
技术分享连载(一百)
- 作者:admin
- /
- 时间:2018年02月24日
- /
- 浏览:6414 次
- /
- 分类:厚积薄发
本期聚集话题:Texture2DArray、远距离物体的物理模拟、粒子系统的CPU/GPU开销、如何读取StreamingAssets目录下的压缩包...
新年伊始,随着大家紧锣密鼓地开始了工作,UWA每周推送的知识型栏目《厚积薄发 | 技术分享》在节后的首个工作日迎来了第100篇!今天,我们继续为大家精选了5个和开发、优化相关的问题,建议阅读时间15分钟,认真读完必有收获。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。
UWA QQ群:793972859
UWA 问答社区:answer.uwa4d.com
粒子系统
Q1:请问粒子系统的消耗如何区分呢?哪部分是在CPU哪部分在GPU呢?一个空粒子(禁用所有模块,包括Render)会有消耗吗?如果有消耗,会体现在哪部分呢?
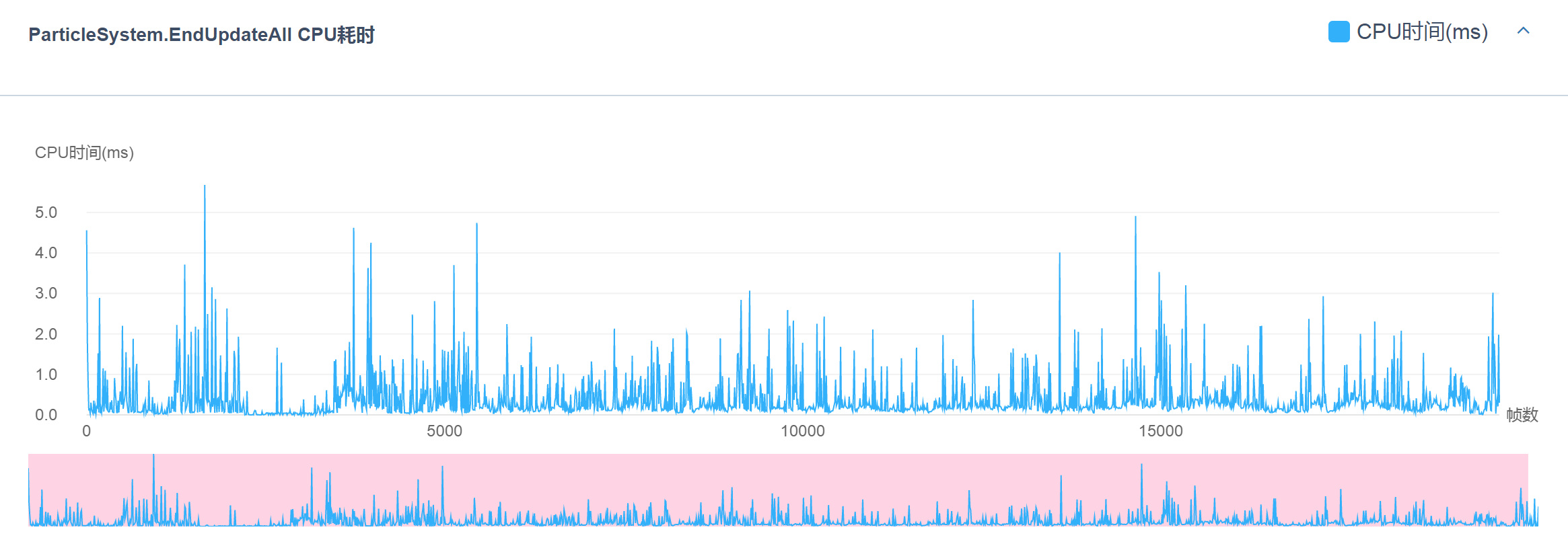
就目前的Unity引擎的原生功能而言,粒子系统中的状态更新(粒子的位置、朝向、触发事件等)均为CPU端开销,具体表现在ParticleSystem.Update和ParticleSystem.EndUpdateAll等函数中。具体可以查看UWA性能报告中的这两张图:
