
UWA问答精选 优化篇 | 2019年度大赏
- 作者:admin
- /
- 时间:2020年02月09日
- /
- 浏览:4599 次
- /
- 分类:厚积薄发
UWA每周推送的知识型栏目《厚积薄发 | 技术分享》已经伴随大家走过了200个工作周。在此我们精选了10个与优化相关的精彩问答,分享给大家。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Q1:2019.2版本UI耗时异常分析
我使用UWA GOT Online测试我自己打的Unity Android APK包,版本是Unity 2019.2.6f1 (64-bit),当我勾选多线程渲染和不勾选多线程渲染的情况下,UWA网站分析的BuildBatch CPU均值不同。但是理论上勾选多线程渲染,BuildBatch CPU均值应该低,性能更好才是,但是我勾选了多线程渲染,评测出来的BuildBatch CPU均值反而增高了,这是为什么呢?
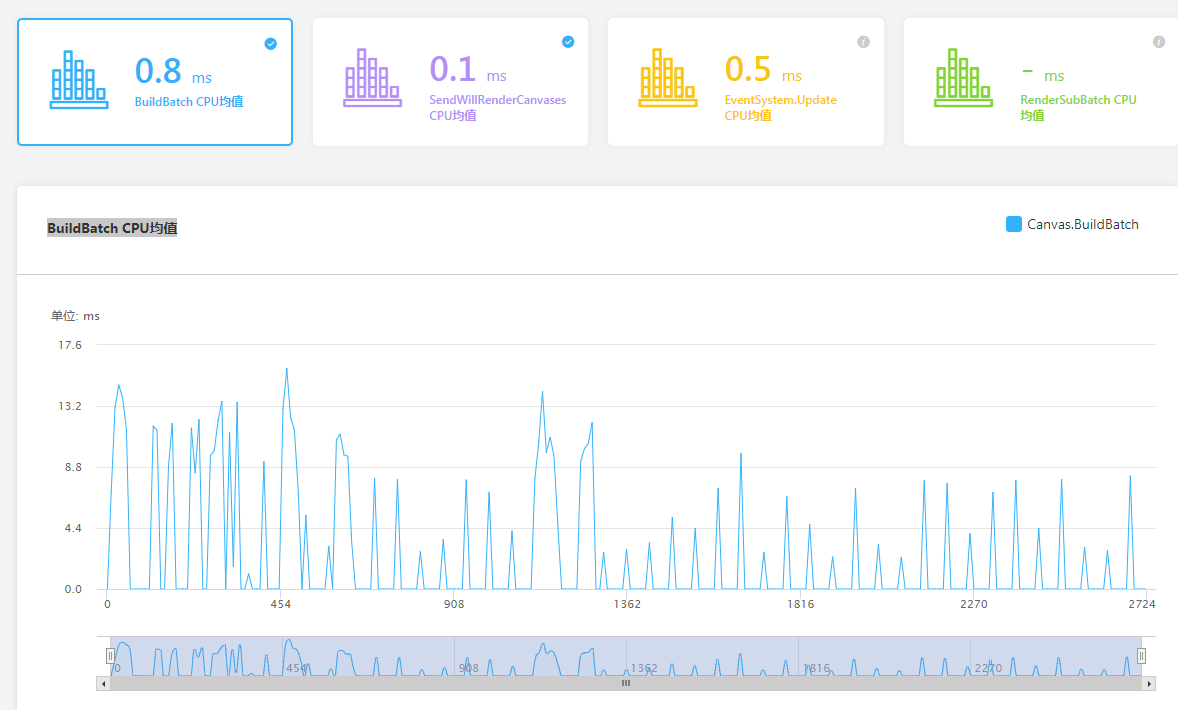
开启了多线程渲染
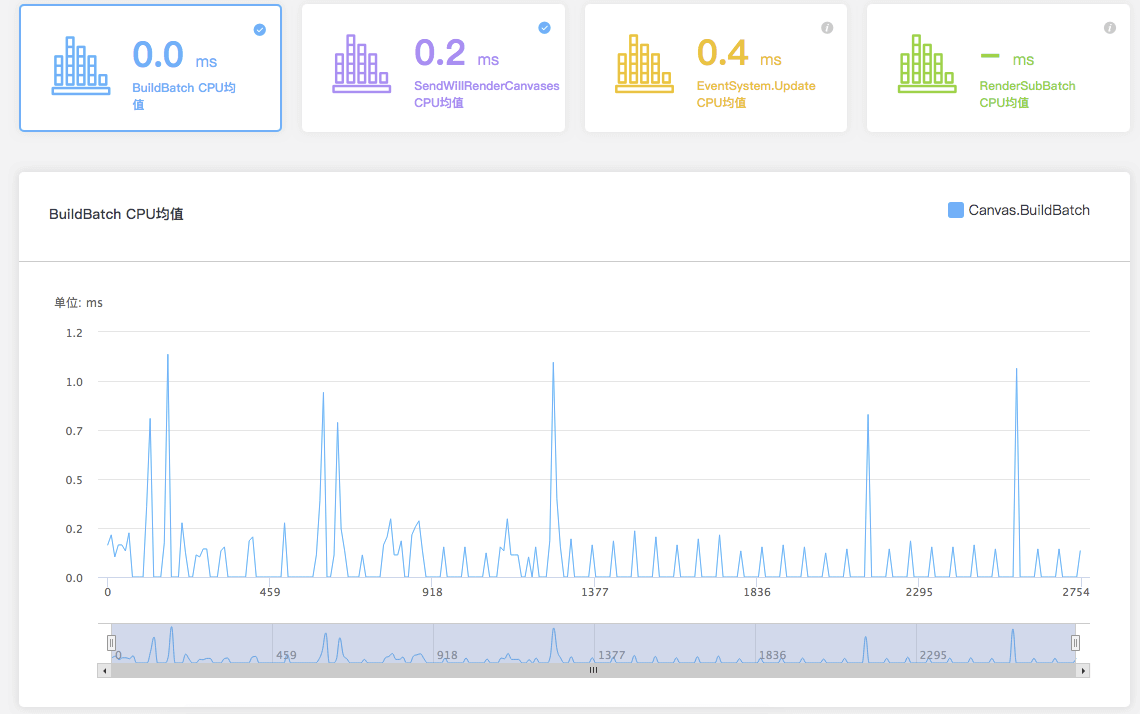
未开启多线程渲染
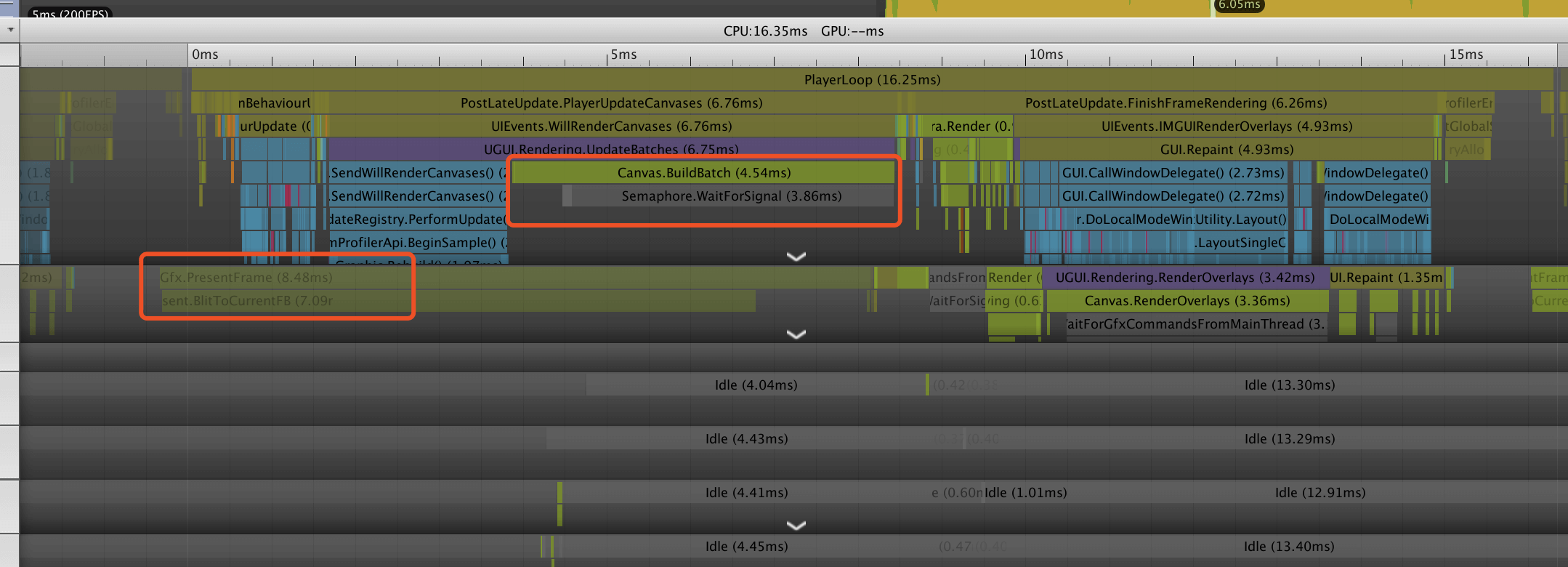
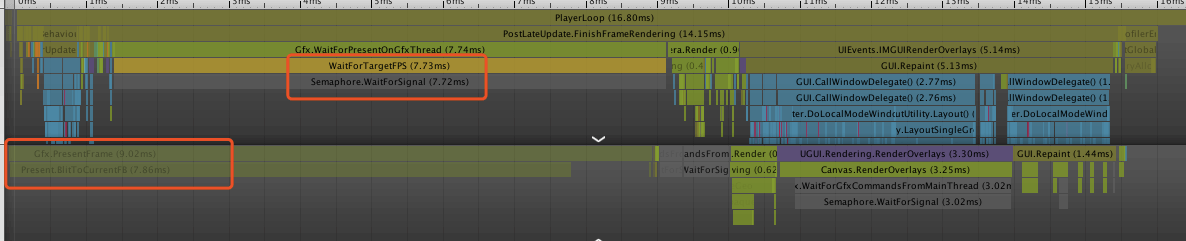
