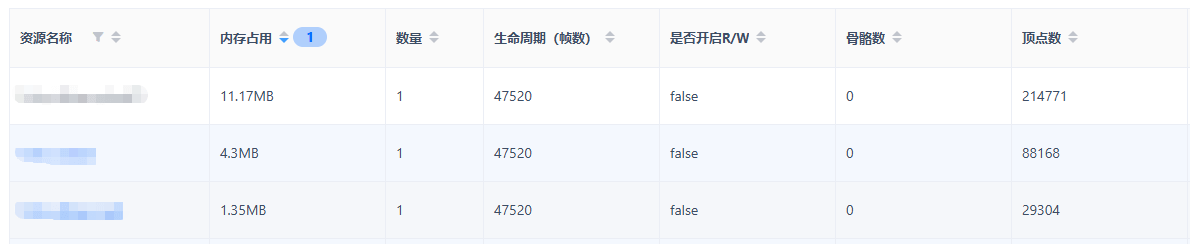
项目中已经存在比较明显的超大Mesh问题。从报告中的Mesh资源详情可以看到,某Mesh资源占用达到11MB,包含约21万顶点。结合场景分布情况来看,大概率存在跨区域的大范围Mesh合并行为。这种粗暴合并方式,会显著降低CPU侧裁剪效果。即便屏幕内仅显示其中很小一部分区域,大量原本不需要参与当前帧渲染的数据,依然可能进入GPU前端处理阶段。
虽然现代GPU具备硬件级裁剪能力,部分不可见三角形会在后续阶段被剔除,但额外的:顶点处理开销、管线调度开销和数据传输开销已经产生,最终导致GPU压力和带宽升高。
解决方案
不建议手动将大量跨区域物件直接拼接为单个超大Mesh。
相比人工大范围Mesh合并,更推荐优先使用Unity原生的官方机制,例如:
- Static Batching(静态合批)
- GPU Instancing(GPU实例化)
- SRP Batcher
进行合批时,需要重点控制空间局部性,避免将跨区域、跨可视范围的大量物件直接合并为同一个Renderer。
更合理的做法是:保留适当的网格拆分粒度,让引擎能够正常进行CPU侧裁剪。这样可以在CPU阶段提前剔除不可见物体,从而减少无效数据提交与GPU管线压力。
需要注意的是:
降低DrawCall,并不一定等于GPU性能提升。如果盲目追求远距离合批,导致包围盒范围过大,反而会削弱CPU侧裁剪效果,让大量原本不可见的数据持续进入GPU管线。
最终出现:
DrawCall降了,但GPU压力反而更大了。
实战案例
Q:Bloom、DOF后处理功耗高、GPU性能压力大,该如何优化?同时画质分级该如何配置?
A:报告信息显示如下:
Bloom优化
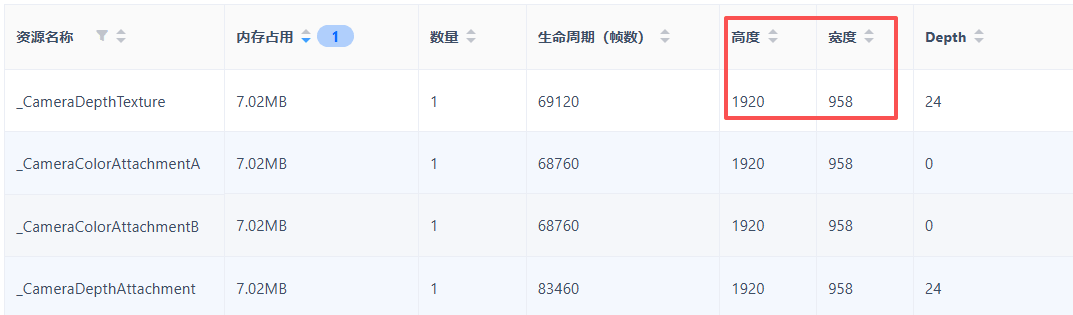
Bloom的性能开销,主要来源于高分辨率渲染纹理的多级下采样与上采样流程。
从当前报告来看,1920×958的高画质渲染分辨率配置合理,建议将Bloom下采样倍率从1/2调整为1/4。
在场景高亮元素较少、画面细节可接受的前提下,优先改用1/4倍率下采样,能减少高分辨率渲染纹理的读写与缓存开销,显著降低显存带宽压力。
修改后可对照GOT Online报告功耗曲线与真机画面表现,在保证画面效果基本稳定的前提下选用更低的下采样倍率。
DOF优化
景深DOF对GPU算力与显存带宽消耗极高,优化原则如下:
- 先确认业务是否必须开启,若视觉效果提升有限,可直接关闭;
- 优先选用Gaussian DOF,避免使用Bokeh DOF,后者性能开销远高于前者;
- 中低画质档位机型建议直接禁用DOF;
- 避免使用DOF模拟画面边缘压暗效果,可改用URP原生的Vignette(暗角)后处理,性能开销更低。
无论是社区里开发者们的互助讨论,还是AI基于知识沉淀的快速反馈,核心都是为了让每一个技术难题都有解、每一次踩坑都有回响。希望这些从真实开发场景中提炼的经验,能直接帮你解决当下的技术卡点,也让你在遇到同类问题时,能更高效地找到破局方向。
封面图来源于网络
今天的分享就到这里。生有涯而知无涯,在漫漫的开发周期中,我们遇到的问题只是冰山一角,UWA社区愿伴你同行,一起探索分享。欢迎更多的开发者加入UWA社区。
UWA官网:www.uwa4d.com
UWA社区:community.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859



