
技术分享连载(九十五)
- 作者:admin
- /
- 时间:2018年01月16日
- /
- 浏览:3881 次
- /
- 分类:厚积薄发
本期聚集了这些话题:Lua的ffi在iOS上的性能、Shader.CreateGPUProgram的优化、VR设备优化......
UWA一下,你就知道~
我们将从日常技术交流中精选若干个开发相关的问题,建议阅读时间15分钟,认真读完必有收获。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。
UWA QQ群:793972859
UWA 问答社区:answer.uwa4d.com
渲染
Q1:我们游戏里要用投影仪做施法范围显示,图片边缘留几个像素透明没什么问题,但是这样导致实际范围跟显示不一样,投影的图片不留边缘的话就会出现十字,请问是否有更好的解决方法呢?

我们用的是Unity 5.6.2版本,例子工程已经上传至UWA问答社区。
纹理采样时,纹理坐标超出[0, 1]之间的时候会取离得最近的(0或者1)上的纹理像素,即纹理边缘的像素。这时候,如果纹理边缘留1~2像素空白(alpha=0)则会取空白(alpha=0)像素,如果不留则是上面的情况。
建议题主解决方法有两个:
1)纹理周边还是留1~2像素的空白,然后在设置Projector size大小的时候根据留的像素个数对Projector size进行scale,使得scale过后的可见部分刚好是需要的size,用以修正范围不准确问题。
2)修改Builtin Shader,在纹理采样时判断,如果纹理坐标超出[0, 1],则将alpha值设置为0。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a55c1473bc73e22933168fa
加载
Q2:我在UWA的性能评测报告中看到Shader.CreateGpuProgram的耗时很高,请问这个可以优化吗?
如果Shader.CreateGPUProgram仅出现1~2次,那么其实问题不大,但如果是频繁出现的,那么就需要严格优化了。关于Shader.CreateGPUProgram的优化,主要可以分为以下几点:
1)如果项目是通过Resources.Load来进行加载的,那么可以通过以下两个来实现:
- 将常用Shader放在“Always Included Shader”中,让其在游戏启动时直接进行加载;
- 将常用Shader放在Shader Preloading中,以ShaderVariantCollection的形式进行加载,这种加载的好处在于可以指定动态加载的时间和加载的Keywords,不仅更加灵活方便,同时加载时间更短。
以上说的仅是完成了Shader.Parse工作,而对于Shader.CreateGPUProgram,则在加载和实例化后,在相机的视域体中直接“渲染”一帧即可,这样会触发Unity引擎进行CreateGPUProgram操作,从而将运行时的开销前移,一般建议在游戏加载或者场景切换时进行。
2)如果项目是通过Resources.Load来进行加载的,那么直接通过AssetBundle.Load来加载Shader,完成Shader.Parse操作。后续工作同上。
注意:以上方式仅适用于Unity 5.0以后版本,并且Shader在加载后需要常驻内存中,如果后续将其卸载,那么Shader.Parse和CreateGPUProgram操作还会再次触发。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/58dbb737901de5f21c6569c2
渲染
Q3:我看了这篇文章《用好Lua+Unity,让性能飞起来—LuaJIT性能坑详解》,这里说在iOS上不支持LuaJIT, 但是可以用Interpreter模式。我看到文章里说:“必须要注意的是,ffi只有在JIT开启下才能发挥其性能,如果是在iOS下,ffi反而会拖慢性能。所以使用的时候必须要做好快关。”
我的疑问:
1. 在IOS上开启JIT Interpreter 也会比原生Lua快吗?
2. 使用Interpreter模式的ffi调用C库会比原生Lua更慢吗?
我想在C里解析二进制协议,比如Lua调用C去readInt,readShort这样,Lua本身不支持位运算,如果用Lua的bit库做位运算解析性能很慢,所以想用ffi调用C来实现)。还有一种调用C的方式,就是Require C动态链接库,如果iOS下的ffi性能不好的话,这个是不是最佳选择?