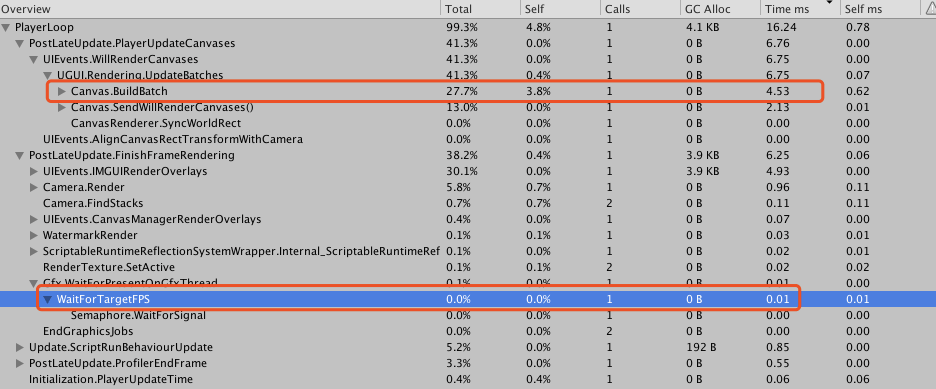
A:我们测试了空场景下一个文本每秒钟更新的case,在小米5X上测试,发现确实会有很高的BuildBatch耗时。
通过查看Profiler的Timeline视图发现,BuildBatch对应的是上一帧RenderThread的Gfx.PresentFrame,并非UI自身耗时。
而在BuildBatch耗时低的其它帧,这里等待的时间被统计在WaitForTargetFPS中。
相对应的,在BuildBatch耗时高的这一帧,WaitForTargetFPS耗时只有0.01ms。
因此我们认为是Unity在这个版本中出现了Bug,导致的统计异常问题。
该回答由UWA提供,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5e0ef38473f93355f9668073
Q2:升级后的物理开销问题
Q:一个项目场景里只有静态碰撞盒, 用于玩家点击选中。Unity 5.6之前,物理开销基本没有。 升级到Unity 2018后,分析报告里的物理开销2ms不到,虽然不多,但是很奇怪。
后来发现Project Settings里把Physics.autoSimulation关了之后开销就下去很多了, Physics2D.autoSimulation关了之后会再下去了一点点。这个参数好像是Unity 2017之后新加的参数。
