
2017年度大赏 | 最受欢迎的十个UWA问答
- 作者:admin
- /
- 时间:2018年02月27日
- /
- 浏览:9842 次
- /
- 分类:厚积薄发
新年伊始,随着大家紧锣密鼓地开始了工作,UWA每周推送的知识型栏目《厚积薄发 | 技术分享》已经伴随大家走过了100个工作周。回顾两年多来,我们分享了近500个和游戏开发、优化相关的精彩问答。这些问答不仅有具象明确的提问,也有详细周全的解答;既能供研发团队自身项目中即学即用,还能通过参与者的回答分析,帮助我们在解决问题的过程中触类旁通、鉴往知来。我们优选了10个开放性的精彩回答,分享给大家。
UWA QQ群:793972859
UWA 问答社区:answer.uwa4d.com
1、如何在项目初期确定美术规范?
在项目初期,没有任何正式美术资源的情况下,如何给出一个美术资源制作的规范给到美术呢?我明白,就上面的策划需求不能得出一个精确的制作规范,只是想要一个大概的推算方式,给出一些大概的参数,好让美术有规范可以参考。不知是否能给些指引?
美术也可以按他们想要的精度先制作部分角色和场景,但只有有限种类的资源的情况下,有方法测算出这个精度在性能允许范围吗?也就是说这个精度满足策划需求,可以作为美术制作规范。例如只有一个角色(5000面,512贴图三张,80根骨骼),策划同屏要求20个,就在场景中摆20个一样的角色进去(因为只有一个),如果目标手机不崩溃,以后角色的制作就按这样做。这样可以验证这个精度吗?
精彩回答1:
作为经历了一个新项目在大家都没经验的情况下做出一个刚小范围内测游戏的苦逼开发者,结合群里讨论,个人觉得以下经验可以参考:
1)选好对标游戏,扒资源来参考。比如畅销榜上的游戏,把资源解出来看,参考模型面数和贴图等游戏。这样最坏的情况下,参考别人能跑上线收到钱的游戏,收钱不保证,但是游戏性能的坑会少很多;
2)所有口头或文档的规范,都是无效的,不可能得到严格遵守,也就是说,不能用程序检测的规范都是空规范,全部做成Editor菜单检查校验;
3)用同一个英雄放20份测同屏的方法是不靠谱的;
4)从gfxbench.com上根据跑分选好基准机型,比如假设要兼容的机型是跑700帧的,那么基准机型得选6000帧的,预留好性能空间,性能别用得太满,否则没回旋余地:
5)贴图少用RGBA32,让美术在做图的时候,做出来一律以压缩模式的纹理来走Unity导真机包来看效果,千万别只是把美术图导手机相册里看效果,这会和真实的游戏效果有所偏差。建议规范只留两张2048*2048的纹理空间给美术发挥,其余全压缩,否则等美术在高画质模式作出效果后不肯降效果,逼程序优化,性能损耗非常大,程序会万分苦逼。
感谢李先生提供了以上回答。
精彩回答2:
这确实是个见仁见智并且取决于项目类型的问题,不过题主是在项目初期,想要快速迭代出策划的设计原型,并且要快速制作并且不用与程序产生过多沟通,在此前提下我觉得设定美术规范的首要目的是:不失控。制作出性能优秀的原型不是前期的目的,但毕竟是项目进展的一部分,如果美术资源制作没有标准规范参考,如果随便一个场景都是几十万面,DrawCall超过300,Overdraw可视化都红得发白,那到后面整个团队都要为此付出时间和精力,甚至返工。所以基本的制作规范也是十分必要的。
其次,在项目前期如何看待优化这个问题呢?我觉得过早的优化也是没有太大意义的,谈优化必须首先定位瓶颈,否则盲目优化除了降低资源质量和运算精度,对项目很难起到正面作用。这时项目处于快速变化中,不适合过早断定,所以在这个阶段依然是保证项目即使没有很优秀的性能,但是也没有很严重的问题,这就已经及格了。到了项目后期优化与效果的博弈,这又是另一个话题了。在以上前提下,假设题主制作的是一个RPG游戏,主城+若干小副本推图,中端手机 iPhone 5,没有程序的太多干预,那么我的建议是:
1)大致规定好项目在 Unity 中的资源组织格式;
2)设定好 3dmax 导出模型的比例标尺,最好与 Unity 大小 1:1;
3)场景总面数均值5-6w左右(大部分),最高10w(少部分),单个模型300-1500面,摄像机可见部分2w以下,导出去除废点,多余的法线(如果没用的话),尽量单面;
4)场景总面数还要看同屏战斗人数多少做调整,Drawcall最好不超过50,一边给角色和特效留下空间,总 Drawcall 不要超过250这个尽量保证;
5)场景物体每个模型一个材质球,贴图256为主,正方形,pot(长宽2的倍数);
6)严格限制场景中透明片的大小和重叠的个数,尽量少用,减少面积;
7)角色面数部分,主角1500以下;特殊boss2000以下;精英怪物1000面以下;普通怪物800面以下;
8)每个角色一个材质,除了特殊部件(翅膀等)一律不使用透明材质;贴图长宽相等,符合pot,128-256为主,最大不超过512;
9)去除 IK 节点和所有不必要的网格,对齐模型中心点与坐标原点;
10)预先规定好角色需要换装的所有节点名称,并且将需要换装的部分规定好并制作时拆开;(建议将脸部单独拆卡,脸部可增加面数);