相关链接
相关链接
同时,粒子系统在渲染时也需要在CPU端进行准备,比如粒子系统的Culling和Draw Call操作等等,这些也都属于CPU端开销,如下图所示。
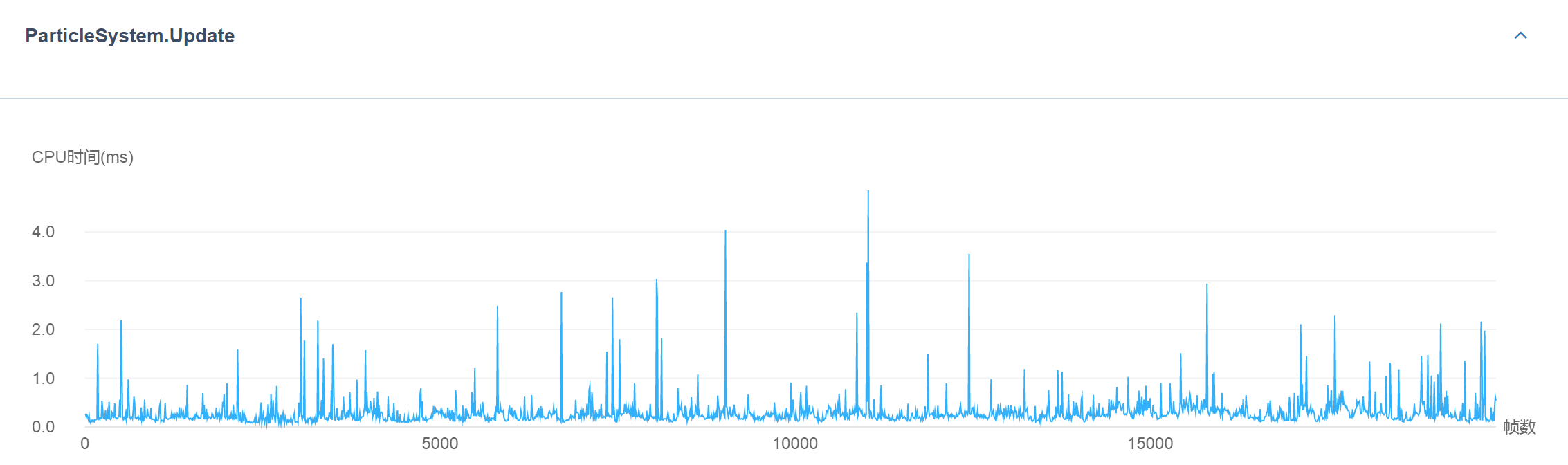

而GPU端的耗时则与其他Mesh渲染无差,主要和ALU、Bandwidth和Overdraw相关。但与其他一般场景渲染不同的是,粒子系统在GPU端的压力往往在Overdraw中进行体现,如下图所示:
上图来自《极无双》的性能详细报告,大家可以参考完整数据来加深这部分的理解:
一个空粒子其自身开销理论上很小,但UWA这边暂时没有做过测试,题主可自行做一些测试,绝知此事要躬行。

此问答来自于UWA 问答社区,如您对该问题仍有疑问,欢迎转至社区进行进一步交流。
资源管理
Q2:我用的是Unity 5.5 版本,由于项目采用LZ4格式的AssetBundle,如果直接放进StreamingAssets下,包就太大了。现在想把所有的AssetBundle打成一个压缩包,再放进StreamingAssets,让玩家在第一次安装时,拷贝到PersistentDataPath目录下再解压。但目前不知道怎么读取Android平台下的StreamingAssets目录下的压缩包,希望能得到指导,感谢!