看介绍,关了这个参数之后每次LateUpdate的时间里就不会自动处理物理方面的计算,可以手动调用Physics.Simulate来手动控制物理计算。
A:物理系统不会自己去运行了。在5.4~2017.2版本中,Unity引擎可以根据你们项目中Rigidbody的使用情况来自己决定是否开启物理引擎,如果没有使用,则它会自动关闭。但是,在2017.4版本以后,物理引擎会自动开启,Unity引擎推出API由开发团队自己去控制是否开启和关闭。所以,一般在最新的版本中,UWA都建议大家看看你们的物理模块开销,是否在自动空转,如果耗时较高,则可以尝试自己去关闭Auto Simulation选项。
但是,需要说明的是,如果场景中含有Trigger、布料模拟等,则关闭Auto Simulation后则不起作用了,这个时候研发团队需要根据自身情况来决定该选项的开启和关闭。
该回答由UWA提供,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5dc9229f7307ec2f0f99a1bd
Q3:游戏内大量道具图标,应该如何规划图集?
道具图标可能有几百上千个,如果打到同一图集里,大小都有2048*2048了,实际游戏过程中有额外的内存浪费。
按类型拆分也不太好,新手各类道具各一个,所有类型的图集就都引用了一遍,跟打到一个里没太大区别。