11)角色骨骼30-35根为主,特殊大boss适当增加,超过40慎重考虑;
12)可以考虑动画帧率10帧每秒,视具体情况或者不限制;
13)粒子单个发射器不超过50,每个特效最好10个粒子以下,同屏不超过500(200太低难以达到),尽量减少材质和粒子种类,大小,面积,层叠数等,粒子真的很费;
14)摄像机一定要调整远近裁剪面,尽量降低远近裁剪面的距离,默认数值过大,也千万不要图方便设置比如 0.1-2000这种,该数值极大影响低端机的深度缓存精度,引起过近的物体穿插闪烁;
15)使用最简单的线性雾,同时善用雾效和摄像机的 culldistant 功能,裁剪掉雾效淹没出的场景部件;
16)可向程序提出贴图导入自动处理工具,比如角色贴图:普通贴图 _D 结尾,法线贴图 _N 结尾,导入时工具自动设置大小和格式;
17)如果某个资源大于5MB,那么要仔细查看是否真的必要;
18)如果成使用工具完成的资源检查和设置,那么都尽量提出需求让程序满足;
19)最好有个人专门负责检查和整理资源;以上只是摘取了一部分影响比较大的提了出来,也有一定的项目类型针对性,请根据自己的项目酌情参考和调整,实际细节还是比较多。另外,美术同学要善用 Unity 已经提供的各种工具,比如:面数, DrawCall,OverDraw 等等,这些都是直接又重要的基础指标,需要随时关注。美术同学也可以一开始不需要非常清楚这些标准背后的含义,尽量地去贯彻执行,久了就慢慢能理解,有空自己多去思考和追究;这些标准可以为少数情况酌情开特例,但不要太多。
感谢Yaukey提供了以上回答。
此问答来自于UWA 问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5941544c18d35e654e3e2373
2、美术资源导入管理
我们每次大批量地合入美术资源时,经常会出现构建出来的版本出现材质引用丢失、Animator Controller引用错误、贴图引用错误等资源引用错误的问题,美术资源在本地是正确的,其他人机器上Editor看也是正确的,构建机Editor看也是正确的,但构建出来的Bundle是坏的。有时删除Bundle再编会解决,有时则不行,目前遇到这种情况,只能让程序同事在构建机上删Meta重新做一次Prefab,费时费力而且不规范。
想问问这是Unity的Bug吗?大家有没有规避或者优化的方法?在管理美术资源合入的时候有没有更好的流程,我们目前使用Perforce管理Unity工程,要求美术显式上传资源配套的Meta文件。
精彩回答:
我根据我们项目遇到过的问题猜测下,我觉得项目资源导入某个地方有问题的可能性更大些,题主是否可能存在以下情况:
1)是否使用代码混淆。在Prefab 上挂的脚本忘记添加到排除混淆的列表,导致序列化的字段被混淆,打完Bundle后的Prefab资源加载时候,挂接的脚本出现引用错误;
2)资源导入都重载过OnPostProcess并处理了资源设置,这一步是否修改了什么不合理的地方,比如破坏了引用关系;
3)打包AssetBundle时,在构建Bundle 之前有没有使用文件操作API(不是 Unity 的AssetDatabase的API)来直接修改了某个文件夹或者其他会破坏引用关系的行为,然后构建Bundle,完成后恢复文件夹名字(或者恢复资源原始状态),这样丢失引用关系的几率很大;
4)有没有可能发布机器上,看着正常,但是Perforce里面已经存在一堆已修改的Meta文件;这种问题常出现于美术本地有两个A1,A2个相同资源在不同文件夹,A1受版本控制,但是由于某种操作,本地临时资源A2使用了原本A1的Guid,原本正确的 A1 被迫使用了不正确的新生成Guid(相当于两人交换),然后上传了A1的Meta,结果发布机器的下来的A1 Meta就会跟别人丢失引用,或者更新下来本地重新分配了新的Guid;美术策划最容易犯这个错误;
5)我们是Unity 5.3.8p2,上周遇到一个疑似bug,美术多上传了一组相同的资源,我们更新下来都会重新生成Guid,但是很多挂起的Meta在Unity里重新导入后,在版本控制里神奇地消失了,但修改还在;
6)如果都不是,只能尝试最小排除法了,删除项目绝大部分资源,一点点增加,然后打包,重现,排除原因;不行的话然后删除代码,一点点添加,打包,重现...有时候笨办法也是最容易接近真相的。
该问题来自UWA问答社区,感谢Yaukey提供了回答,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a0e8184e8a3d9357ce19473
3、Camera开启HDR对移动游戏的影响?
我看到很多炫酷的效果都是用Unity的后处理来实现的,要求Camera开启HDR。但是我不知道开了这个选项会不会很耗,在中低端机上能跑起来吗?另外,使用HDR之后,Camera的Rendering Path是不是不能选Forward?