Lua相关的协议解析库,网上有很多,比如云风的pbc,也基本达到产品级的可用度,可以参考或者直接用。这些库大多也不是采取在Lua逐个字段展开的方式,而是由C统一展开,可能会做lazy init的优化。逐字段在Lua调用c function展开必然会把大量时间消耗在语言交互上。
ffi脱离了JIT之后性能大打折扣(10倍级别),不建议用来做大规模的协议解析。不过一般来说客户端的协议解析不是瓶颈(前提是不能设计很大的协议,例如登录下发的用户数据),针对服务器的话因为JIT是可以开启的所以性能会高很多,另外不管是否JIT,ffi都有内存小(跟c struct一样紧凑)的优势。
但选择ffi就等于绑定了LuaJIT,确实要谨慎。毕竟用LuaJIT主要是因为性能,在语言标准、可维护性、社区活跃度上都落后于Lua5.3。
该问题来自UWA问答社区,感谢招文勇提供了回答,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a537945a1fdae3c4ba3ccd9
VR 性能
Q4:我们项目是VR的,制作单个建筑,一个建筑2000~3000面左右:

美术手动合并场景中同类型的建筑,以同类为主进行合并,位置是有一定距离,会出现摄像机看到合并后的某一个建筑但看不到其他建筑的情况。

手动合并好后加入SimpleLOD的脚本,对每个合并好的网格进行LOD,设置为静态让运行时Unity再去Static Batch。运行时是静态合批的效果,但小镇的房屋会与非常远的矿洞里面的一些横梁合并到一个大网格里面去。
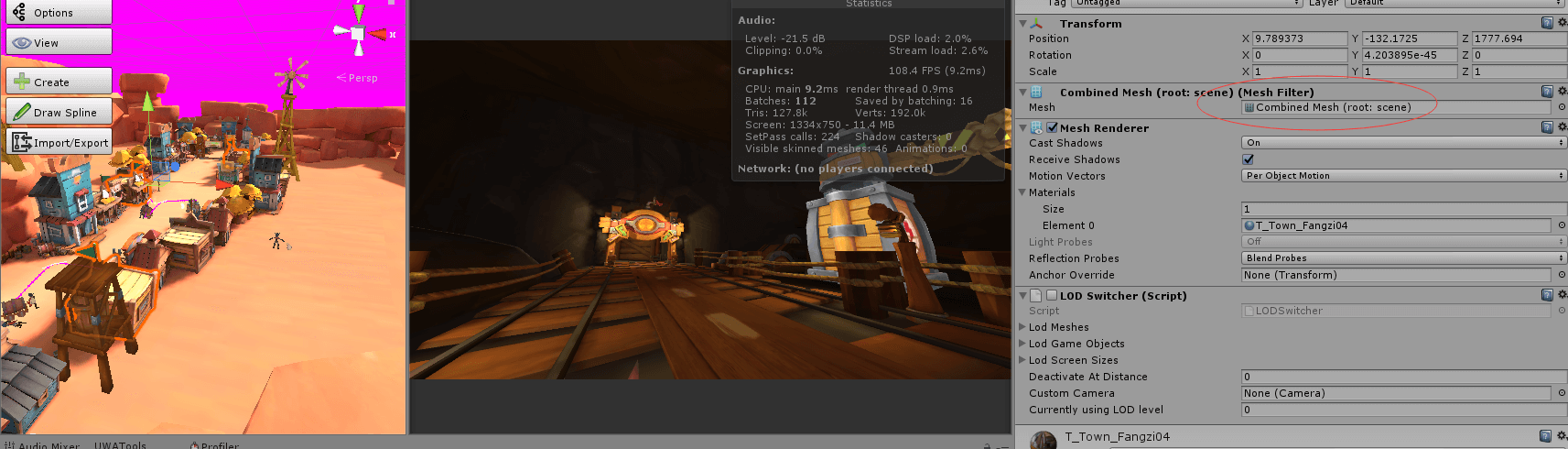
现在有如下问题想咨询:(为方便阅读,下文把问题和回复一并罗列)
Q4.1:我们场景特地设置为有明显遮挡的,按理说遮挡剔有助优化渲染,应如何提升Culling的效率?