如果按等级段来规划,可能会好一点,但是对于像商城或者某些特定UI上展示的图标,很可能就不是同一个等级段的,也会造成引用好些个图集的情况。如果按常用或者不常用来分图集,要策划全程来跟进这块内容,感觉也很容易出问题。
或者直接对这大量的图标都不打到图集,都是散图,这样虽然不会有太多内存浪费,但渲染效率就低了。
请问下有没有比较好的方案来处理这个问题?
A:(1)如果图量远超单屏显示量,那比较实际的是自己实现动态图集,也就是图标是散图,在运行过程中根据需求实时拼装成大图,可以用RenderToTexture实现。
(2)对于大多数游戏,如果不是常驻画面的界面,以现在机器的性能,忍受一下DrawCall也非不可。动态图集生成方式可参考UWA学堂的《Unity运行时动态图集的实现》。
感谢招文勇@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5c70038e2b3589332f1a4ade
Q4:游戏启动时间,优化和策略选择
这里的启动时间指的是登录界面出现之前的时间。目前我们游戏是启动游戏后,加载所有的表,初始化全部系统,手机上启动时间比较长,看了下《阴阳师》和《完美世界》,都是直接到登录界面的,我们想改成用到系统再加载数据和初始化操作。想问问除了这样之外,还有什么需要注意的地方,以及现在游戏一般启动时间要控制在多少秒?