精彩回答1:
使用HDR可以选Forward,和Rendering Path的选择并不会相互影响。 在手机上单纯开启HDR(fp16)性能的影响并不会很大,各种后处理Pass的开销是要优化的重点。因为一般不会单纯开启HDR而不使用后处理,综合考虑到发热量等因素,不建议低端机器使用HDR和后处理,中高端再开启HDR并配合后处理,并对后处理做基础优化:比如适当降低后处理分辨率,尽量合并多个后处理流程到一个Pass等。
感谢贺甲提供了回答
精彩回答2:
开启HDR本身只是为后处理准备需要的数据,关键在于后处理的效率。假如说的是整个HDR实现的话,占GPU总体时间是一个相当可观的数值,大概可以认为是用带贴图透明片整屏绘制4,5遍左右的量(大概在这个数量级)。如果你只是想做泛光,使用更低质的效果的话,会好很多。
问题是,部分上古机型(诸如我的旧安卓机)本身对unity的后处理不兼容,只要对当前屏幕缓冲做任何操作都会导致卡死,不使用后处理主要是兼容方面的考虑,也就兼带着无法使用HDR了。
但是目前完全可通过兼容性测试来决定特定机型后处理的开关,一刀切的方式并没有必要。但这样又有一个问题:特定后处理提升的画面效果是否对得起它的消耗?是否有其他非后处理的方式可以实现类似的效果而消耗更低?(比如仅仅实现小物体的泛光用透明圆片堆叠效率比正常的Glow效率更高,虽然效果不好),这些也是导致后处理没有广泛使用的一个原因。
所以要看你具体想要实现的效果了。毕竟PSP这种机器末期在机能受限情况下也都在勉强实现后处理泛光效果,说明玩家其实还是有这样的需求的(虽然你拿出这样低质的效果很容易被产品BB糊了不如不加什么的……)
感谢唐翎提供了回答
精彩回答3:
手机上基本都是forward并不影响。不知道5.5.x情况。从5.6.x开始是可以通过设置Tier settings 来调整hdr mode. 有FP16也有R11G11B10格式。这两年手机GPU GFLOPS已经有了飞跃性的提升。附加个数据:比如meta9 一套4-5个后处理下来GPU消耗2-5ms.
感谢蒙占志提供了回答
此问答来自于UWA 问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/59f810692f7f63497e0f6baf
4、如何加快打包速度?
目前我们项目打出来的APK大小在120MB 左右,打一次包平均耗时在20~25分钟。Build过程中绝大部分的耗时在“Building Scene0”和“Building additional assets”这两个阶段。请问这两个阶段Unity具体是在做哪些操作?有没有什么方式可以减少这阶段的耗时?另外如果从硬件层面考虑,如何更有效地提高打包速度?提高硬盘的读写速度和CPU的性能又分别能带来怎样的耗时收益?
精彩回答1:
我们使用的是AssetBundle的方式,目前600MB的包,没有太多资源修改的情况下,安卓包出包大约10分钟左右,之前是7-8分钟,不修改C#代码单独出Patch的话大致在5-7分钟。
我们在用的安卓打包机价格大约是1万左右,多CPU并且保证单核CPU的性能也是尽量高一些,SDD肯定必备,其他的没什么关系。
我们的CPU使用的是:Intel(R)Xeon(R)CPU E5-2683 v3 @ 2.00GHz 2.00 GHz
提醒一下关于贴图压缩,之前我们一直被贴图压缩折磨,高品质实在是太慢,后来我们是区分了Dev和Pub版本,Dev版本本地贴图压缩使用Fast,发布用的Pub版本才用Best的品质,速度快了非常多~即使美术大量修改贴图,Dev版本出包也很快。
感谢贾伟昊提供了上述回答。
精彩回答2:
我很久之前在Github上发现了这个东西:
pvrtextool_wrapper:https://github.com/fxgames/pvrtextool_wrapperUnity打包会调用pvrtextool,通过这个wrapper替换掉原始程序,这样可以在打开发版本时,强制把压缩质量设置到fast模式,这样就可以节约大量的时间,而不需要修改任何贴图的压缩质量参数。如果觉得Mac Pro太贵了,可以试一下这个方法。
感谢lujian提供了上述回答。
精彩回答3:
Building Scene 是Unity在打包场景资源中,Building additional assets 是Unity在打包Resources中的资源,我们项目接近600MB了,每次出包都要50分钟以上,苦不堪言。你可以尝试这样:
1)把资源全部使用AssetBundle的形式。除了第一次,在下次出包的时候,只会打包有变化和增量的资源。因为Resources的每次出版本都会重新打资源。这样可以将没修改的资源打包耗时省下来。
2)配置个好的电脑,把CPU换个好点的,硬盘换成SSD的。以上2点能节省你出包的时间,目前也是我们使用的方法
感谢 hejianchun提供了上述回答。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a7abe4d847802258a06503d
5、如何在PC上检查美术的特效性能?
