
渲染大面积草地时,如何降低消耗?
- 作者:admin
- /
- 时间:2020年04月22日
- /
- 浏览:4618 次
- /
- 分类:厚积薄发
1)在渲染大面积草地时,如何降低消耗
2)使用LoadFromMemory导致内存翻倍问题
3)对Android x86平台的支持问题
4)OnGUI的堆内存分配问题
这是第200篇UWA技术知识分享的推送。今天我们继续为大家精选了若干和开发、优化相关的问题,建议阅读时间10分钟,认真读完必有收获。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Rendering
Q:请问下大家,渲染大面积草地时,如何降低消耗呢?
A1:回答如下:
1.使用DrawMeshInstance;
2.上面这个API是不会进行视距剔除、视锥体剔除和遮挡剔除的。下面有两种方案:
a.将草地按区域分组,用每组的中心点计算视距,依据距离切换网格LOD或剔除;还能用向量点乘简单剔除在相机后方的草地(注意临界问题)。
b.借助CullingGroup。
CullingGroup.onStateChanged事件绑定,通过事件触发调整传入;DrawMeshInstanced的Matrix顺序和渲染数量(但是DrawMeshInstanced只能指定渲染前几个Matrix);
通过cullingGroup.SetBoundingSpheres实现视锥体剔除和遮挡剔除;
通过cullingGroup.SetBoundingDistances实现视距剔除和LOD。
这个方案最好也进行区域分组,不然CullingGroup的事件监听占用会比较高,在中端机上4000个监听会占约2ms的大小。以后如果有对比两种方案的性能,我再进行补充。
附:
- 《CullingGroup API的使用说明》
- 《Unity 3D研究院之Lightmap支持GPU Instancing》
- 《如何高效使用GPU Instancing技术来进行草丛渲染》
- 升级Unity 2018,DrawMeshInstanced不生效的问题
感谢题主李先生@UWA问答社区提供了回答
A2:使用Indirect模式的Instancing,配合Compute Shader实现视锥剔除和遮挡剔除。
感谢邹春毅@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e919a528cabe84a011afcde
AssetBundle
Q:UWA的几篇文章中都有说到尽量不要用AssetBundle.LoadFromMemroy接口,因为这个接口会使得内存的占用翻倍,但是我用Unity 2017.4.5f1进行测试后,发现AssetBundle.LoadFromMemroy和AssetBundle.LoadFromFile几乎是没有差别的,因为文章中也没有关于体积具体的版本信息。所以我想问是之前的Unity 4.x或者Unity 5.x版本才有这个问题?还是说测试用例是有要求的呢?
另外,我是在PC上进行测试的,打包出exe,直接用任务管理器查看内存占用情况,发现并没有区别。
A1:应该是在C++里面直接申请一块内存用来解压,Mono占用不会变但是PSS会增大,内存峰值也会变高,使用adb shell dumpsys meminfo packageName来查看PSS。
如果目标平台是PC,那就说明内存策略可能是分配后立即归还给操作系统了。如果PC不是目标平台,那么看内存就没有很大的意义。
感谢张迪@UWA问答社区提供了回答A2:LoadFromMemroy输入的byte数组用的是Mono堆内存,哪怕这个内存有释放,但Mono堆内存总量是只升不降的,在加载资源的过程中,一旦Mono触发GC后仍内存不够,很可能需要申请新的Mono内存,这会导致Mono内存持续升高。
而且用LoadFromMemroy没有必要性,用这个接口哪怕内存不是问题,也会在加载资源时明显比LoadFromFile慢不少,而且真的想要逆向AssetBundle资源还是很容易的。退一步说,非要加密建议使用LoadFromStream,然后自己去实现Stream解密。
感谢loy_liu@UWA问答社区提供了回答A3: 我之前的测试有问题,现在更正一下:LoadFromMemroy即使在PC平台也不如LoadFromFile接口。
经测试,PC上LoadFromMemroy接口内存的占用大概会高1/5左右,加载时间比LoadFromFile接口慢1/5左右,而且如loy_liu所说,LoadFromMemroy接口需要先读取byte数组,会产生Mono内存的分配问题,而LoadFromFile不会。在Android平台上,内存的对比非常夸张,我这边测试的数据翻了接近3倍。
所以尽量不要使用LoadFromMemroy接口,我没有去测试LoadFromStream接口的性能和内存,但据说和LoadFromFile差不多。
感谢题主fdy@UWA问答社区提供了回答A4: Lzma的资源包LoadFromMemory会导致资源本身翻倍。L4z资源包类似于管理器,本身占用内存很小,翻倍也没关系,而内存流本身也是用完就能扔。
感谢欧月松@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e8ed8c6cd6a9b49fb4a46a3
Build
Q:目前项目发布后大于100MB,检查发现是libil2cpp.so较大,大概大于60MB,而且同时支持了ARMv7、ARM64、x86,相当于x3的大小。所以想问一问大家,目前x86架构的机型大概占比多少?需要继续支持吗?
A1: 没必要,我建议去掉。
感谢loy_liu@UWA问答社区提供了回答A2: 大多数模拟器都是X86,可以考虑下。
感谢欧月松@UWA问答社区提供了回答A3: 需要支持,否则模拟器会很卡。
感谢Fly@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e9019ec8cabe84a011afc71
Memory
Q:在PC上运行游戏,用Profile工具检测的时候,发现GUIUtility.BeginGUI内存泄漏,每次调用产生0.8KB的内存消耗,每帧调用4次,就是3.2KB。请问这是什么原因引起的呢?
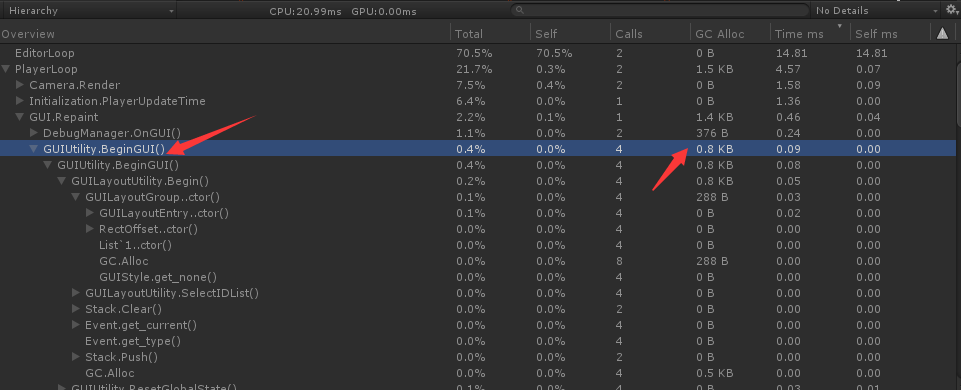
A:OnGUI必然有GC Alloc,即使是空函数。你可以拿宏括起来,用来做Profiling的包不要编译进去。
感谢littlesome@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e86ec0dacb49302349a1141
封面图来源:
Real Time Grass Rendering:Unity的逼真的实时草渲染。
https://lab.uwa4d.com/lab/5b563dded7f10a201fd8c88b
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)