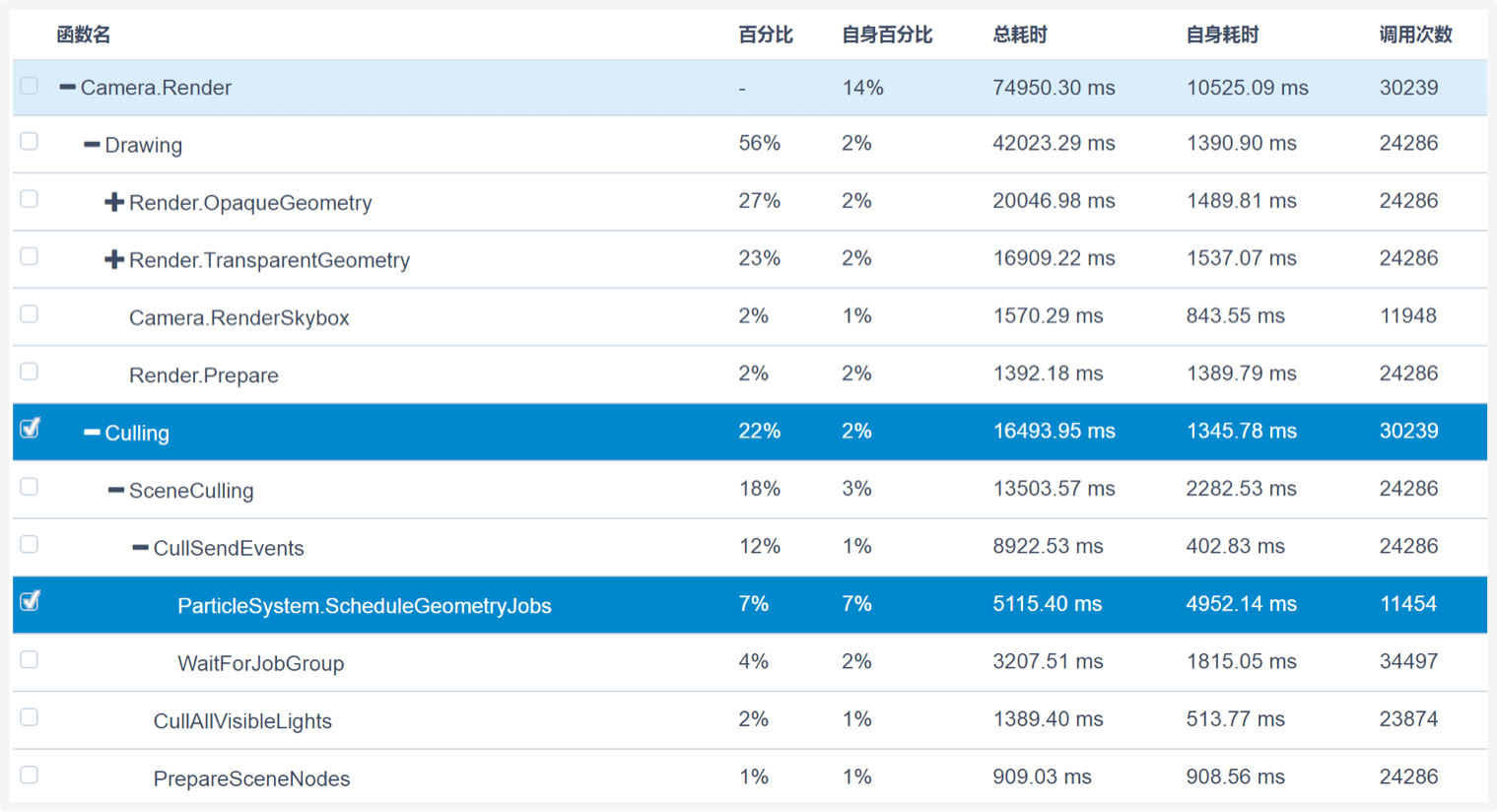
A:其实,查看提升Culling的渲染效率还需要题主进一步通过报告查看Culling的瓶颈在哪里。
下图为题主这次报告的Culling具体耗时(可以在代码效率页面中查看),可以看到粒子系统的耗时很大。