有没有比较好的办法在PC上检查美术的特效的性能?我们之前做了个粗略的方法,就是扔N多特效在场景里,检查一下帧数,但是效果感觉不是很好,想听听大家的意见。
精彩回答1:
我们是写估分公式,也就是按一定的规则,遍历整个特效,根据节点的属性计算一个性能分。可以批量扫资源输出Excel查看。复用一下代码可以直接植入到编辑器,让美术做的时候就看到这个分。 不用很精准,这种方法90%的问题都可以很快发现。还可以预先定好规范,结合特效的使用情景来估算特效同时出现数*特效性能分会不会超标。
感谢招文勇提供了回答。
精彩回答2:
特效吃性能主要是OverDraw导致的。我们没在PC上检查,是拿真机检查。
PC的检查是用了钱康来提供一个看OverDraw的脚本,美术可以在做特效的时候大概看一下OverDraw,根据情况来调整。然后我们构建真机包的时候生成特效列表名单,然后在进到主城之后,在聊天节目输入GM命令,遍历播放特效,每个特效可以通过播放1到n份,然后通过AdvancedFPSCounter插件记录当时的FPS值,记录到文件里。
然后找出帧率低的时候是哪些特效,然后针对性优化即可。
比如代码
if (cmd.ToLower().StartsWith("-gm texiaoplay3")) { Toast.ShowTip("测试美术做的一系列特效 " + cmd); prEffectTest(3); return true; }
private static void prEffectTest(int efCount)
{
if (BilinCamera.Instance == null || BilinCamera.Instance.player == null)
{
Debug.LogError("找不到场上英雄,因此不能测试特效");
return;
}
TextAsset conf = Resources.Load<TextAsset>("effeclist");
string[] lines = conf.text.Split('\n');
//先同步加载一遍
for (int i = 0; i < lines.Length; ++i)
{
string prefabName = lines[i];
if (string.IsNullOrEmpty(prefabName))
{
continue;
}
}
BLDebug.isLog2FileEnable = true;//开启写文件
GameManager.Instance.StartCoroutine(prEffectTestAsync(lines, efCount));
GameManager.Instance.StartCoroutine(logUsedFPS(efCount));
}
private static IEnumerator logUsedFPS(int efCount)
{
float startTime = Time.realtimeSinceStartup;
float crtTime = Time.realtimeSinceStartup;
while (crtEffectName.Length > 0 && (crtTime - startTime) < 6000.0f)
{//100分钟内
crtTime = Time.realtimeSinceStartup;
CodeStage.AdvancedFPSCounter.AFPSCounter aFPSCounter =
CodeStage.AdvancedFPSCounter.AFPSCounter.AddToScene();
BLDebug.Log2File(TimeUtil.currentSqlTimestamp4LongAdv() + "\tlogUsedFPS" + efCount + "\t" + crtEffectName + "\t" + aFPSCounter.fpsCounter.LastValue + "\t" + aFPSCounter.fpsCounter.LastAverageValue + "\t" + Time.frameCount + "\t" + Time.realtimeSinceStartup);
yield return new WaitForSeconds(0.1f);//每0.1s采样一次fps
}
yield return null;
}
private static string crtEffectName = "notbegin";
private static IEnumerator prEffectTestAsync(string[] lines, int efCount)
{
float periodTime = 5.0f;
//开始逐个播放特效
for (int i = 0; i < lines.Length; ++i)
{
string prefabName = lines[i];
if (string.IsNullOrEmpty(prefabName))
{
continue;
}
crtEffectName = prefabName;
GameObject[] effectGoArr = new GameObject[efCount];
for (int k = 0; k < effectGoArr.Length; k++)
{
GameObject effectGo = PrefabUtil.loadPrefabToGameObject(prefabName, parentGo);
effectGoArr[k] = effectGo;
if (effectGo != null)
{//是ui特效,
GameObject.Destroy(effectGo, periodTime);
}
else {
Debug.LogError("加载失败???" + prefabName);
}
}
yield return new WaitForSeconds(periodTime);
}
crtEffectName = "";
BLDebug.UploadTodayLogFile();//把当天的日志传到服务器
yield return null;
}
把日志导入Excel进行分析即可。
感谢李宗波提供了回答。
精彩回答3:
我们分了两块:
1、特效释放对于整体性能的影响部分,这个是针对结论性的统计,在真机上统计释放之后的帧率波动,目前的版本只做了往场景里扔来记录帧率的功能,主要评定特效对于游戏最终的影响;2、特效的Draw Call、面数和Overdraw影响。这块的统计数据的获取我们目前只能在PC上获取,所以有一个工具在单机版本里逐个播放技能特效,统计对于上述三个指标的评价,找出超标的部分每周周会上给出报告列举出来。
个人感觉资源的检查一定有工具定期来做,持续监控才是最有效的优化方式。
感谢贾伟昊提供了回答。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a3b96e934968145049616fe
6、Graphics API的选择
大家现在在工程里还是选择只使用 OpenGL ES 2.0吗?我记得以前大家都是这么做的,现在这个做法过时了吗?iOS 是否该加上 Metal?
精彩回答1:
我们目前都是用的Auto,主要有两个原因:
- Metal测试下来CPU Overhead会比GLES低很多
- GLES3能够有tex2Dlod支持 兼容性上来说只有实在老的机器和模拟器会fallback到GLES2,可能效果上会略差一些不过我们测试下来都可以接受。
感谢钱康来提供了以上回答
精彩回答2:
我们现在快要上线的项目选的是ES3.0,iOS和Android都是选的这个,iOS选Metal的时候遇到模型显示不正常的问题,但是能力有限加上没时间没定位到原因,就统一成ES3.0了。选ES3.0还有一个原因,就是发现AssetBundle打出来的资源会比选Auto小很多。 还有就是目前我们的游戏偏重度,不指望用老手机的玩家会付费,所以放弃显卡太老的机型了。
感谢李先生提供了以上回答
此问答来自于UWA 问答社区:如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/594ddec949dc1fb06ce0685f
7、多维度材质对效率的影响
在目前的Unity版本中,使用多维材质是否会对效率产生影响,用多维材质和把模型分块哪个更好?