A1:至少还需要注意下以下三点:
(1)Shader的编译耗时,尽可能将少量Shader放入到Always Included Shaders中,减少不必要的启动编译耗时;
(2)资源初始序列化的耗时,Resources下的资源数量太多,会导致启动很慢;
(3)最近有项目反馈,StreamingAssets下的AB数量也需要特别注意,不要过多,超过1w+,启动时间很有可能会受到影响。至于启动时间一般控制在多少秒内,可以看看其他朋友是否有经验分享。
该回答由UWA提供
A2:可以考虑使用Android splash代替Unity自带的,另外第一个界面使用进度条显示,尽可能让进度条界面最快速度出来。
感谢曾毅@UWA问答社区提供了回答
A3:直接手机连接Profiler看看耗时在哪不就可以了,测试->优化->测试->优化,几次就可以了。

感谢何威威@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d2330d113f8c536542b696e
Q5:移动平台纹理压缩格式选择
Q:在这之前了解过纹理压缩的相关知识和UWA的一些推荐方式。但还是有一点小的疑问,所以在这里再次提出来,希望得到解答。
在纹理压缩格式的选择上,如果Android选用ETC,iOS选用PVRTC,因为有2的次方(ETC1和PVRTC)长宽相等(PVRTC)的要求。
问题1:大家对于美术出图的大小要求是怎样的?
- 出图就出成2的次方。
- 出图不是2的次方,然后通过Unity默认的NPOT的选项让它自动转换了。
- 其它方式?
问题2:上述1和2两个方式有本质上的区别吗?看到UWA上Xin大提到了直接使用NPOT的方式(3年前的问题了):https://answer.uwa4d.com/question/58d2943ae00cc20065a42597
问题3:2的次方要求极端情况会导致ETC2(4的倍数要求,但考虑到如果要使用PVRTC)的内存占用变得很大,这种情况选择ETC2还是RGBA16?
2的次方的要求极端情况会导致宽高都扩大接近一倍(比如:300*300往大的变会变成512*512),这样算下来多数情况如果带Alpha,512*512的ETC2-RGBA比300*300的RGBA16的内存占用还要高。
问题4:大家在纹理压缩格式的选择上,现在(2019年)的项目都是怎样选择的?
ASTC考虑设备的普及情况,Android暂时没有考虑,iOS在考虑范围内(A8要求)。
A:先说问题4吧,这个会影响之前的问题。
2019年,我觉得中国大陆的产品iOS上ASTC已经没什么问题了。iPhone 5s以及之前的设备就算了吧,内存就够玩的了(当然还要看游戏类型,休闲小游戏还是要考虑更多兼容)。放弃的另外一块是iPad mini和老的iPad,iPad的更新频率比较低,所以老设备多一些,但是市场占有率整体也低。
Android我觉得ETC2够用了,像normal等特殊贴图用特殊的压缩方式,也没必要强上ASTC。
iOS:2018年上线的项目强上了ASTC,主要是因为UI不接受PVRTC的压缩效果。
这种选择的情况下:
问题1:方形就不用考虑了,不重要。POT建议遵守,这种对于GPU性能有好处,通过合图以及美术规范就可以处理了。问题2:大部分情况下没有本质区别,只要贴图按照UV采样就没问题。个人倾向于让POT成为美术基本的出图规范(特殊的Loading图等除外)。另外就是美术,如果知道可以用到更大尺寸而消耗又一样,也许可以增加一些细节。
问题3:RGBA16如果效果不失真可以考虑。话说300*300这种,你可以选择搞成256*256,但是整体肯定还是推荐压缩的格式,大部分情况下都比RGBA16要好一些(内存消耗+效果整体考虑)。
一般来说,UI大部分会合图成POT的,3D的部分都以POT的方式设计和制作,这样整体的规范比较好制定。特殊的部分才用NPOT的,也只会影响比较少的部分。
感谢贾伟昊@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d9c1978a27d4e20a003aed4
Q6:骨骼数目和骨骼层级数目的合理范围
想请教一个问题,骨骼数量和骨骼层级数目对性能的影响真的很大吗?(有的文章是这么说的 )。我们经过了简单的测试,发现影响并没有很显著。一个3000面的角色,100骨骼,7层,是否是一个合理的指标?还是存在很大的浪费?