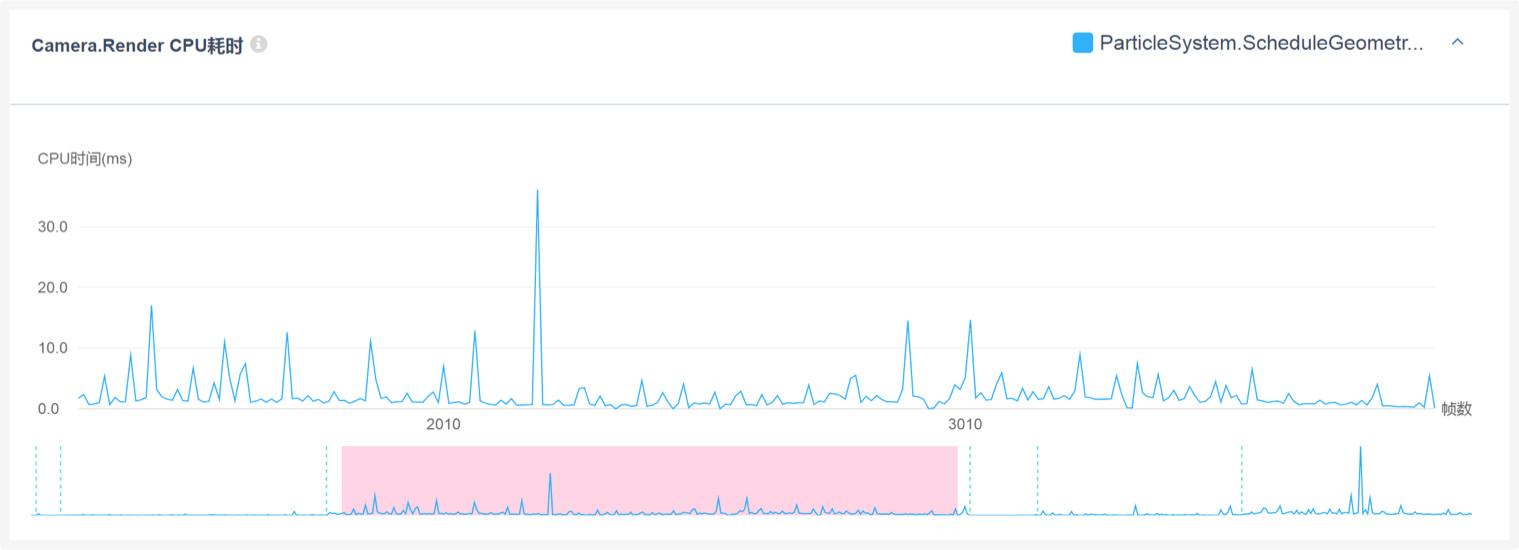
下图为该粒子系统Culling的具体耗时情况,建议对粒子系统的渲染数量进行控制。
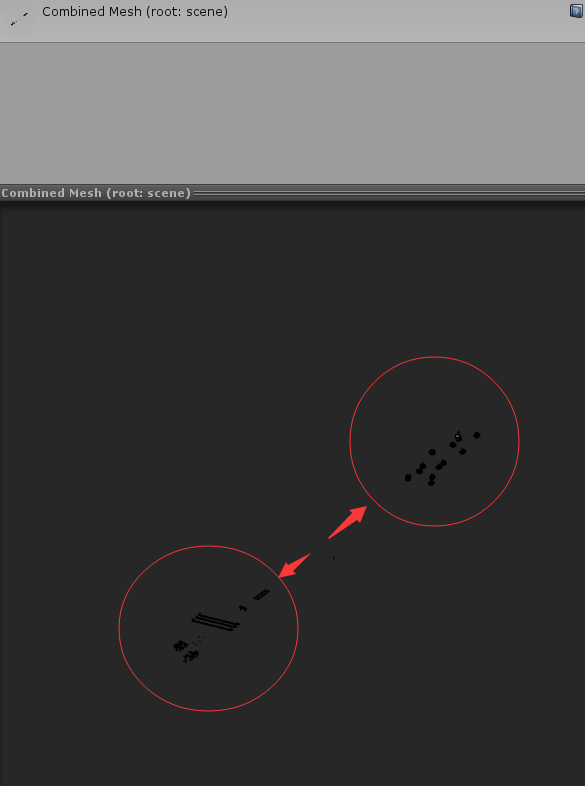
Q4.2:使用同类型模型手动合并的做法是否正确?