制作美术资源时,应该尽量避免使用多维材质。先举例说明多维材质的一个优点是拆分模型做不到的: 一块大石头有石头和草地两个材质,做成一个整体的模型,使用多维材质,作为一个物件进行烘焙,在Lightmap上的UV分布是一个整体,不会出现拆分为两个模型烘焙产生的接缝问题。
除了上面这种情况,其他情况下推荐将模型拆分成多个模型赋予不同的材质。优点是:
1、多个模型会作为多个MeshObject参与到裁剪、静态批次等优化中;
2、拆分的模型和贴图可以进行材质合并,程序才能进行下一步的优化,如果本身是多维材质,就无法进行合并DrawCall的优化;第一个优点就能带来很大的收益。制作上应该按照一个模型对应一个贴图的做法进行,如果模型是一个整体,比如房子由底座、墙体、屋顶组成,建议将他们多选导出成一个FBX。
另外,不同材质的模型建议做成多个模型,再多选导出成一个FBX,仍然是一个模型对应一个贴图的规范进行制作。

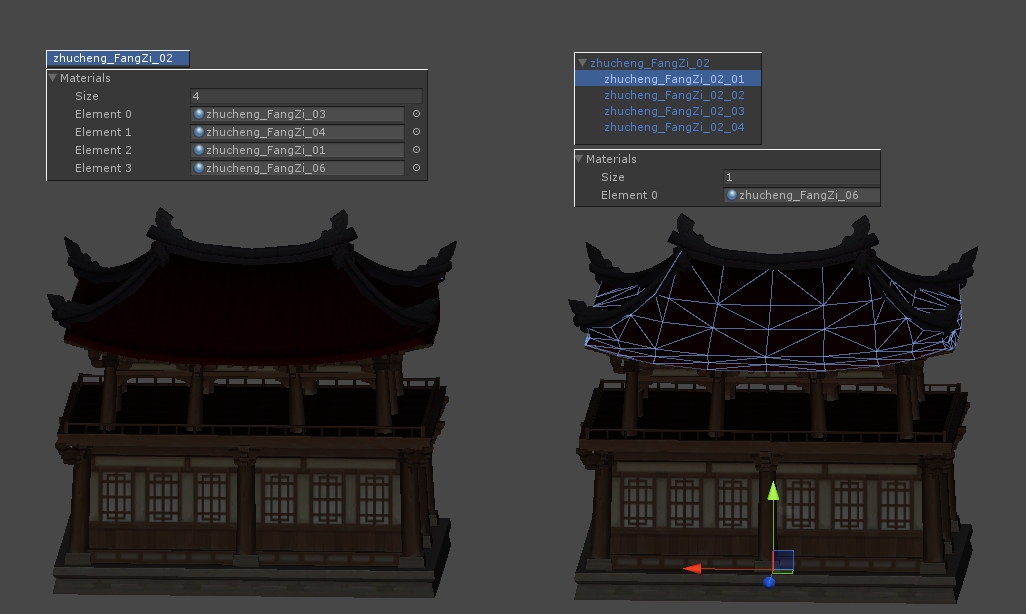

该问题来自UWA问答社区,感谢文雅提供了回答,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/59e890dbe02a95cc6d0c4987
8、AssetBundle粒度规划
关于AssetBundle(下称“AB”)拆分粒度问题。在我的项目中,我是基于逻辑以及最终的打包大小来分的,比如尽量不让压缩后的AB包超过1MB, 这是UWA之前的推荐,同时也是因为当前版本Android包的SerializedFile占用大小(https://blog.uwa4d.com/archives/TechSharing_56.html)所考虑。经过这样的规划之后,我打包这块的代码基本是写死的, 包括手动把公共包拆成多个(公共包略大,不拆的话压缩后会有6、7MB), 还有每个AB包的内容也是人为拆成多个。 这样虽然最后功能实现了,但个人依旧觉得不够自动化。每次新添加资源的时候, 都得走一遍这种手动流程。也研究了别人写的开源方案(https://github.com/tangzx/ABSystem),全自动分析依赖关系,但问题是最后包打得实在太细了,不太符合科学(但还是推荐大家学习)。所以就想问下各位的公司项目是如何解决这个AB 粒度划分问题的?