A:不知道题主是如何测试的,默认不开启GPU Skinning或者用特殊的处理方式的情况下,这块影响的主要是CPU的性能,所以我觉得比较科学的是统计不同骨骼数量的情况下CPU中动画模块的时间消耗来进行判断。
比如目标场景内会有N个角色,那么按照60根骨骼和100根骨骼放置N个角色,比较耗时差异。
另外,还要看100根骨骼是最大化骨骼还是所有角色参与蒙皮的骨骼数量都是100根,这里可能也会有性能差异。我也做过一个简单的测试,最终影响Animator.Update的性能消耗的是参与蒙皮的骨骼数量。这样如果采用最大化骨骼方案,其实不用特别限定最大化骨骼的数量,而是应该限定每个角色参与蒙皮的骨骼数量。
比如在电脑上,动画相关的模块的性能消耗对比。
100个角色,300根骨骼全部参与蒙皮:
100个角色,300根骨骼,但是其中只有60根参与蒙皮:(这里更新一下,确认了一下发现Unity在导出时,不参与蒙皮的骨骼就不会再导出了,所有这里300根骨骼的概念只存在于Max中,在Unity中已经被优化成60根骨骼了。)
100个角色,60根骨骼全部参与蒙皮:
当然这里只是测试性能差异,更真实的数据是在目标机型上进行。
另外,骨骼层次可能过深并不好,但是假设在开启了GameObject优化选项的情况下,我不觉得像是7层和10层这样的性能差异有很大。这块不是非常确定,只是从动画计算过程来推断——逐层计算的时候引擎一般会存储一个到根节点的变换矩阵供子节点直接使用,因此在这里应该不会增加很多的额外消耗。不过这点需要进行一些测试,没有看过Unity源码并不确定。
单纯从性能考虑的规范来说,对于刚刚立项的项目,100根骨骼,7层,我个人觉得是可以的,3K面有点保守了,这个要看具体的游戏类型。当然,骨骼数量也要根据游戏类型来判断是否合理,比如动作类游戏可能就需要更多骨骼。
PS:测试数据使用的是人形模式。
PPS:再解释一下这个试验,@xin大跟我沟通之后我发现这个试验是有些没有太大意义的。
之前做自研引擎的时候,模型导出的之后,即使不参与蒙皮的骨骼也被导出到了模型身上,因此在动画更新的时候有个优化是将不参与蒙皮的骨骼剔除掉。我最初想通过这个试验验证的是Unity会否做这样的优化(猜想是会做的,因为比较基础),从结果看也是这样的。但是我发现Unity是在导出的部分就已经做了这样的优化,即在Max中有300根骨骼,只有60根参与蒙皮,导入到了Unity内就只有60根骨骼。这个的意义在于前文说的对于最大化骨骼数量的限制,我们之前的骨骼数量的限制是在最大化骨骼这层的,但现在看起来应当限制在最终模型的骨骼数量这一层。



感谢贾伟昊@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5c73a20763826a332ad9969f
Q7:默认画质的机型适配方案
Q:我们现在的方案是按照CPU性能分档来做的,不过机器性能分档还和GPU/分辨率等相关,我们的分档和UWA提交测试时的机器分档就不一样。请教下大家是怎么做的?