我们是直接使用的C实现的unzip库,启动游戏的时候就常驻打开Apk,后面都直接通过unzip库解需要的文件到缓存目录来读取,读完了,不用就定期做一些清理。
感谢Lujian提供了以上回答
在Unity的API里应该就只有WWW(新版本里对应UnityWebRequest)能访问非Bundle文件了,但这个接口是异步的,另外.bytes操作会产生较高的堆内存分配,容易撑高堆内存峰值。所以,有的做法是通过Android的Java API来读取,可以参考下雨松MOMO的这篇文章里用的Java接口:https://www.tuicool.com/articles/fAnYJ3I
此问答来自于UWA 问答社区,如您对该问题仍有疑问,欢迎转至社区进行进一步交流。
资源管理
Q3:我用的是Unity 2017.2f版本,我们Prefab里Image元素直接引用的是Sprite Atlas文件夹里的图片,现在把Prefab和Sprite Atlas分别打到两个不同的AssetBundle里,并且去掉了Sprite Atlas的include build的选项。拿工具查看Prefab和Sprite Atlas的Bundle发现,Prefab所在的Bundle会把Image元素引用的那张Sprite图也打进来,而Sprite Atlas所在的Bundle里不但包括了这个Atlas图,并且原图都在这个Bundle里。这是为什么呢?
UWA测试发现Unity 2017.2和2017.3都存在题主说的问题,不过也都能通过一些操作绕过这个问题。先说一下个人认为正常的现象:
include in build不应该影响Bundle的打包行为,且Prefab的Bundle中始终不应该有SpriteAtlas存在。但是如果不开启include in build,正常加载完两个Bundle,且实例化Prefab后,Sprite不会显示,因为需要做一下late binding。
接下来说一下碰到的这个Bug:
- 如果在第一次(打之前清空Bundle目录)打Bundle时,include in build开启了,那么atlas会被打包进prefab的bundle中(即题主的问题);
- 但如果在第一次打Bundle时,include in build没开启,那么就是正常现象(Atlas不在prefab的Bundle中);
有意思的是,在第二次打Bundle时,不论include in build有没有开,结果都和上一次打包一样。所以,绕过去的方法是:
先清空Bundle目录,关闭include in build打一次Bundle;再开启include in build打第二次。得到的结果就是Atlas不在Prefab的Bundle里,同时Atlas的include in build是开启状态的。
题主可以按这个步骤做个尝试。
此问答来自于UWA 问答社区,如您对该问题仍有疑问,欢迎转至社区进行进一步交流。
渲染
Q4:我从文档上来看,GLES3 Metal 已经可以支持了。最容易想到的就是地形的splat层,如果是四层splat,那么就可以用一个Texture2DArray来代替,好处是减少了bind消耗。相关的知乎链接,其中根据龚大的意思来看,似乎还可以减少splat采样次数,但根据自己的测试和理解来看并不行,因为Texture2DArray 的slice之间并不会 blending,不知是不是我理解问题。
我使用一个Texture2DArray来代替4层的Splat地形,从XCode上看开销,并没有任何的减小,那目前来看这么做地形的意义就不是很大了。AssetStore上有一个插件叫MegaSplat就是使用Texture2DArray来达到很多层混合。目前想到的Texture2DArray还有一个可以利用的地方是场景贴图。比如场景用到了多张1024的贴图,或者多张lightmap,原来由于贴图不同导致StaticBatching无法合并,现在就可以使用Texture2DArray来做了。还有比如UI上的icon之类的,可以合并到一个Texture2DArray来达到DrawCall的合并。
目前Texture2DArray最不利的地方是:只能通过代码来创建,没有编辑器的支持。如果要离线制作Texture2DArray,就需要为不同的平台准备多份资源了。请问大家有没有Texture2DArray的经验可以分享呢?