精彩回答1:
这是一个相当开放的问题,仁者见仁,智者见智。UWA目前无法总结出一个统一的方式来建议如何进行打包,首先需要说明我们看到的两点情况:
1)没有最好的打包方式,只有最适合项目需求的打包方式;
2)无论是粗粒度打包还是细粒度打包,现在都有成功的项目在采用,这说明只要符合需求,两种打包方式都是很好的。
接下来,我们就粒度问题给出一些我们的看法:1)AB粒度建议不宜过细,特别是一个资源一个AB
粒度过细,一方面会导致加载IO次数过多,从而增大了硬件设备耗能和发热的压力;另一方面,在我们测试过的Unity 5.3 ~ 5.5 版本中,Android平台上在不Unload的情况下,每个AB的加载,其每个文件的SerializedFile内存占用均为512KB(远高于其他平台),所以当内存中贮存了大量AB时,其SerializedFile的内存占用将会非常巨大。同时,需要进一步说明的是,该问题已在Unity5.6中进行完善。2) 在Unity 5.3版本之后,对于AB文件的文件大小其实不必再限定于1MB之内
之前UWA有这一限定是出于两方面的考虑:一是New WWW在Unity 5.3之前是使用最为频繁的AB加载方式(虽然现在也是),在5.3版本之前,New WWW加载会形成一个比较大的WebStream,一般来说是压缩AB的4~5倍,会占用比较高的内存;另一方面,当AB较大(比如大于5MB)时,其加载开销会很大,由于是子线程中运行,所以真正反映到Profiler中时,大家会看到的一个“诡异”的CPU高开销——Graphics.PresentAndSync,具体原因可以看这里( 扒一扒Profiler中这几个“占坑鬼” )。所以,我们对此做了一些实验,发现将AB压在1MB以下是一个加载比较可以接受的情况。以上是我们之前为什么会提出1MB的主要原因。但Unity5.3之后,随着LZ4的引入,很多情况已经变化了,基于其Chunk的加载特点,AB加载很快,且内存占用要比之前小很多。所以LZ4的AB其实可以考虑更加粗粒度一些。但是,这里仍然有以下三点注意:
1)对于需要热更新的AB,也如问答中其他朋友的所言,要考虑实际情况控制AB的大小;
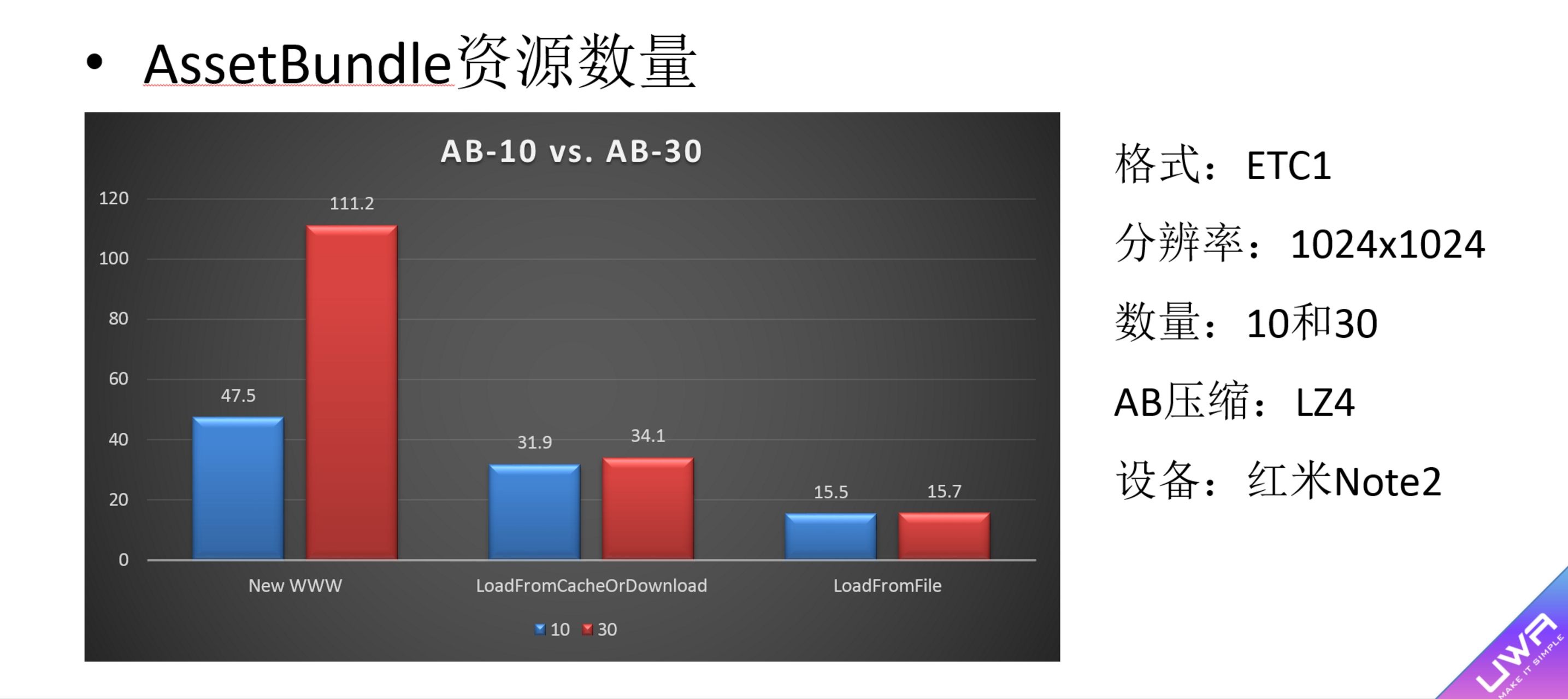
2)即便是LZ4的AB,其加载方式不同,加载效率也可能完全不一致。以下是我们在UWA DAY 2017的分享,我们在两个不同的AB(LZ4格式)中都加载同一个资源,唯一不同的是一个AB包含10个Asset,而另一个AB包含30个资源,以下是三种不同方式从加载AB到AB.Load的耗时对比。可以看出,New WWW加载出现了明显的时间差异。因此,在Unity5.3之后,尽可能建议通过LoadFromFile(Async)来对AB进行加载。
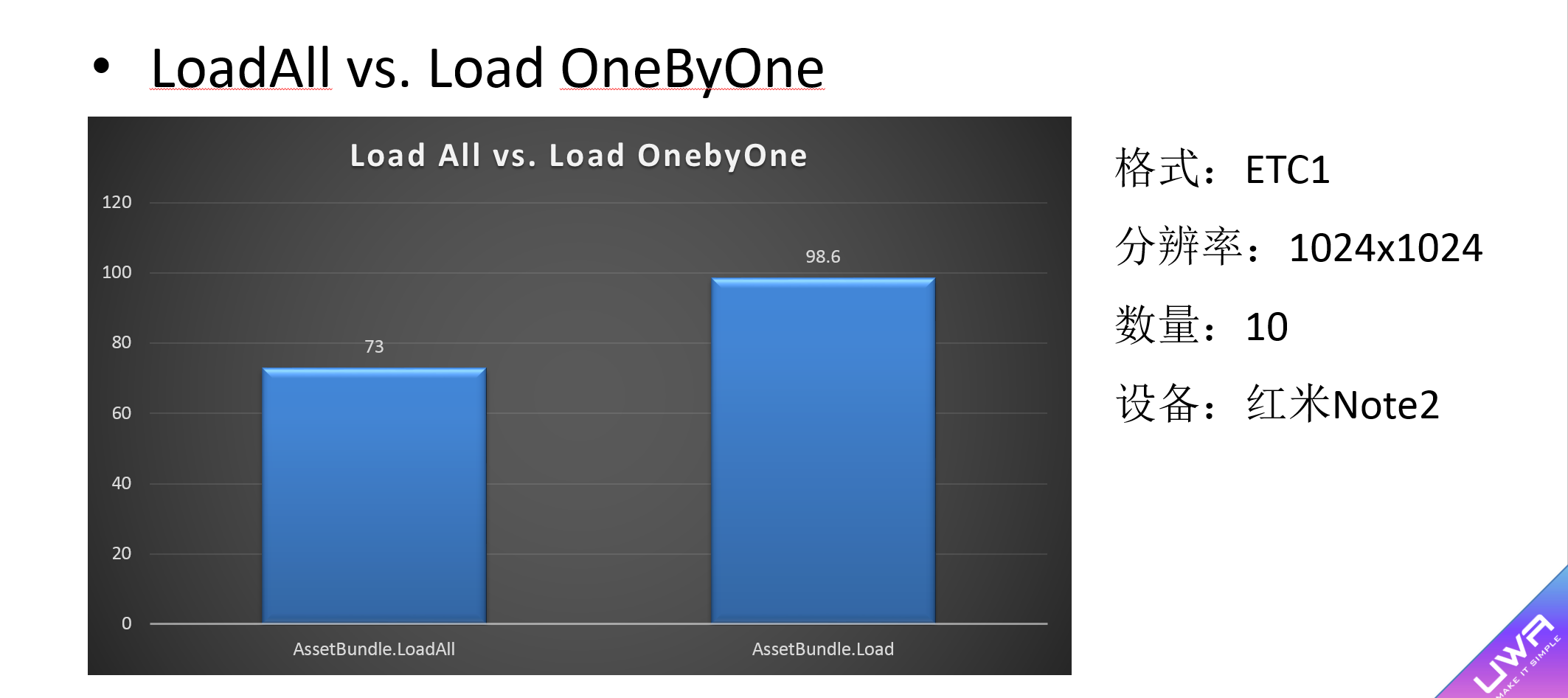
3)对于AB的打包,尽可能把逻辑上同时出现(一个Prefab中非Share的Asset)、小而细碎的资源(Shader、Material、粒子系统等)尽可能打包在一起,并通过LoadAll来进行加载,因为这样会带来更好的加载效率。下图为LoadAll和Load One By One的性能对比。在我们做过的实验中,LoadAll确实会带来更好的性能开销。
上述是我们建议研发团队在AB打包时的一些注意点,希望对大家的项目优化有所帮助。
此问答来自于UWA 问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/58e5bd96e042a5c92c3484ec
9、优化数据表的加载
安卓客户端存在大量的模板数据需要配置,其中一些模板表甚至可能达到万级的数据条目,那么怎么对这些数据模板表进行打包和加载,可以兼顾加载速度和热更新表结构?目前的方案是采用Protobuf代替ScriptableObject进行序列化,可以实现热更新模板表结构,但是加载速度相对ScriptableObject有较大的差距,目前数据模板加载较慢便导致了玩家进入世界的时间比较久。因此想了解大家有什么好的建议呢?