A:个人认为没有必要死板的遵循某一准则,比如某些公司的标准中以高通的SoC型号的数字来分档,大于某个数字的就算第一档,但其实近两年新出的一些中端芯片综合性能已经明显高于几年前的旗舰芯片。
所以我们团队在做这个功能时,主要遵循的规则是:在满足研发/发行的强制要求的前提下,结合项目类型及性能瓶颈点,为每一个设备在帧数达标的前提下选取其能接受的最高画质。
以下举两个例子说明:
例如一些较老的使用高通810的机器,这一代芯片发热较严重,虽然在一些公司的标准中属于一档机,但由于经常会降频,所以我们只会将其设置成中等画质。
例如OPPO R9等一些较老的联发科的芯片,在实际测试中性能表现很糟糕,所以相比同年发布的同级别高通芯片,会特意将其降低一档。
在我们项目中实际分级时,分为5档。前面说了要尽量细致地照顾到所有机器,所以我们维护了一张表格,根据不同机器的参数将其映射到5档里面。
iOS设备,主要根据其Device Model来划分,iOS由于设备量很少,基本通过其型号就能预估出大概的性能范围,具体的DeviceModel信息网上资料很多,可以参考:https://stackoverflow.com/questions/26028918/how-to-determine-the-current-iphone-device-model
Android设备主要根据其GPU型号来划分,我们主要参考:https://www.techcenturion.com/mobile-gpu-rankings
根据这个帖子中给出的评分初步整理,然后结合实际测试运行下来的情况进行微调。
另外分级中的每档的具体设置,需要具体项目具体分析,基本上主要的设置无非就是分辨率、屏幕后处理、材质精度、阴影设置、LOD设置等等。
感谢范君@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5df34c3fce53cf56002cad31
Q8:优化LWRP下产生的大量RenderTexture
Q:使用了LWRP与Unity Postprocessing,内存中有大量的RenderTexture,这些占用内存达100多MB,如下图:
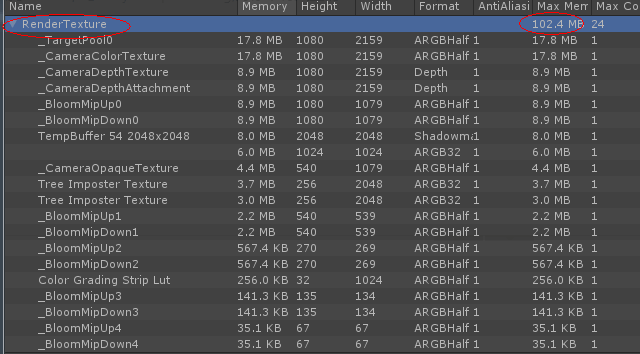
想知道如何优化这部分内存占用?有没有实在的方案或者方向?
A1:Bloom应该可以降下分辨率而且也可以减少采样次数(不需要上下采样5张),还有就是减少OnRenderImage的函数,这个可以减少TempBuffer或者ImageEffects的贴图。大头其实还是你的_Camera 使用的,这个如果能减少或者降分辨率,你的内存就下来了。
感谢李星@UWA问答社区提供了回答
A2:首先LWRP会默认blit出每帧的Color Buffer和Depth Buffer,用于扭曲、折射等效果,如果项目中没有这样的需要可以关闭,可以节省掉_CameraColorTexture和_CameraDepthTexture的内存,这个在摄像机上就有选项可以关。
其次是RenderTexture格式的问题,截图的RenderTexture格式为ARGB Half,如果没有在A通道存储内容的需求,可以把RenderTexture的格式换成R11G11B10,RenderTexture内存可以减半,同时仍然可以支持HDR。
最后是Bloom,Diffusion这个参数调小可以减少迭代次数,减少RenderTexture的数量。也可以改一下Bloom的代码,把第一次Bloom降采样的分辨率降为屏幕原分辨率的1/4,也可以减小Bloom RenderTexture的内存。
感谢王阳@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d91b136a27d4e20a003aec1
Q9:关于撑大Mono的问题
项目用Xlua,发现一个问题:
一个UI(多些文字就容易复现)打开、销毁、再打开、再销毁…,如此多次,Mono会不停的增长,C# GC也不能完全GC掉。
然后发现一个会降下来的现象:
Lua GC一下,C#再GC Mono会降回去一点(但也回不到最初)。这个问题应该是两者都用了引用计数来回收, 两者不同步, 虽然Destory了对象,Lua里还没GC到,则一些被Lua引用的对象等也还在引用着。
然后两边来回GC几次,基本可以回到原来的Mono值。
网上看到类似问题,是ToLua的:
http://www.manew.com/forum.php?mod=viewthread&tid=141722&extra=page%3D&page=1
里面提了几个方案。做了2个调整:
(1)尝试Lua GC频率稍微调高些;
(2)然后XLua本身也提供了删除引用的处理LuaEnv.Tick()函数(慢慢遍历检测引用的C#对象是否销毁,已销毁了就置null,可以解引用,后面GC就会被GC掉)调用了,且提高每次遍历的数目。
但还是有增长的情况,不知大家如何解决这类问题的?谢谢!(UI做缓存池会好一些吧?但还是有一定概率会出问题,撑大Mono的)
PS:还有一点觉得难受,Lua和C#里泄漏的东西,很难知道到底当时是什么地方造成泄漏的。必须短时间内重复一些简单操作,才能推测大概泄漏的是什么东西,然后去对应地方找问题。
有什么可以方便定位哪个Lua的地方应用了哪个C#的地方?或者 C#引用了Lua的哪个地方?