UWA研究了Texture2DArray,看起来它是将多个2D的Texture组合起来变成一个对象,所以在使用的时候只需要绑定一次,就可以采样多个2D Texture。的确如题主所说,采样的时候还是一次只能采样一个指定的slice,blend也需要另外的Shader代码来完成。
题主说了:其中根据龚大的意思来看,似乎还可以减少splat采样次数,但根据自己的测试和理解来看并不行
我感觉他的意思可能是:并不是每次采样必须把所有的slice都采了,而是可以只采其中一部分。估计原本想表达的是一次采样只采一个slice。
我使用一个Texture2DArray来代替4层的Splat地形,从xcode上看开销,并没有任何的减小,那目前来看这么做地形的意义就不是很大了。
如果单从性能上看,Texture2DArray比Texture2D的确只是减少纹理绑定的开销,然后在游戏引擎中可能会对合批产生影响。其他的做法跟普通Texture2D是一样的。Texture2DArray比Texture3D在LOD处理上不同,Texture3D会减少slice,这并不是渲染Terrain时想要的。然后Texture2DArray在filter的时候只会在U,V上做,而Texture3D还会在d上做,所以这部分Texture2DArray也比Texture3D性能更好。综合这些因素可能是推荐渲染Terrain使用Texture2DArray的原因吧。题主通过实验说明Texture2DArray渲染地形没有减少开销,也有可能是因为一般一个场景就一个地形,从绑4张纹理变成绑1张就少了几毫秒,而且也不是每帧都绑,所以从整体效果上看不大出来。
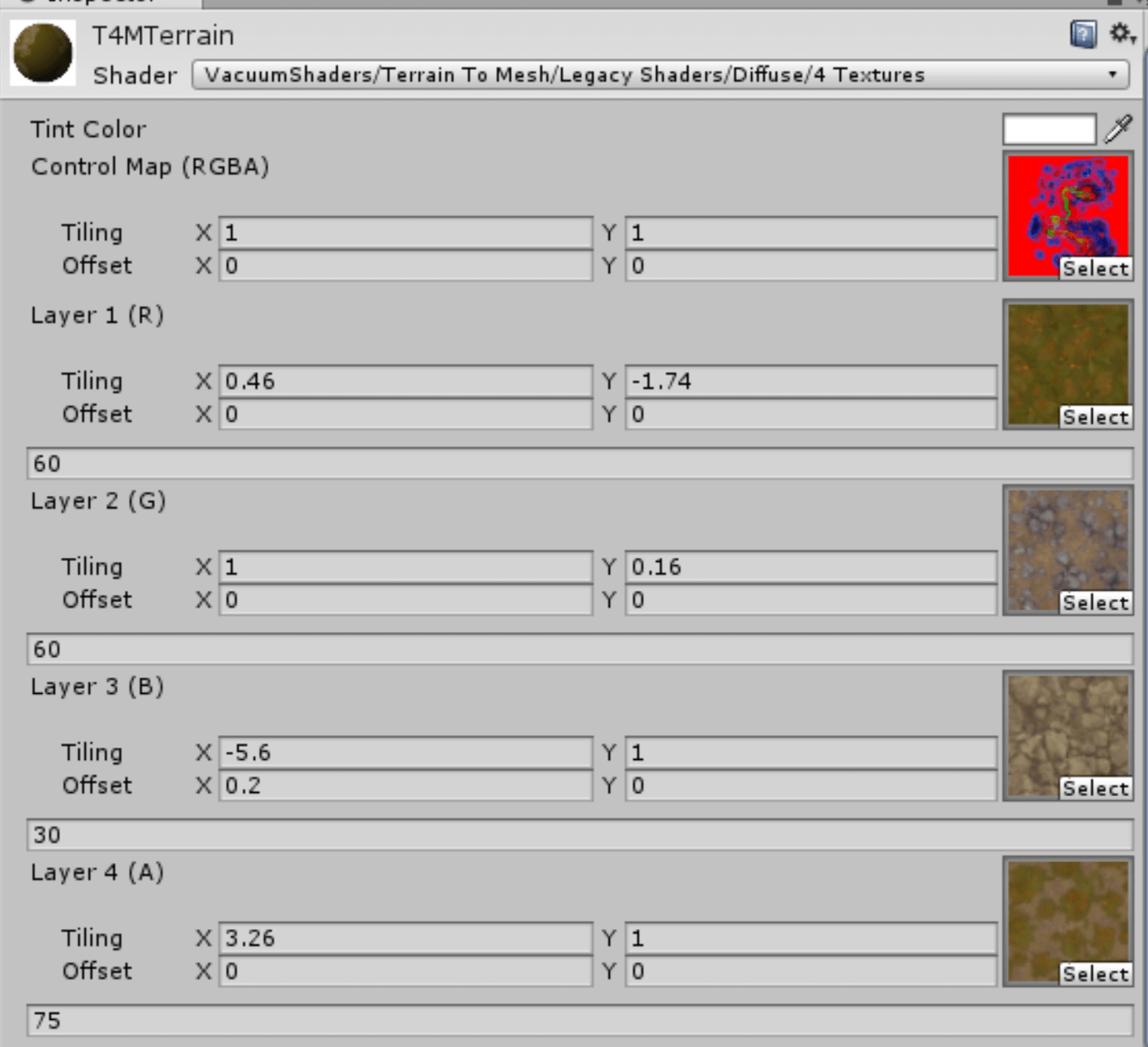
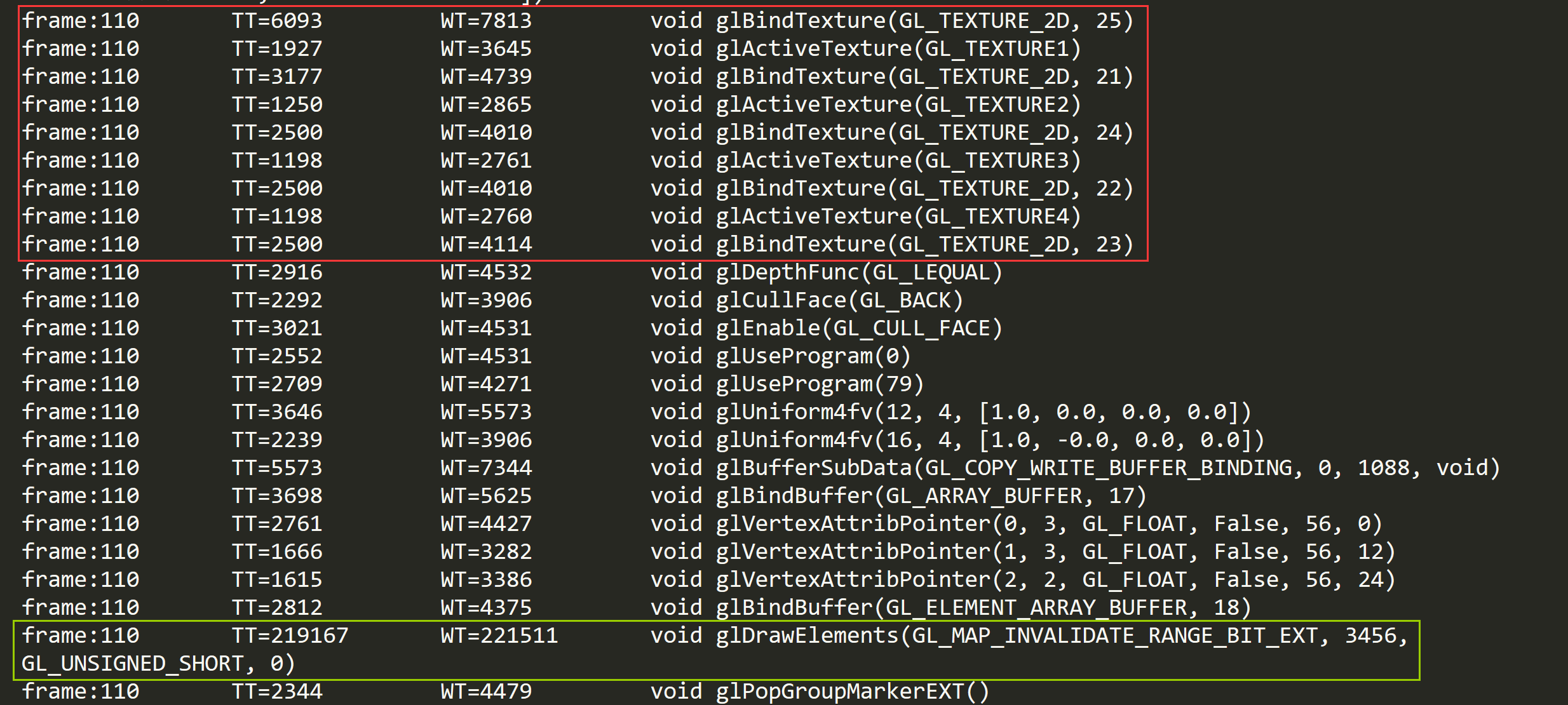
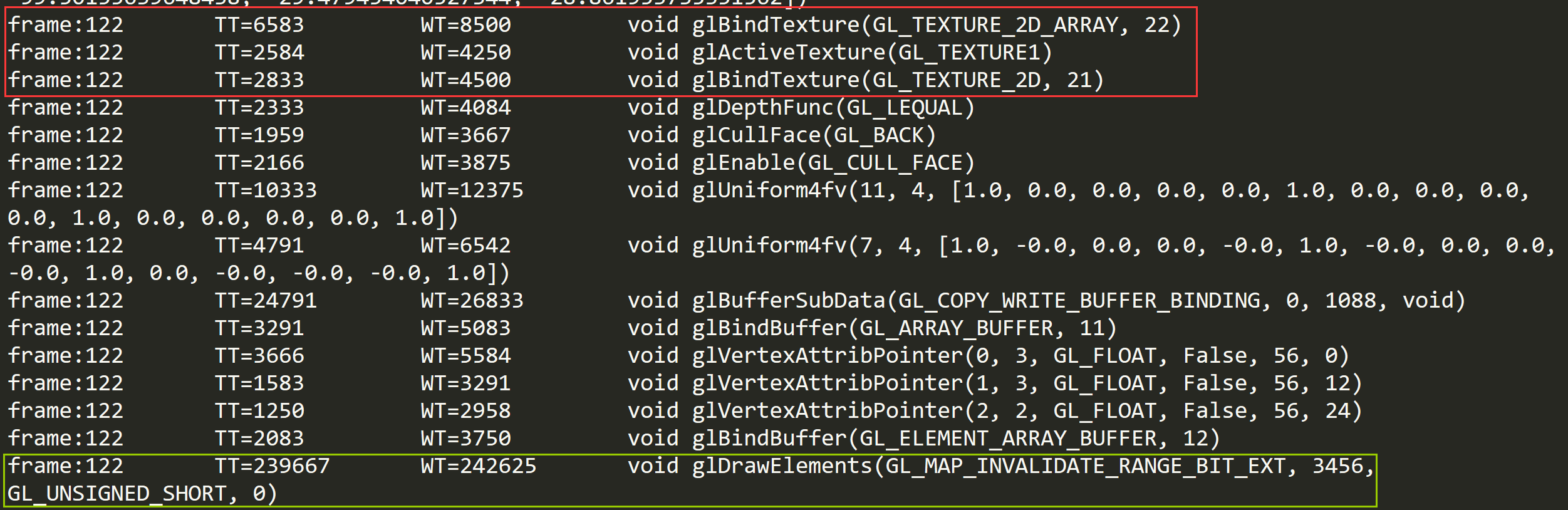
UWA做了个简单实验验证了一下,下图分别是用Texture2D和Texture2DArray渲染地形结果和GLES API调用。实验设备为三星S6。
Texture2D:

Texture2DArray:
其中,GLES API调用图中红色框表示纹理绑定的API调用,绿色框表示渲染API调用。WT表示了该API调用的耗时,单位为纳秒。从Texture2D图中可知一共有5次纹理绑定,分别对应于材质中的5张纹理绑定,而Texture2DArray图中只有两次调用,分别是splat纹理和四层混合纹理的绑定。从图中可知一次glBindTexture的耗时大约为1000~10000ns,即最多0.01ms。因此,三次glBindTexture加上三次glActiveTexture也最多0.06ms。所以看不出来。
此问答来自于UWA 问答社区,如您对该问题仍有疑问,欢迎转至社区进行进一步交流。
物理
Q5:我们正在开发一款超大地形的MMO游戏,场景中的角色或者怪物较多,请问Unity引擎是否会对远处(500m或1km外)的GameObject进行物理模拟?是否有设置可以降低这部分GameObject的物理模拟开销?
Unity引擎确实会对远处的GameObject进行物理计算,只要该物体是Active、挂载Rigidbody(Character Controller)组件并且没有Sleeping的。Unity引擎并没有原生功能可以根据距离的远近来调整物理系统的计算,不过题主可以自行来进行控制,比如通过Culling Group或者自行计算GameObject的远近来控制Rigidbody组件的Active和Deactive,从而降低整体的物理系统耗时。
此问答来自于UWA 问答社区,如您对该问题仍有疑问,欢迎转至社区进行进一步交流。
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
官方技术QQ群:793972859(仅限技术交流)




Good! More!