A:这种做法无可厚非,自己Offline合并是可以的,并不是错误的做法。需要注意的是,Offline合并需要注意不要把过多视域体外的物体引入计算即可。这点其实挺难做到,所以一般来说,Static Batching是一个更好的选择。
Q4.3:这样的静态合批结果是正确的么,会不会导致在矿洞看到横梁时就把小镇的建筑都渲染出来导致渲染占用CPU时间过高?就现在的DrawCall峰值305,三角面峰值64万,如果针对小米5以上的手机,是否是影响CPU占用时间的关键?因为小米VR是用rt实现,两个眼睛渲染两遍。但美术也不愿意修改美术资源的精度。
A:60w的面片数确实很高,因为是双目的,所以单屏30w渲染面片。这个对于移动设备来说,还是容易引起发热的。建议通过Unity Editor来查看一下,是否确实存在问题2中合并过量的情况。从图中可以看出,你的Combined Mesh应该是Static Batching来合并的,这种其实是没问题的,即在渲染时,视域体外部的Mesh是不会参与渲染的。
Q4.4:设计的帧更新间隔是否应该调大,例如客户端是30ms或40ms更新一次?因为想不到其他办法来降低CPU耗时了。
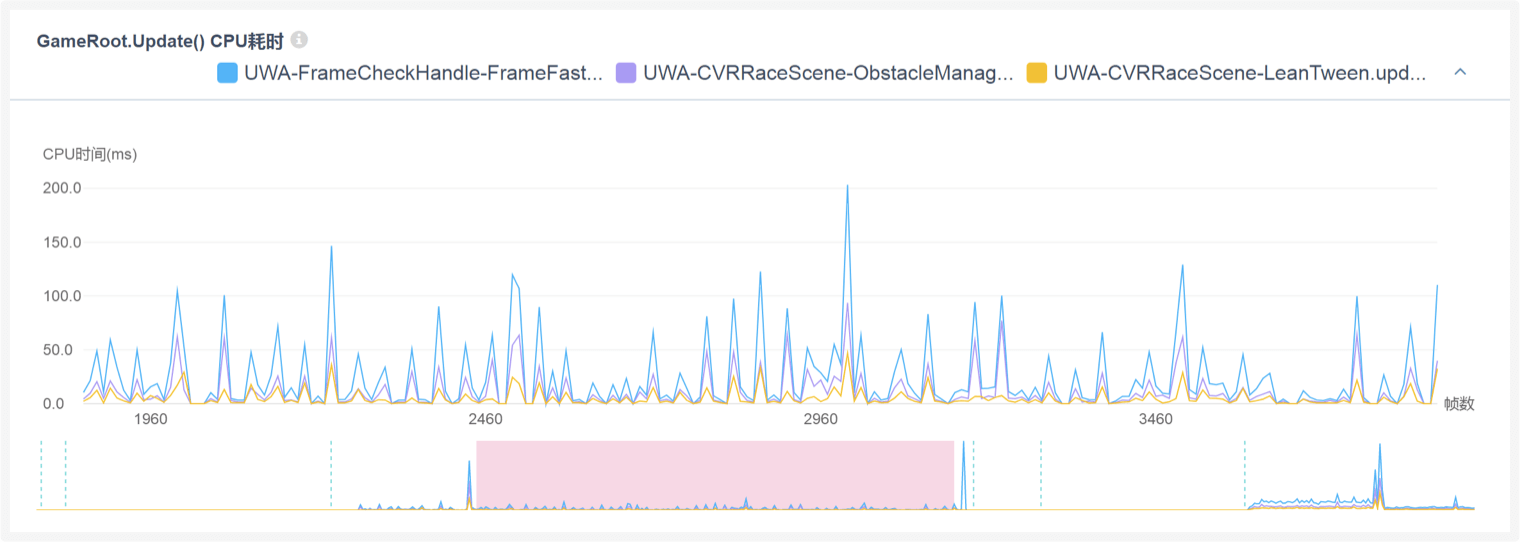
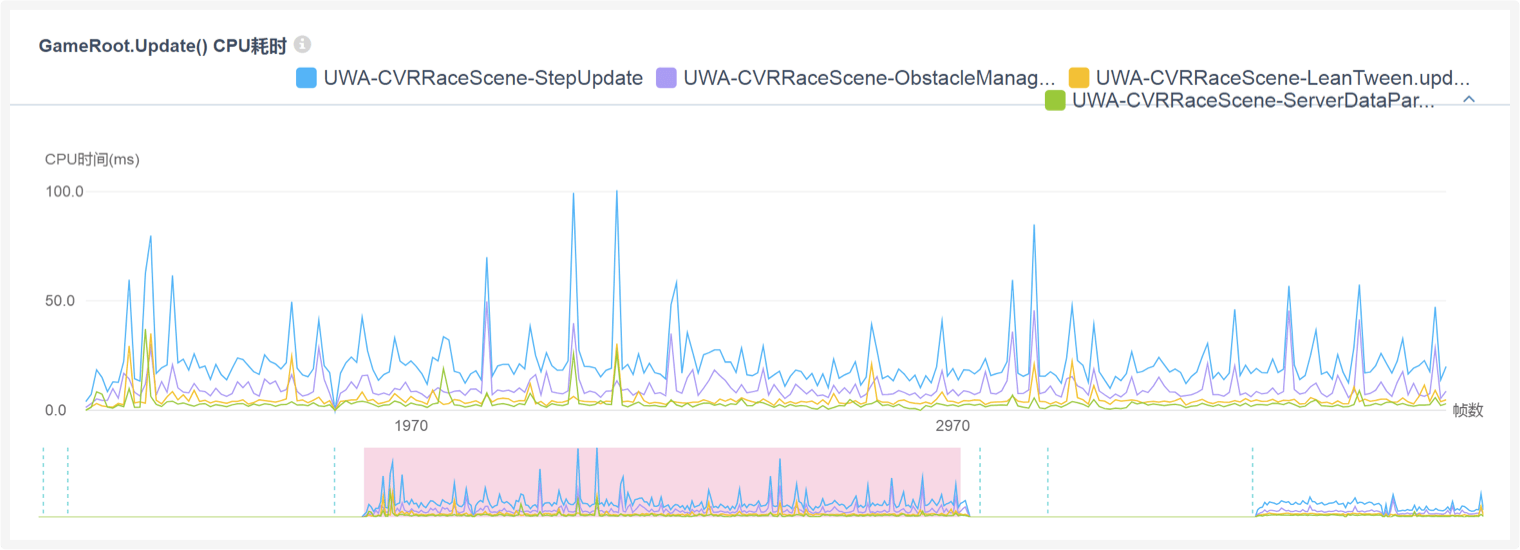
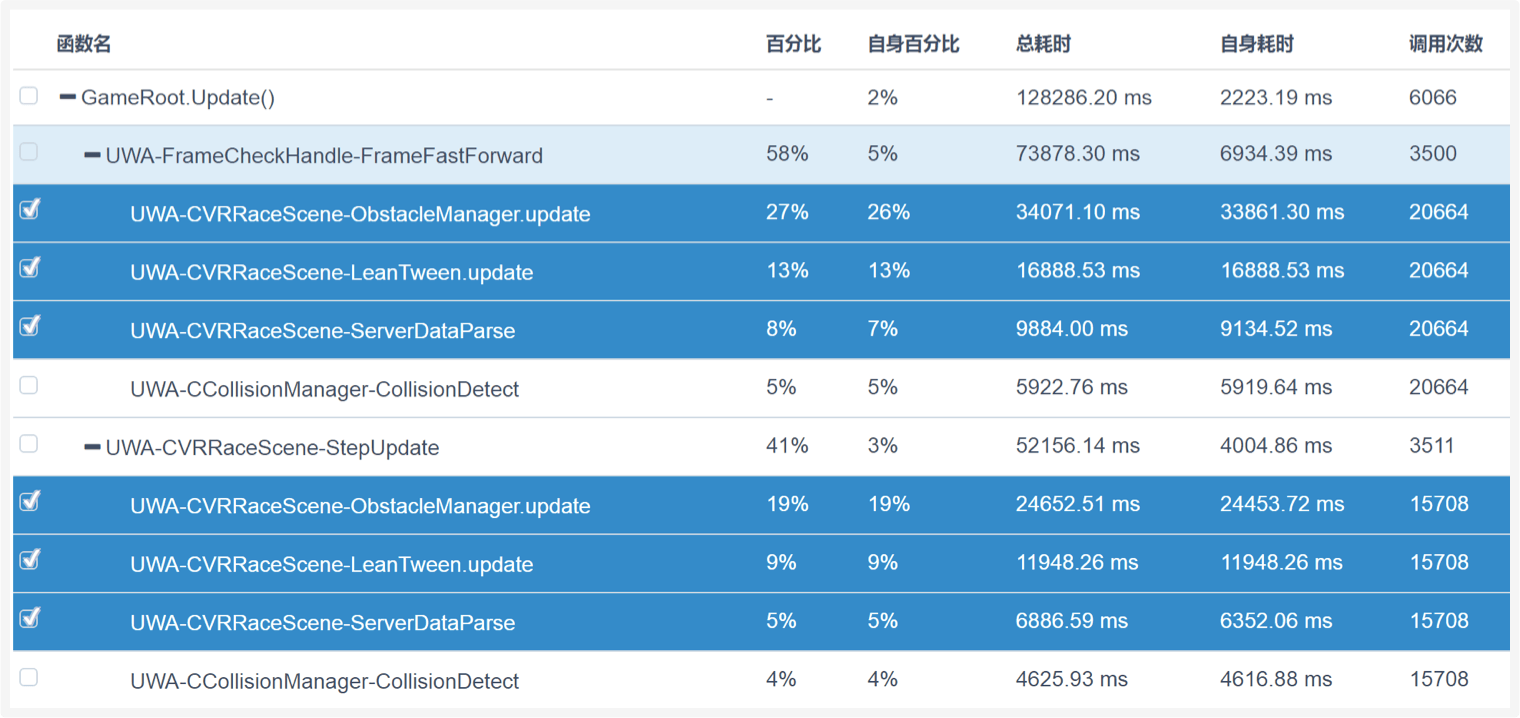
A:从下图可以看出,无论是UWA-FrameCheckHandle-FrameFastForward还是UWA-CVRRaceScene-StepUpdate,其主要的耗时瓶颈都是这三个函数,特别是UWA-CVRRaceScene-ObstacleManager.update,对此,建议题主对这个函数进行进一步拆分,然后详细定位它的耗时瓶颈到底在哪里,然后才能确定优化方案。通过限帧的方式来降低耗时其实是无奈之举,具体的时间间隔恐怕需要进行大量实验才能找到一个适合的参数。但是,这并不能解决本质问题,本质问题还需要通过上面的方法来进行定位和解决。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a409c736f0cccd931e1f31f
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站(answer.uwa4d.com)上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
官方技术QQ群:793972859(仅限技术交流)