比如有一些双向引用了,GC不掉,只能推测大概是哪里和哪里引用了。
A:题主对Lua和C#内存这块理解已经非常深刻了,我们也有类似问题,我们只做了第一个处理:
调整Lua GC的两个参数,让Lua垃圾回收更加积极,这个问题的原因是Lua这一端无法感知一个小小的UserData代表的东西在C#世界的分量,根基都错了只能无脑加快频率,这是最简单有效的办法了,参数合理代价也并不大。
关于撑大Mono的问题,我们应该也有,还没细抠这一块。目前正常操作,Mono峰值20几兆,就先没有管。
关于Lua引用C#,Lua这边只是拿一个索引,真正的对对象的持有是通过ObjectPool来实现的,接下来针对ObjectPool做手脚即可,分两步:
(1)记录调用栈
C#栈可以通过StackTraceUtility.ExtractStackTrace()拿到;
Lua栈可以通过DoString(“return debug.traceback()”)拿到;可以把这两个字符串和obj一起记录在ObjectPool里,这样只要知道是哪个obj泄露了,也就顺便知道是哪里引入的了。
(2)记录分配号
为了查哪个obj泄露了,可以在obj入池的时候给它一个分配号,这个分配号自增,然后我们就可以打点diff了。比如在某一刻打点A,此时的分配号是100,在另一刻打点B,此时的分配号是150,然后一顿各种GC释放,遍历池子找出100到150之间的obj,重点分析这一部分obj的存活是否符合预期,不符合预期的把两个栈打印出来即可。
关于C#引用Lua,这块似乎并不是重灾区,我们封装了LuaBehaviour对外使用,销毁的时候控制好,另外还有delegate也做好控制,其它的暂时没有想到。
感谢littlesome@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5c8b8190276f530b35fdd6cf
Q10:PSS内存优化方法
Q:在UWA测试报告中显示我们项目PSS峰值偏高为1020MB,Reserved为450MB,是两倍多,有什么办法优化PSS吗?
我通过尝试通过adb shell dumpsys meminfo获取memory信息如下:


然后通过Android Device Monitor成功dump Java Heap详情文件hrpof文件,并且成功优化这一部分内存占用。
然而我试图通过DDMS来 dump Native Heap,却没有成功。请教各路神仙有过native heap优化的方案吗?
A:从你的dumpsys meminfo的信息来看,其实内存占用还不算太高;如果说峰值达到了1024MB,那么你就需要观察到底哪一块的内存占用较大。一般而言,这个时候可能你的native已经500MB了。优化native部分,一般有几个方向可以着手。
首先,看看ShaderLab的大小,一般而言PSS显示的部分会比你看到的ShaderLab大一倍以上,比如40MB的ShaderLab,PSS可能就有超100MB了;
其次,观察你的GameObject数量,一般而言减少几千个GameObject,你的PSS可能会减少上百兆;
再者,减少你Mono的占用,这个相信很多人都懂,优化Mono,你的Native也会减少;
再有,就是序列化这一块的东西,当然这个其实跟资源管理相关。
这一块,可以参考下UWA学堂上面的一篇文章《深度剖析PersistentManager.Remapper内存占用》;如果有使用Lua,它有些内存的占用也会在Native这块体现;还有就是从你的Graphics这块来看也相对的偏高一点点,可以看看资源这块是否有优化空间。以上也仅仅是优化内存的一部分,具体的问题可能需要更深入的分析才能了解。
感谢李星@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5d3ac2df70a3811865f79427
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)