精彩回答1:
本地读取数据表是个老话题了。我不能完全解答这个问题,只能提供一下我过去项目的浅显的经验。用ScriptableObject或者BinaryFormatter二进制存储然后反序列化成保存数据结构的对象,这两种方法应该是加载速度最快的。
我们实际没有采取这个方案,也使用的是Protobuf,是出于以下考虑:
- 一份二进制数据,客户端和服务器可以通用。从服务器推数据很方便;
- 策划习惯使用Excel编辑,有脚本可以把表格内容导出成Protobuf的二进制数据,另外,还有.cs/.go表结构描述文件需要重点考虑。也就是说,策划修改表结构、增减表,服务器和客户端的结构描述文件可以自动生成好;
实际用下来,确实会有一些差距。如何选择还是要看表格的体量了。感谢WangLiang 提供了以上回答。
精彩回答2:
我先把问题拆分一下,题主遇到的问题如下:
第一个问题:配置表存储格式
现在主流的数据存储基本分为三大类,各有优劣,需要根据实际情况选择:
1、ProtoBuf或类似序列化库,这种方式兼容性高,但是加载速度一般;
2、自己实现二进制数据存储,兼容性差,需要精心设计达到较高的数据表达能力;
3、采用Lua热更新方案的游戏,普遍直接把数据存储为Lua表。第二个问题:配置表数据与代码兼容
一般不建议大量修改数据结构,比如增删字段,如果实在无法避免,需要代码连同数据一起发布进行热更,做好版本管理即可。第三个问题:配置读取速度优化
1)先从数据量上约减,减小数据冗余重复,数据存储设计优化,多次引用的字段多引用等等;
2)采用多线程加载,避免使用Unity提供的API,在游戏启动时,并行加载配置表,充分利用多核优势;
3)就我们自己项目而言,没有使用Lua的更新方案,但是我们依然采用Lua作为了数据存储,经过优化后加载速度也不错,可以参考 LuaTableOptimizer。感谢Lujian提供了以上回答。
如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5981c5c5c08748f866b5ebe2
10、Unreal 4 Shadow Map Cache
我想问下Unreal 4的 Movable光源的Shadow Map Cache问题,它的具体更新策略是什么样的呢?如何处理动态物体与静态物体的关系?需不需要对Shadow Map进行Cascade?
我同时也参考了Cry Engine的文档:
http://docs.cryengine.com/display/SDKDOC2/Cached+Shadows
同时如果想移植到Unity,可行吗?或者我想解决大面积实时阴影的问题(光源方向会变化,大部分物体是动态物体 但是频率都不高)有什么解决方案吗?我可以在光源Space下预烘焙数据来达到光源方向变化,用一张Shadow Map的可能性吗?类似 Directional Light Map那种建立空间的?
精彩回答1:
Unreal 4的这个Movable Light的Shadow Map Cache只能给Static、Stationary物体用,因此我觉得其实是想给Movable光照下的Static物体阴影计算做个优化。但是Mobile端没必要用Movable,Stationary就好,Static物体的阴影是预计算的。
Unreal 4的动态物体在计算阴影的时候会计算两次,一次是从静态场景投射到动态物体,一次是动态物体投射到静态场景。在计算静态场景投射到动态物体阴影时,引擎会缓存一张静态场景的Shadow Map,用于计算投射到动态物体上的阴影。因此,对于动态物体也能接收到来自静态场景的精确阴影遮挡,但是这个方式比较耗时,而且mobile也不支持。
Unreal 4也提供了类似Unity的对静态场景投射到动态物体阴影近似解决方案,也是将shadow的预计算结果存储到带有间接光信息(也是SH)的点云(在Unity中就是light probe)中,然后根据动态物体的位置从点云插值出阴影遮挡,但是这种方式只能得到物体整体明暗度的变化,无法计算精确阴影。Unreal 4是推荐mobile上使用后面一种方法的。
需要补充一下的是,Unity解决动态物体接受静态物体烘焙阴影也是采用Light Probe的。题主说是动态光源,动态物体,最好还是实时阴影计算。如果是采用Shadow Map Cache的方案做优化,可能得看具体场景和需求。预计算烘焙多个Shadow Map的方案可能需要考虑两个因素,一是光源变化,二是动态物体变化。如果动态物体和光源变化频率都不高,那么可以尝试对它们采样预计算好Shadow Map。但是这样带来的Shadow Map占用空间和内存开销我们也不清楚,可能得尝试一下才知道。
以上回答由UWA提供。
精彩回答2:
关于Unreal 4的实现,楼上已经说得很详细了,可以参考Unreal 4源码ShadowSetup.cpp/ShadowDepthRendering.cpp,搜索SDCM_StaticPrimitivesOnly相关的代码即可,我补充一下其他问题:
1)针对动静物体怎么处理 在手机上比较难完美,可以针对静物渲染一张SM,动态物件用planar shadow解决2)Shadow Map Cascade 缓存的话,Shadow Map不能随时更新,如果镜头频繁大距离移动,cascade不能跟随镜头随时更新,过度可能会不自然,这需要根据项目特性权衡
3)能不能光源动,Shadow Map用同一张 看你怎么动,如果是模拟日光,轻微转角,那你只能放弃精确阴影计算,在判断某个空间点是否在阴影区时增加偏转角,相当于把阴影做平行四边形变形 如果想360度转,目前我也没有很好的思路能兼顾cache和平滑转动时的过度,毕竟物体的四面都长得不一样,不可能用一张shadow map做平行四边形变形而不穿帮。
感谢招文勇提供了回答。
该问题来自UWA问答社区,如您对该问题仍有疑问,可以转至社区进行进一步交流。
https://answer.uwa4d.com/question/5a0e6dc2e8a3d9357ce1946d



